 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring How Fair Model Representations Relate to Fair Recommendations
Mar 25, 2026One of the many fairness definitions pursued in recent recommender system research targets mitigating demographic information encoded in model representations. Models optimized for this definition are typically evaluated on how well demographic attributes can be classified given model representations, with the (implicit) assumption that this measure accurately reflects \textit{recommendation parity}, i.e., how similar recommendations given to different users are. We challenge this assumption by comparing the amount of demographic information encoded in representations with various measures of how the recommendations differ. We propose two new approaches for measuring how well demographic information can be classified given ranked recommendations. Our results from extensive testing of multiple models on one real and multiple synthetically generated datasets indicate that optimizing for fair representations positively affects recommendation parity, but also that evaluation at the representation level is not a good proxy for measuring this effect when comparing models. We also provide extensive insight into how recommendation-level fairness metrics behave for various models by evaluating their performances on numerous generated datasets with different properties.
CINDI: Conditional Imputation and Noisy Data Integrity with Flows in Power Grid Data
Mar 12, 2026Real-world multivariate time series, particularly in critical infrastructure such as electrical power grids, are often corrupted by noise and anomalies that degrade the performance of downstream tasks. Standard data cleaning approaches often rely on disjoint strategies, which involve detecting errors with one model and imputing them with another. Such approaches can fail to capture the full joint distribution of the data and ignore prediction uncertainty. This work introduces Conditional Imputation and Noisy Data Integrity (CINDI), an unsupervised probabilistic framework designed to restore data integrity in complex time series. Unlike fragmented approaches, CINDI unifies anomaly detection and imputation into a single end-to-end system built on conditional normalizing flows. By modeling the exact conditional likelihood of the data, the framework identifies low-probability segments and iteratively samples statistically consistent replacements. This allows CINDI to efficiently reuse learned information while preserving the underlying physical and statistical properties of the system. We evaluate the framework using real-world grid loss data from a Norwegian power distribution operator, though the methodology is designed to generalize to any multivariate time series domain. The results demonstrate that CINDI yields robust performance compared to competitive baselines, offering a scalable solution for maintaining reliability in noisy environments.
Temporal-Conditioned Normalizing Flows for Multivariate Time Series Anomaly Detection
Mar 10, 2026This paper introduces temporal-conditioned normalizing flows (tcNF), a novel framework that addresses anomaly detection in time series data with accurate modeling of temporal dependencies and uncertainty. By conditioning normalizing flows on previous observations, tcNF effectively captures complex temporal dynamics and generates accurate probability distributions of expected behavior. This autoregressive approach enables robust anomaly detection by identifying low-probability events within the learned distribution. We evaluate tcNF on diverse datasets, demonstrating good accuracy and robustness compared to existing methods. A comprehensive analysis of strengths and limitations and open-source code is provided to facilitate reproducibility and future research.
Causal computations in Semi Markovian Structural Causal Models using divide and conquer
Nov 17, 2025



Recently, Bjøru et al. proposed a novel divide-and-conquer algorithm for bounding counterfactual probabilities in structural causal models (SCMs). They assumed that the SCMs were learned from purely observational data, leading to an imprecise characterization of the marginal distributions of exogenous variables. Their method leveraged the canonical representation of structural equations to decompose a general SCM with high-cardinality exogenous variables into a set of sub-models with low-cardinality exogenous variables. These sub-models had precise marginals over the exogenous variables and therefore admitted efficient exact inference. The aggregated results were used to bound counterfactual probabilities in the original model. The approach was developed for Markovian models, where each exogenous variable affects only a single endogenous variable. In this paper, we investigate extending the methodology to \textit{semi-Markovian} SCMs, where exogenous variables may influence multiple endogenous variables. Such models are capable of representing confounding relationships that Markovian models cannot. We illustrate the challenges of this extension using a minimal example, which motivates a set of alternative solution strategies. These strategies are evaluated both theoretically and through a computational study.
Probing the Robustness of Time-series Forecasting Models with CounterfacTS
Mar 06, 2024



A common issue for machine learning models applied to time-series forecasting is the temporal evolution of the data distributions (i.e., concept drift). Because most of the training data does not reflect such changes, the models present poor performance on the new out-of-distribution scenarios and, therefore, the impact of such events cannot be reliably anticipated ahead of time. We present and publicly release CounterfacTS, a tool to probe the robustness of deep learning models in time-series forecasting tasks via counterfactuals. CounterfacTS has a user-friendly interface that allows the user to visualize, compare and quantify time series data and their forecasts, for a number of datasets and deep learning models. Furthermore, the user can apply various transformations to the time series and explore the resulting changes in the forecasts in an interpretable manner. Through example cases, we illustrate how CounterfacTS can be used to i) identify the main features characterizing and differentiating sets of time series, ii) assess how the model performance depends on these characateristics, and iii) guide transformations of the original time series to create counterfactuals with desired properties for training and increasing the forecasting performance in new regions of the data distribution. We discuss the importance of visualizing and considering the location of the data in a projected feature space to transform time-series and create effective counterfactuals for training the models. Overall, CounterfacTS aids at creating counterfactuals to efficiently explore the impact of hypothetical scenarios not covered by the original data in time-series forecasting tasks.
Lecture Notes in Probabilistic Diffusion Models
Dec 16, 2023Diffusion models are loosely modelled based on non-equilibrium thermodynamics, where \textit{diffusion} refers to particles flowing from high-concentration regions towards low-concentration regions. In statistics, the meaning is quite similar, namely the process of transforming a complex distribution $p_{\text{complex}}$ on $\mathbb{R}^d$ to a simple distribution $p_{\text{prior}}$ on the same domain. This constitutes a Markov chain of diffusion steps of slowly adding random noise to data, followed by a reverse diffusion process in which the data is reconstructed from the noise. The diffusion model learns the data manifold to which the original and thus the reconstructed data samples belong, by training on a large number of data points. While the diffusion process pushes a data sample off the data manifold, the reverse process finds a trajectory back to the data manifold. Diffusion models have -- unlike variational autoencoder and flow models -- latent variables with the same dimensionality as the original data, and they are currently\footnote{At the time of writing, 2023.} outperforming other approaches -- including Generative Adversarial Networks (GANs) -- to modelling the distribution of, e.g., natural images.
Providing Previously Unseen Users Fair Recommendations Using Variational Autoencoders
Aug 29, 2023An emerging definition of fairness in machine learning requires that models are oblivious to demographic user information, e.g., a user's gender or age should not influence the model. Personalized recommender systems are particularly prone to violating this definition through their explicit user focus and user modelling. Explicit user modelling is also an aspect that makes many recommender systems incapable of providing hitherto unseen users with recommendations. We propose novel approaches for mitigating discrimination in Variational Autoencoder-based recommender systems by limiting the encoding of demographic information. The approaches are capable of, and evaluated on, providing users that are not represented in the training data with fair recommendations.
Consumer-side Fairness in Recommender Systems: A Systematic Survey of Methods and Evaluation
May 16, 2023In the current landscape of ever-increasing levels of digitalization, we are facing major challenges pertaining to scalability. Recommender systems have become irreplaceable both for helping users navigate the increasing amounts of data and, conversely, aiding providers in marketing products to interested users. The growing awareness of discrimination in machine learning methods has recently motivated both academia and industry to research how fairness can be ensured in recommender systems. For recommender systems, such issues are well exemplified by occupation recommendation, where biases in historical data may lead to recommender systems relating one gender to lower wages or to the propagation of stereotypes. In particular, consumer-side fairness, which focuses on mitigating discrimination experienced by users of recommender systems, has seen a vast number of diverse approaches for addressing different types of discrimination. The nature of said discrimination depends on the setting and the applied fairness interpretation, of which there are many variations. This survey serves as a systematic overview and discussion of the current research on consumer-side fairness in recommender systems. To that end, a novel taxonomy based on high-level fairness interpretation is proposed and used to categorize the research and their proposed fairness evaluation metrics. Finally, we highlight some suggestions for the future direction of the field.
A data-driven modular architecture with denoising autoencoders for health indicator construction in a manufacturing process
Aug 10, 2022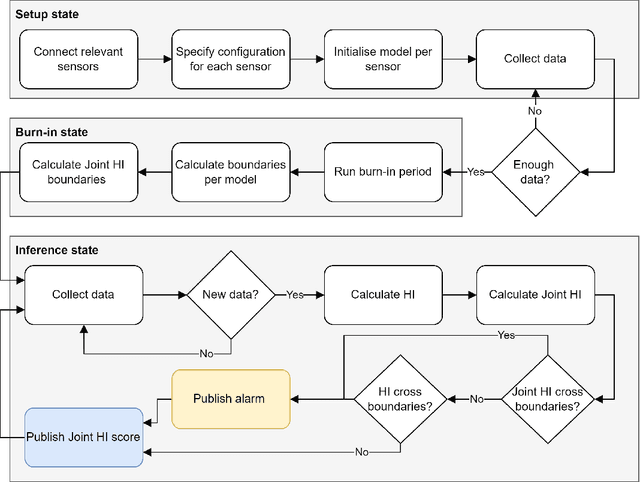
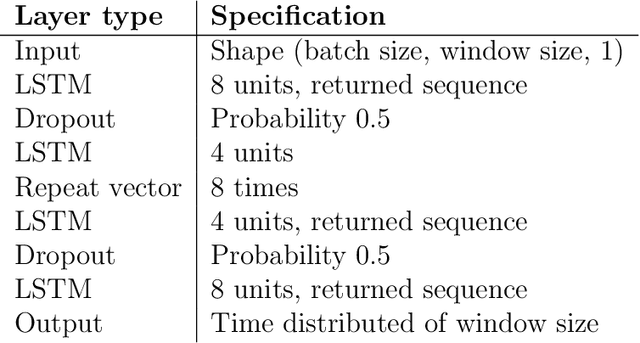
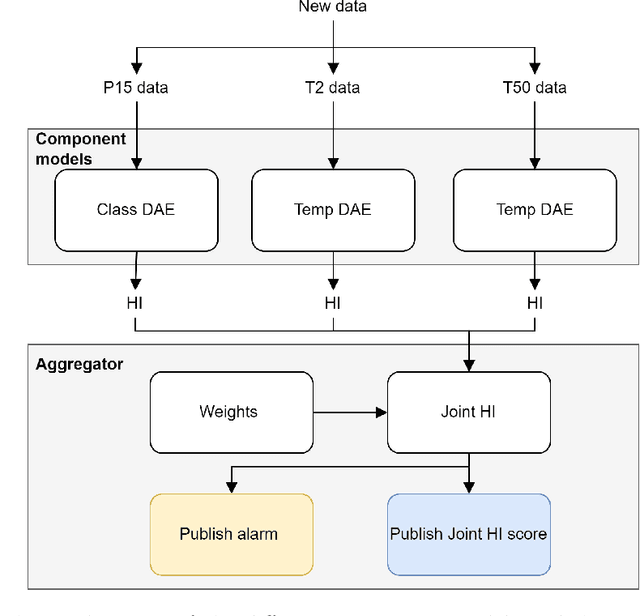

Within the field of prognostics and health management (PHM), health indicators (HI) can be used to aid the production and, e.g. schedule maintenance and avoid failures. However, HI is often engineered to a specific process and typically requires large amounts of historical data for set-up. This is especially a challenge for SMEs, which often lack sufficient resources and knowledge to benefit from PHM. In this paper, we propose ModularHI, a modular approach in the construction of HI for a system without historical data. With ModularHI, the operator chooses which sensor inputs are available, and then ModularHI will compute a baseline model based on data collected during a burn-in state. This baseline model will then be used to detect if the system starts to degrade over time. We test the ModularHI on two open datasets, CMAPSS and N-CMAPSS. Results from the former dataset showcase our system's ability to detect degradation, while results from the latter point to directions for further research within the area. The results shows that our novel approach is able to detect system degradation without historical data.
Correcting Classification: A Bayesian Framework Using Explanation Feedback to Improve Classification Abilities
May 13, 2021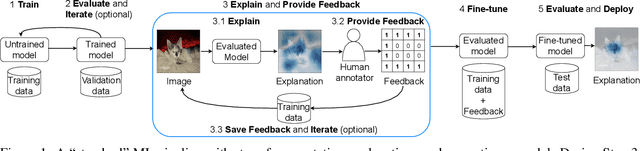
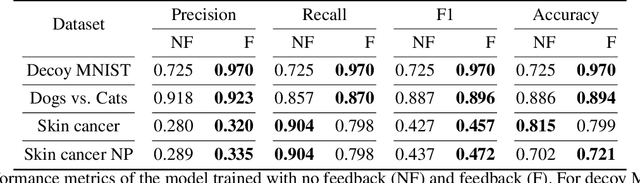

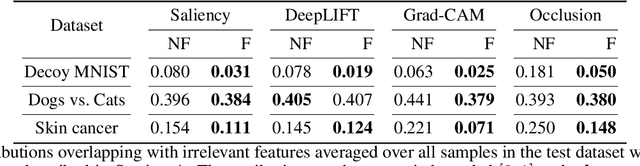
Neural networks (NNs) have shown high predictive performance, however, with shortcomings. Firstly, the reasons behind the classifications are not fully understood. Several explanation methods have been developed, but they do not provide mechanisms for users to interact with the explanations. Explanations are social, meaning they are a transfer of knowledge through interactions. Nonetheless, current explanation methods contribute only to one-way communication. Secondly, NNs tend to be overconfident, providing unreasonable uncertainty estimates on out-of-distribution observations. We overcome these difficulties by training a Bayesian convolutional neural network (CNN) that uses explanation feedback. After training, the model presents explanations of training sample classifications to an annotator. Based on the provided information, the annotator can accept or reject the explanations by providing feedback. Our proposed method utilizes this feedback for fine-tuning to correct the model such that the explanations and classifications improve. We use existing CNN architectures to demonstrate the method's effectiveness on one toy dataset (decoy MNIST) and two real-world datasets (Dogs vs. Cats and ISIC skin cancer). The experiments indicate that few annotated explanations and fine-tuning epochs are needed to improve the model and predictive performance, making the model more trustworthy and understandable.