 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023



We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
Voice Conversion With Just Nearest Neighbors
May 30, 2023


Any-to-any voice conversion aims to transform source speech into a target voice with just a few examples of the target speaker as a reference. Recent methods produce convincing conversions, but at the cost of increased complexity -- making results difficult to reproduce and build on. Instead, we keep it simple. We propose k-nearest neighbors voice conversion (kNN-VC): a straightforward yet effective method for any-to-any conversion. First, we extract self-supervised representations of the source and reference speech. To convert to the target speaker, we replace each frame of the source representation with its nearest neighbor in the reference. Finally, a pretrained vocoder synthesizes audio from the converted representation. Objective and subjective evaluations show that kNN-VC improves speaker similarity with similar intelligibility scores to existing methods. Code, samples, trained models: https://bshall.github.io/knn-vc
Visually grounded few-shot word acquisition with fewer shots
May 25, 2023



We propose a visually grounded speech model that acquires new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelled speech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than any existing approach.
Mitigating Catastrophic Forgetting for Few-Shot Spoken Word Classification Through Meta-Learning
May 22, 2023We consider the problem of few-shot spoken word classification in a setting where a model is incrementally introduced to new word classes. This would occur in a user-defined keyword system where new words can be added as the system is used. In such a continual learning scenario, a model might start to misclassify earlier words as newer classes are added, i.e. catastrophic forgetting. To address this, we propose an extension to model-agnostic meta-learning (MAML): each inner learning loop, where a model "learns how to learn'' new classes, ends with a single gradient update using stored templates from all the classes that the model has already seen (one template per class). We compare this method to OML (another extension of MAML) in few-shot isolated-word classification experiments on Google Commands and FACC. Our method consistently outperforms OML in experiments where the number of shots and the final number of classes are varied.
TransFusion: Transcribing Speech with Multinomial Diffusion
Oct 14, 2022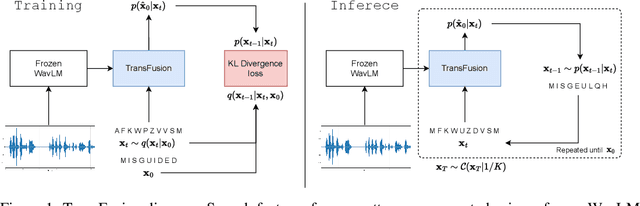
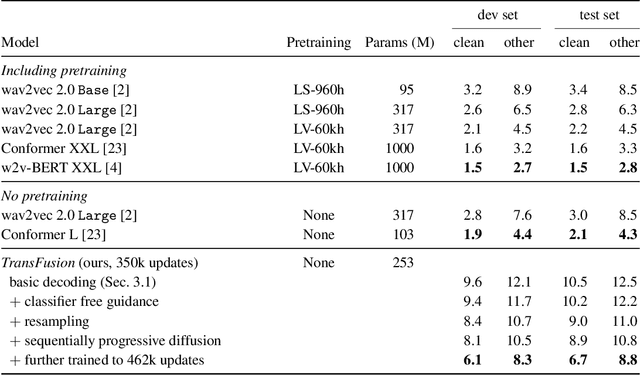
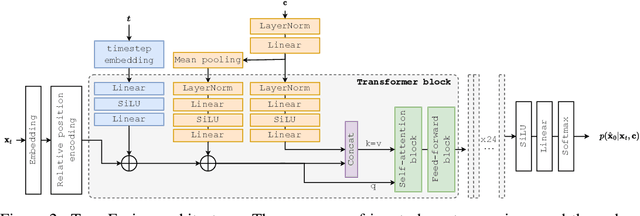
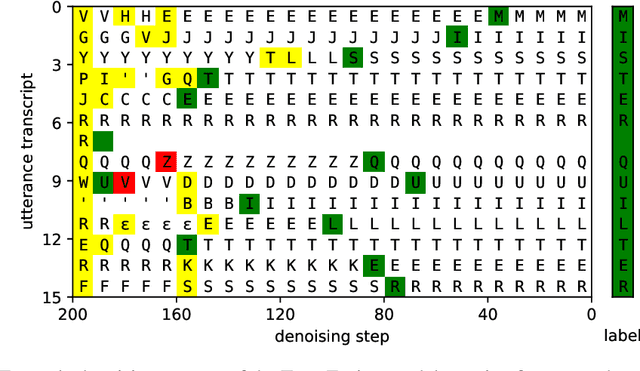
Diffusion models have shown exceptional scaling properties in the image synthesis domain, and initial attempts have shown similar benefits for applying diffusion to unconditional text synthesis. Denoising diffusion models attempt to iteratively refine a sampled noise signal until it resembles a coherent signal (such as an image or written sentence). In this work we aim to see whether the benefits of diffusion models can also be realized for speech recognition. To this end, we propose a new way to perform speech recognition using a diffusion model conditioned on pretrained speech features. Specifically, we propose TransFusion: a transcribing diffusion model which iteratively denoises a random character sequence into coherent text corresponding to the transcript of a conditioning utterance. We demonstrate comparable performance to existing high-performing contrastive models on the LibriSpeech speech recognition benchmark. To the best of our knowledge, we are the first to apply denoising diffusion to speech recognition. We also propose new techniques for effectively sampling and decoding multinomial diffusion models. These are required because traditional methods of sampling from acoustic models are not possible with our new discrete diffusion approach. Code and trained models are available: https://github.com/RF5/transfusion-asr
YFACC: A Yorùbá speech-image dataset for cross-lingual keyword localisation through visual grounding
Oct 12, 2022

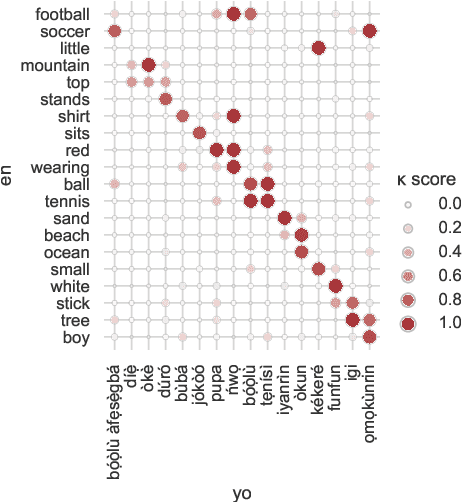

Visually grounded speech (VGS) models are trained on images paired with unlabelled spoken captions. Such models could be used to build speech systems in settings where it is impossible to get labelled data, e.g. for documenting unwritten languages. However, most VGS studies are in English or other high-resource languages. This paper attempts to address this shortcoming. We collect and release a new single-speaker dataset of audio captions for 6k Flickr images in Yor\`ub\'a -- a real low-resource language spoken in Nigeria. We train an attention-based VGS model where images are automatically tagged with English visual labels and paired with Yor\`ub\'a utterances. This enables cross-lingual keyword localisation: a written English query is detected and located in Yor\`ub\'a speech. To quantify the effect of the smaller dataset, we compare to English systems trained on similar and more data. We hope that this new dataset will stimulate research in the use of VGS models for real low-resource languages.
Towards visually prompted keyword localisation for zero-resource spoken languages
Oct 12, 2022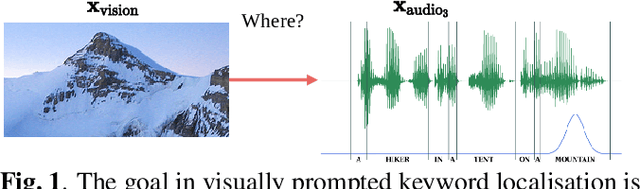
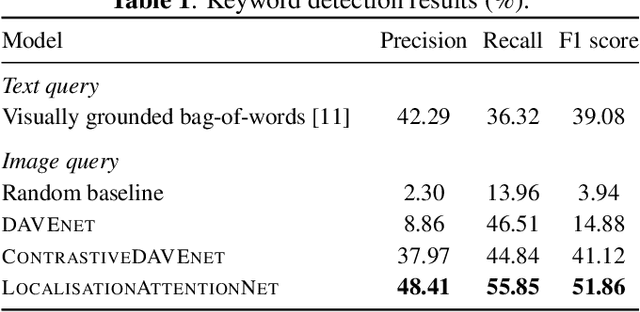
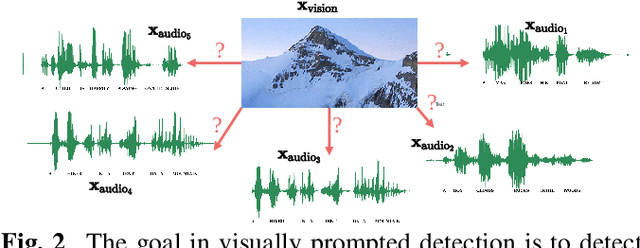
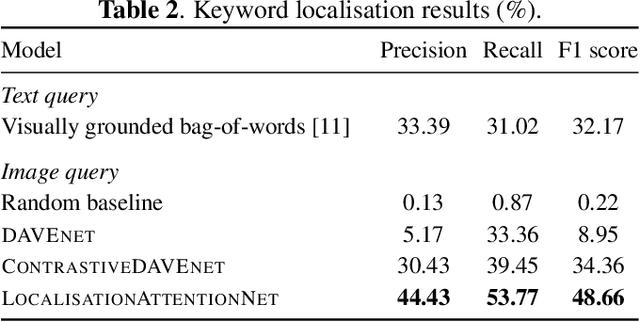
Imagine being able to show a system a visual depiction of a keyword and finding spoken utterances that contain this keyword from a zero-resource speech corpus. We formalise this task and call it visually prompted keyword localisation (VPKL): given an image of a keyword, detect and predict where in an utterance the keyword occurs. To do VPKL, we propose a speech-vision model with a novel localising attention mechanism which we train with a new keyword sampling scheme. We show that these innovations give improvements in VPKL over an existing speech-vision model. We also compare to a visual bag-of-words (BoW) model where images are automatically tagged with visual labels and paired with unlabelled speech. Although this visual BoW can be queried directly with a written keyword (while our's takes image queries), our new model still outperforms the visual BoW in both detection and localisation, giving a 16% relative improvement in localisation F1.
GAN You Hear Me? Reclaiming Unconditional Speech Synthesis from Diffusion Models
Oct 11, 2022
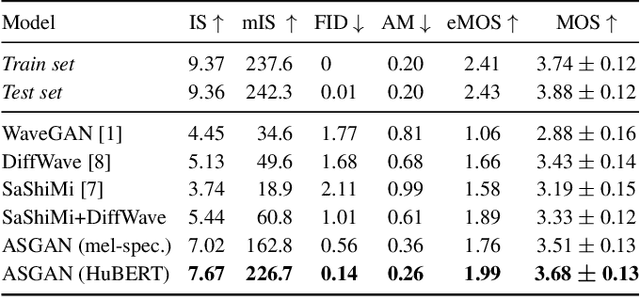
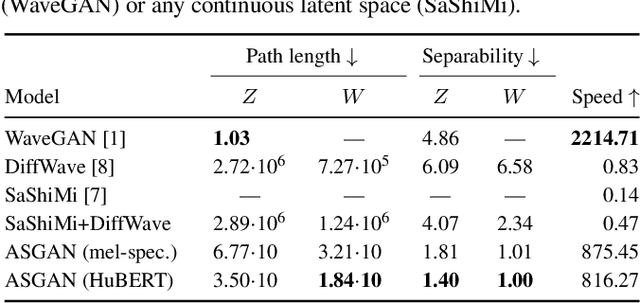
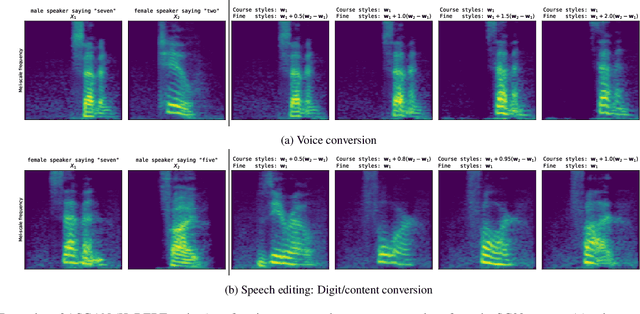
We propose AudioStyleGAN (ASGAN), a new generative adversarial network (GAN) for unconditional speech synthesis. As in the StyleGAN family of image synthesis models, ASGAN maps sampled noise to a disentangled latent vector which is then mapped to a sequence of audio features so that signal aliasing is suppressed at every layer. To successfully train ASGAN, we introduce a number of new techniques, including a modification to adaptive discriminator augmentation to probabilistically skip discriminator updates. ASGAN achieves state-of-the-art results in unconditional speech synthesis on the Google Speech Commands dataset. It is also substantially faster than the top-performing diffusion models. Through a design that encourages disentanglement, ASGAN is able to perform voice conversion and speech editing without being explicitly trained to do so. ASGAN demonstrates that GANs are still highly competitive with diffusion models. Code, models, samples: https://github.com/RF5/simple-asgan/.
A Temporal Extension of Latent Dirichlet Allocation for Unsupervised Acoustic Unit Discovery
Jun 29, 2022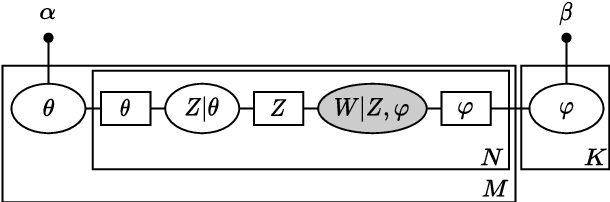
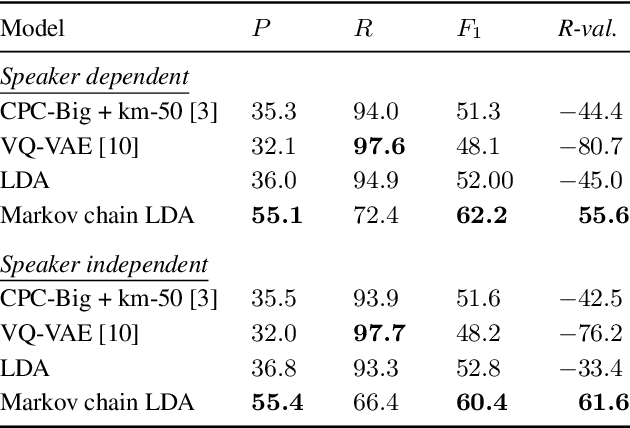
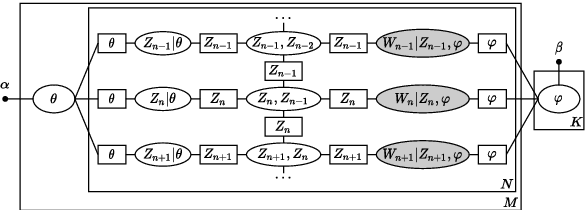
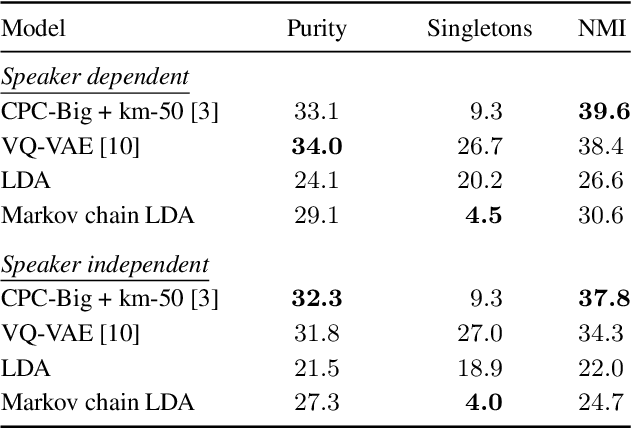
Latent Dirichlet allocation (LDA) is widely used for unsupervised topic modelling on sets of documents. No temporal information is used in the model. However, there is often a relationship between the corresponding topics of consecutive tokens. In this paper, we present an extension to LDA that uses a Markov chain to model temporal information. We use this new model for acoustic unit discovery from speech. As input tokens, the model takes a discretised encoding of speech from a vector quantised (VQ) neural network with 512 codes. The goal is then to map these 512 VQ codes to 50 phone-like units (topics) in order to more closely resemble true phones. In contrast to the base LDA, which only considers how VQ codes co-occur within utterances (documents), the Markov chain LDA additionally captures how consecutive codes follow one another. This extension leads to an increase in cluster quality and phone segmentation results compared to the base LDA. Compared to a recent vector quantised neural network approach that also learns 50 units, the extended LDA model performs better in phone segmentation but worse in mutual information.
Word Segmentation on Discovered Phone Units with Dynamic Programming and Self-Supervised Scoring
Feb 24, 2022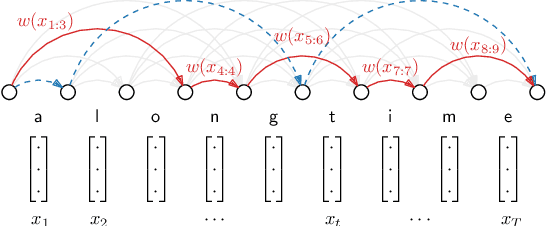
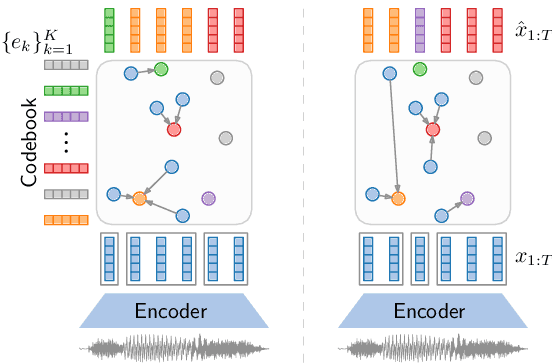
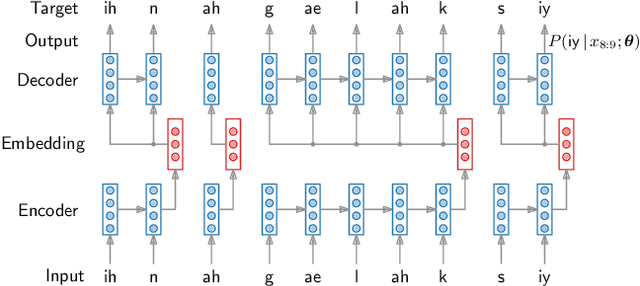
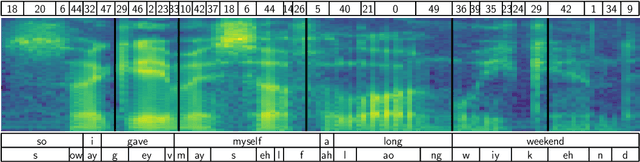
Recent work on unsupervised speech segmentation has used self-supervised models with a phone segmentation module and a word segmentation module that are trained jointly. This paper compares this joint methodology with an older idea: bottom-up phone-like unit discovery is performed first, and symbolic word segmentation is then performed on top of the discovered units (without influencing the lower level). I specifically describe a duration-penalized dynamic programming (DPDP) procedure that can be used for either phone or word segmentation by changing the self-supervised scoring network that gives segment costs. For phone discovery, DPDP is applied with a contrastive predictive coding clustering model, while for word segmentation it is used with an autoencoding recurrent neural network. The two models are chained in order to segment speech. This approach gives comparable word segmentation results to state-of-the-art joint self-supervised models on an English benchmark. On French and Mandarin data, it outperforms previous systems on the ZeroSpeech benchmarks. Analysis shows that the chained DPDP system segments shorter filler words well, but longer words might require an external top-down signal.