 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for Learning Sparse Additive Models with Interactions in High Dimensions
May 08, 2017
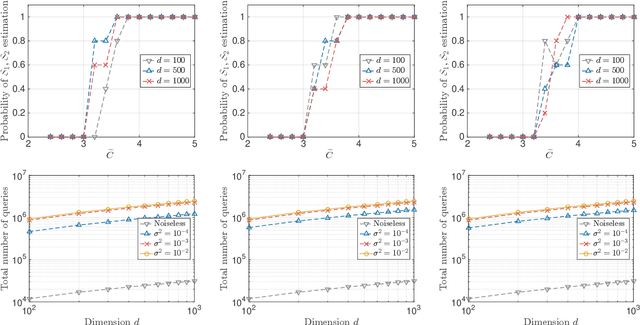
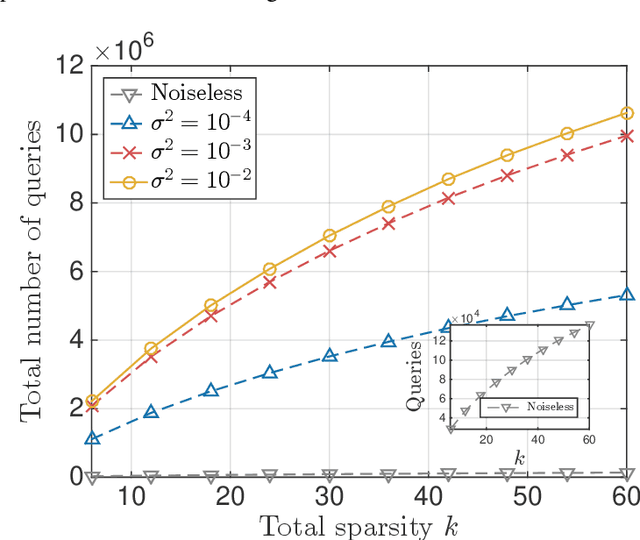
A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$ where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi$'s, $\mathcal{S}$ to be unknown, there exists extensive work for estimating $f$ from its samples. In this work, we consider a generalized version of SPAMs, that also allows for the presence of a sparse number of second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, with $|\mathcal{S}_1| \ll d, |\mathcal{S}_2| \ll d^2$, the function $f$ is now assumed to be of the form: $\sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_l,x_{l^{\prime}})$. Assuming we have the freedom to query $f$ anywhere in its domain, we derive efficient algorithms that provably recover $\mathcal{S}_1,\mathcal{S}_2$ with finite sample bounds. Our analysis covers the noiseless setting where exact samples of $f$ are obtained, and also extends to the noisy setting where the queries are corrupted with noise. For the noisy setting in particular, we consider two noise models namely: i.i.d Gaussian noise and arbitrary but bounded noise. Our main methods for identification of $\mathcal{S}_2$ essentially rely on estimation of sparse Hessian matrices, for which we provide two novel compressed sensing based schemes. Once $\mathcal{S}_1, \mathcal{S}_2$ are known, we show how the individual components $\phi_p$, $\phi_{(l,l^{\prime})}$ can be estimated via additional queries of $f$, with uniform error bounds. Lastly, we provide simulation results on synthetic data that validate our theoretical findings.
Learning Non-Parametric Basis Independent Models from Point Queries via Low-Rank Methods
Jun 06, 2016
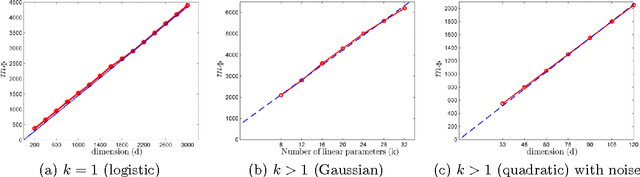
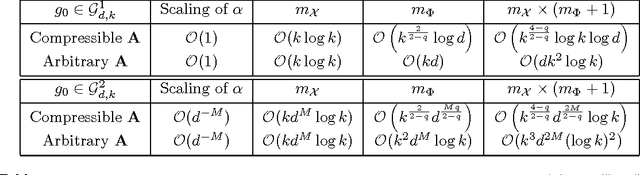
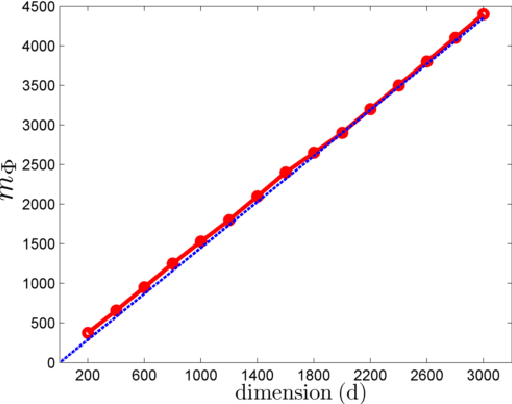
We consider the problem of learning multi-ridge functions of the form f(x) = g(Ax) from point evaluations of f. We assume that the function f is defined on an l_2-ball in R^d, g is twice continuously differentiable almost everywhere, and A \in R^{k \times d} is a rank k matrix, where k << d. We propose a randomized, polynomial-complexity sampling scheme for estimating such functions. Our theoretical developments leverage recent techniques from low rank matrix recovery, which enables us to derive a polynomial time estimator of the function f along with uniform approximation guarantees. We prove that our scheme can also be applied for learning functions of the form: f(x) = \sum_{i=1}^{k} g_i(a_i^T x), provided f satisfies certain smoothness conditions in a neighborhood around the origin. We also characterize the noise robustness of the scheme. Finally, we present numerical examples to illustrate the theoretical bounds in action.
Learning Sparse Additive Models with Interactions in High Dimensions
Apr 18, 2016A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is referred to as a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$, where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi_l$'s and $\mathcal{S}$ to be unknown, the problem of estimating $f$ from its samples has been studied extensively. In this work, we consider a generalized SPAM, allowing for second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, the function $f$ is assumed to be of the form: $$f(\mathbf{x}) = \sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_{l},x_{l^{\prime}}).$$ Assuming $\phi_{p},\phi_{(l,l^{\prime})}$, $\mathcal{S}_1$ and, $\mathcal{S}_2$ to be unknown, we provide a randomized algorithm that queries $f$ and exactly recovers $\mathcal{S}_1,\mathcal{S}_2$. Consequently, this also enables us to estimate the underlying $\phi_p, \phi_{(l,l^{\prime})}$. We derive sample complexity bounds for our scheme and also extend our analysis to include the situation where the queries are corrupted with noise -- either stochastic, or arbitrary but bounded. Lastly, we provide simulation results on synthetic data, that validate our theoretical findings.
Continuum armed bandit problem of few variables in high dimensions
Aug 22, 2014We consider the stochastic and adversarial settings of continuum armed bandits where the arms are indexed by [0,1]^d. The reward functions r:[0,1]^d -> R are assumed to intrinsically depend on at most k coordinate variables implying r(x_1,..,x_d) = g(x_{i_1},..,x_{i_k}) for distinct and unknown i_1,..,i_k from {1,..,d} and some locally Holder continuous g:[0,1]^k -> R with exponent 0 < alpha <= 1. Firstly, assuming (i_1,..,i_k) to be fixed across time, we propose a simple modification of the CAB1 algorithm where we construct the discrete set of sampling points to obtain a bound of O(n^((alpha+k)/(2*alpha+k)) (log n)^((alpha)/(2*alpha+k)) C(k,d)) on the regret, with C(k,d) depending at most polynomially in k and sub-logarithmically in d. The construction is based on creating partitions of {1,..,d} into k disjoint subsets and is probabilistic, hence our result holds with high probability. Secondly we extend our results to also handle the more general case where (i_1,...,i_k) can change over time and derive regret bounds for the same.