 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Bandits with Linear Constraints
Jun 17, 2020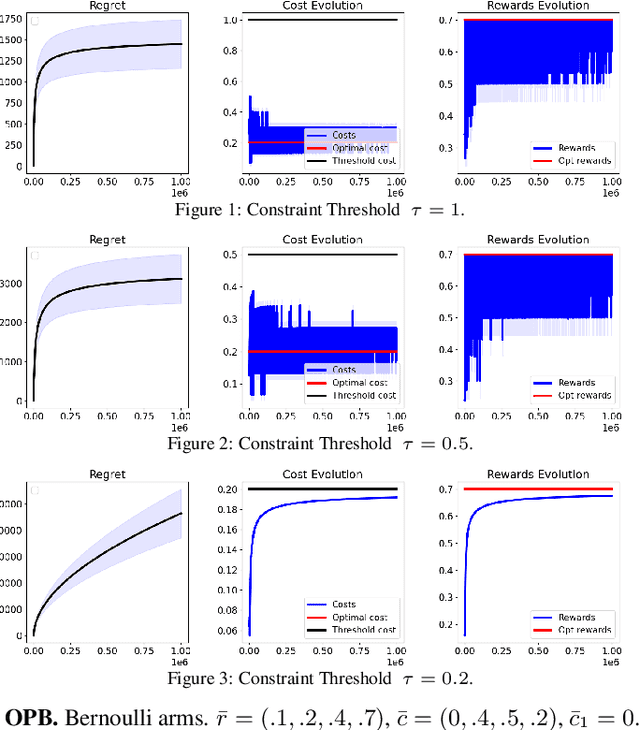
We study a constrained contextual linear bandit setting, where the goal of the agent is to produce a sequence of policies, whose expected cumulative reward over the course of $T$ rounds is maximum, and each has an expected cost below a certain threshold $\tau$. We propose an upper-confidence bound algorithm for this problem, called optimistic pessimistic linear bandit (OPLB), and prove an $\widetilde{\mathcal{O}}(\frac{d\sqrt{T}}{\tau-c_0})$ bound on its $T$-round regret, where the denominator is the difference between the constraint threshold and the cost of a known feasible action. We further specialize our results to multi-armed bandits and propose a computationally efficient algorithm for this setting. We prove a regret bound of $\widetilde{\mathcal{O}}(\frac{\sqrt{KT}}{\tau - c_0})$ for this algorithm in $K$-armed bandits, which is a $\sqrt{K}$ improvement over the regret bound we obtain by simply casting multi-armed bandits as an instance of contextual linear bandits and using the regret bound of OPLB. We also prove a lower-bound for the problem studied in the paper and provide simulations to validate our theoretical results.
Faster DBSCAN via subsampled similarity queries
Jun 11, 2020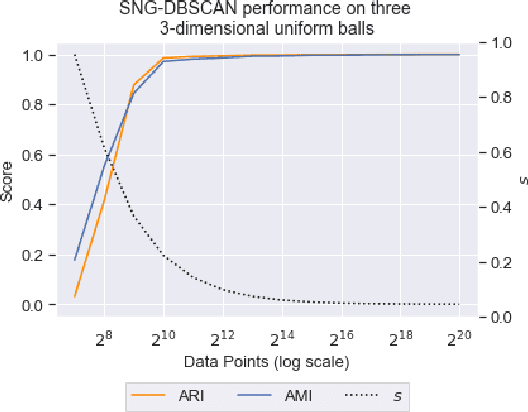
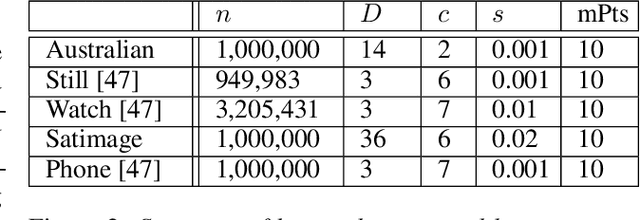
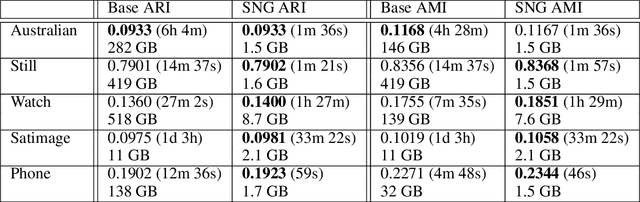
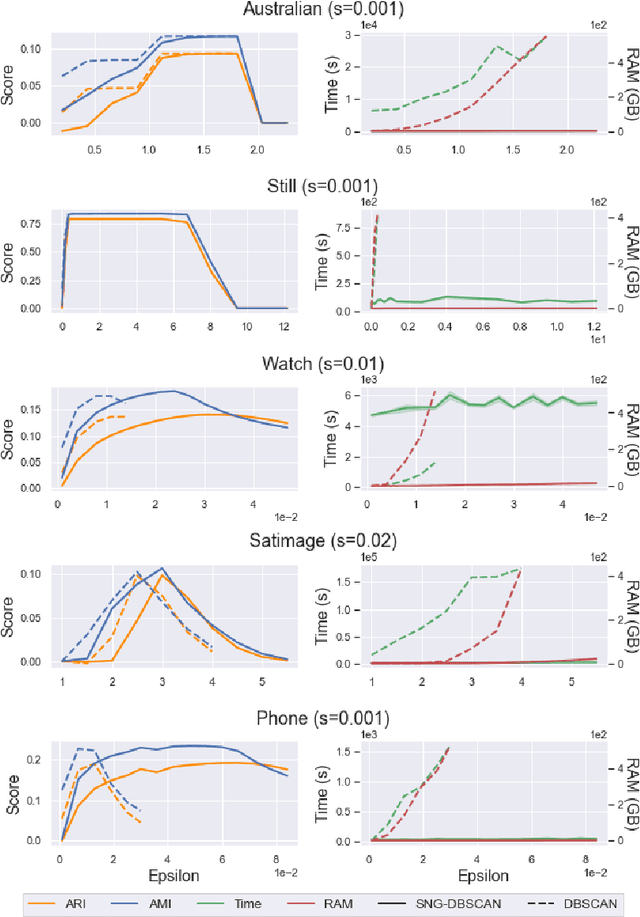
DBSCAN is a popular density-based clustering algorithm. It computes the $\epsilon$-neighborhood graph of a dataset and uses the connected components of the high-degree nodes to decide the clusters. However, the full neighborhood graph may be too costly to compute with a worst-case complexity of $O(n^2)$. In this paper, we propose a simple variant called SNG-DBSCAN, which clusters based on a subsampled $\epsilon$-neighborhood graph, only requires access to similarity queries for pairs of points and in particular avoids any complex data structures which need the embeddings of the data points themselves. The runtime of the procedure is $O(sn^2)$, where $s$ is the sampling rate. We show under some natural theoretical assumptions that $s \approx \log n/n$ is sufficient for statistical cluster recovery guarantees leading to an $O(n\log n)$ complexity. We provide an extensive experimental analysis showing that on large datasets, one can subsample as little as $0.1\%$ of the neighborhood graph, leading to as much as over 200x speedup and 250x reduction in RAM consumption compared to scikit-learn's implementation of DBSCAN, while still maintaining competitive clustering performance.
Learning the Truth From Only One Side of the Story
Jun 08, 2020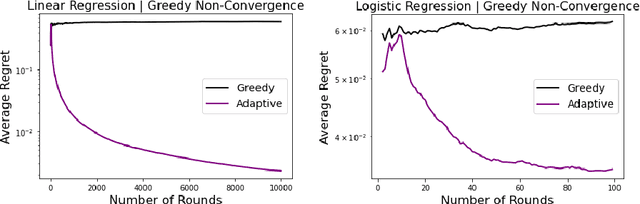
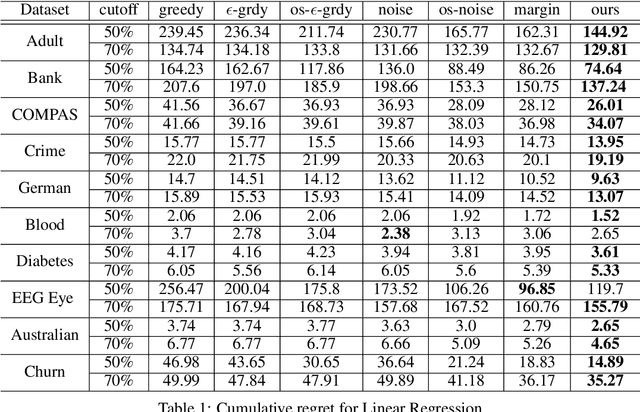
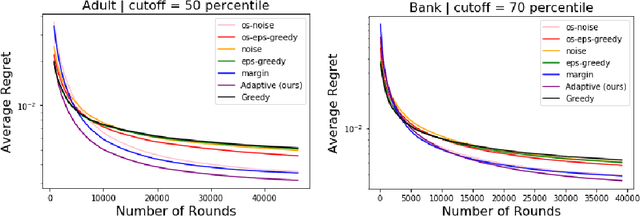
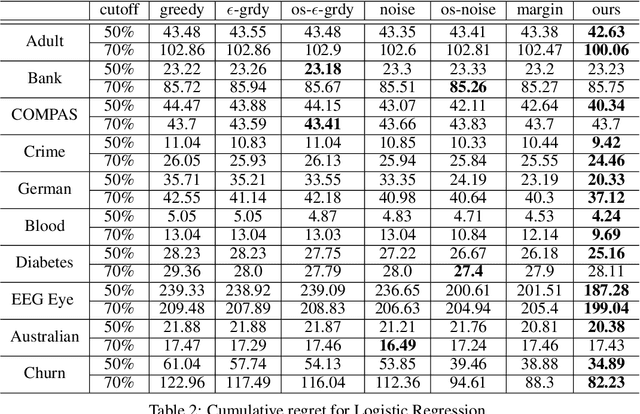
Learning under one-sided feedback (i.e., where examples arrive in an online fashion and the learner only sees the labels for examples it predicted positively on) is a fundamental problem in machine learning -- applications include lending and recommendation systems. Despite this, there has been surprisingly little progress made in ways to mitigate the effects of the sampling bias that arises. We focus on generalized linear models and show that without adjusting for this sampling bias, the model may converge sub-optimally or even fail to converge to the optimal solution. We propose an adaptive Upper Confidence Bound approach that comes with rigorous regret guarantees and we show that it outperforms several existing methods experimentally. Our method leverages uncertainty estimation techniques for generalized linear models to more efficiently explore uncertain areas than existing approaches which explore randomly.
Deep k-NN for Noisy Labels
Apr 26, 2020
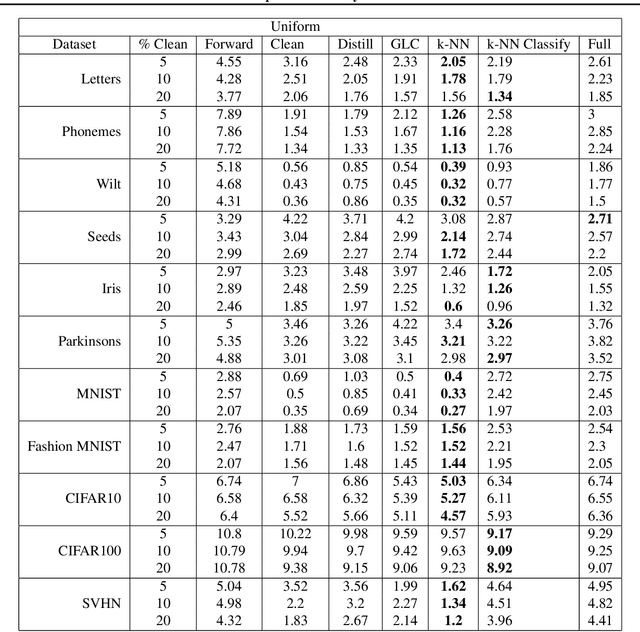
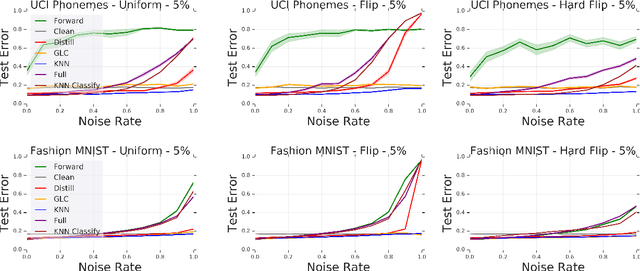
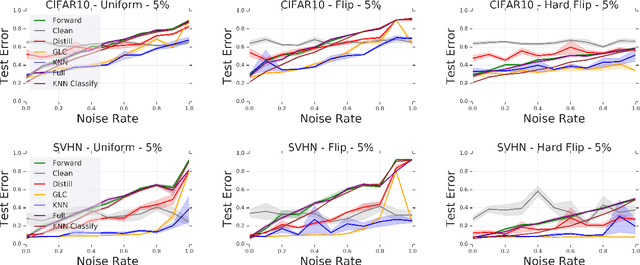
Modern machine learning models are often trained on examples with noisy labels that hurt performance and are hard to identify. In this paper, we provide an empirical study showing that a simple $k$-nearest neighbor-based filtering approach on the logit layer of a preliminary model can remove mislabeled training data and produce more accurate models than many recently proposed methods. We also provide new statistical guarantees into its efficacy.
Robustness Guarantees for Mode Estimation with an Application to Bandits
Mar 05, 2020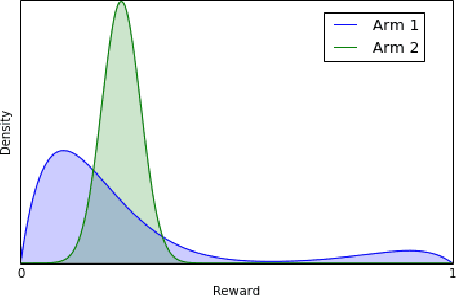



Mode estimation is a classical problem in statistics with a wide range of applications in machine learning. Despite this, there is little understanding in its robustness properties under possibly adversarial data contamination. In this paper, we give precise robustness guarantees as well as privacy guarantees under simple randomization. We then introduce a theory for multi-armed bandits where the values are the modes of the reward distributions instead of the mean. We prove regret guarantees for the problems of top arm identification, top m-arms identification, contextual modal bandits, and infinite continuous arms top arm recovery. We show in simulations that our algorithms are robust to perturbation of the arms by adversarial noise sequences, thus rendering modal bandits an attractive choice in situations where the rewards may have outliers or adversarial corruptions.
Group-based Fair Learning Leads to Counter-intuitive Predictions
Oct 04, 2019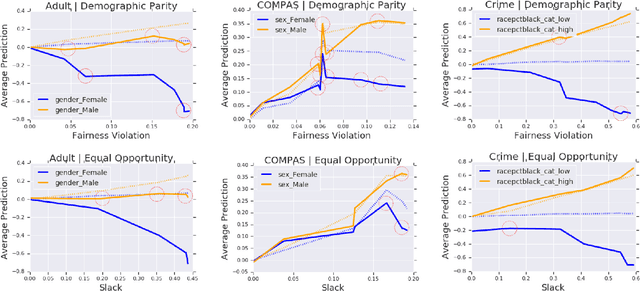

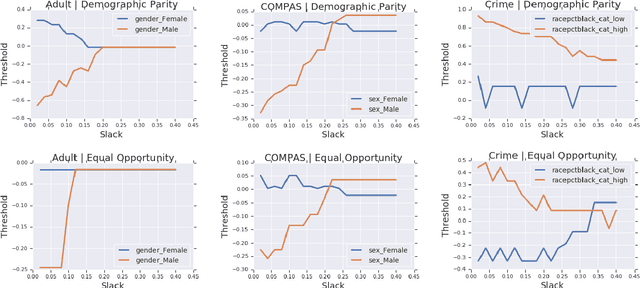
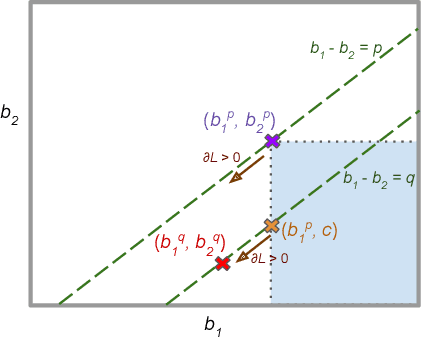
A number of machine learning (ML) methods have been proposed recently to maximize model predictive accuracy while enforcing notions of group parity or fairness across sub-populations. We propose a desirable property for these procedures, slack-consistency: For any individual, the predictions of the model should be monotonic with respect to allowed slack (i.e., maximum allowed group-parity violation). Such monotonicity can be useful for individuals to understand the impact of enforcing fairness on their predictions. Surprisingly, we find that standard ML methods for enforcing fairness violate this basic property. Moreover, this undesirable behavior arises in situations agnostic to the complexity of the underlying model or approximate optimizations, suggesting that the simple act of incorporating a constraint can lead to drastically unintended behavior in ML. We present a simple theoretical method for enforcing slack-consistency, while encouraging further discussions on the unintended behaviors potentially induced when enforcing group-based parity.
Wasserstein Fair Classification
Jul 28, 2019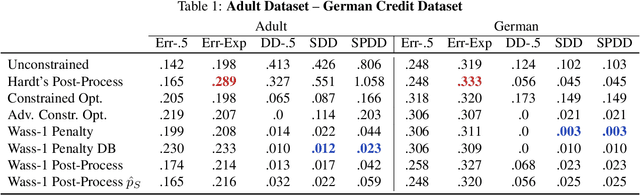
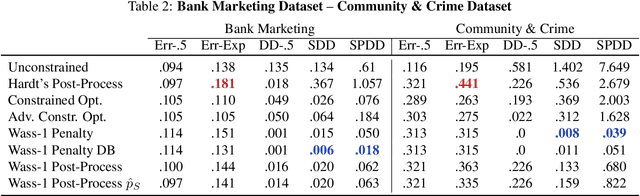
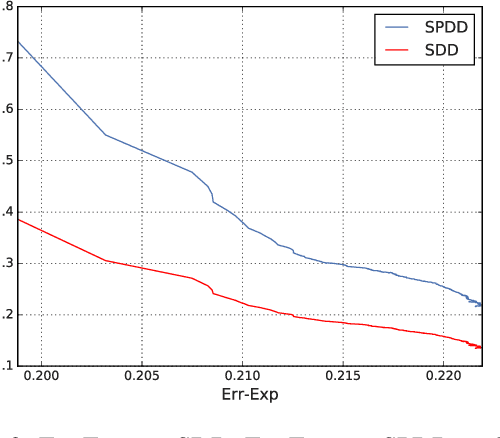
We propose an approach to fair classification that enforces independence between the classifier outputs and sensitive information by minimizing Wasserstein-1 distances. The approach has desirable theoretical properties and is robust to specific choices of the threshold used to obtain class predictions from model outputs. We introduce different methods that enable hiding sensitive information at test time or have a simple and fast implementation. We show empirical performance against different fairness baselines on several benchmark fairness datasets.
Minimum-Margin Active Learning
May 31, 2019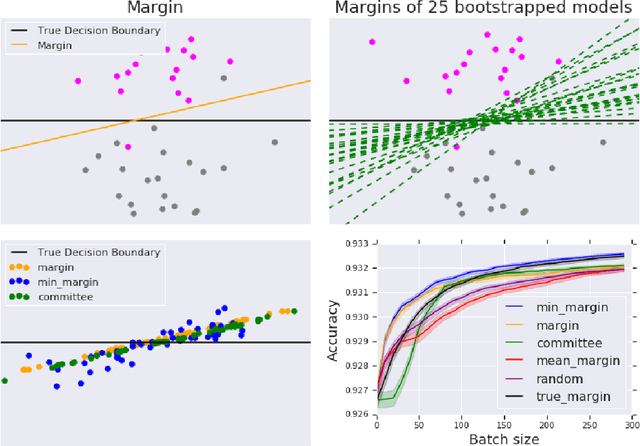
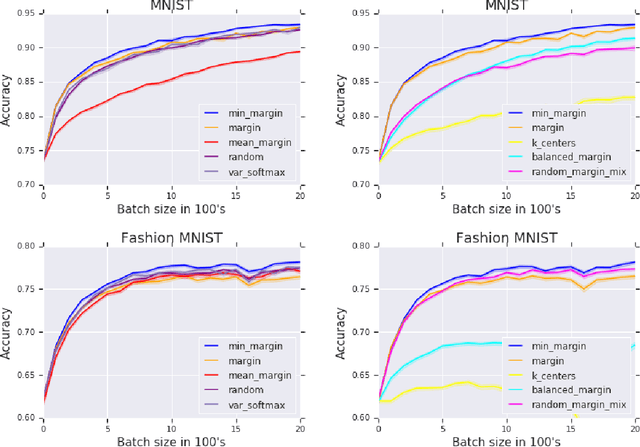
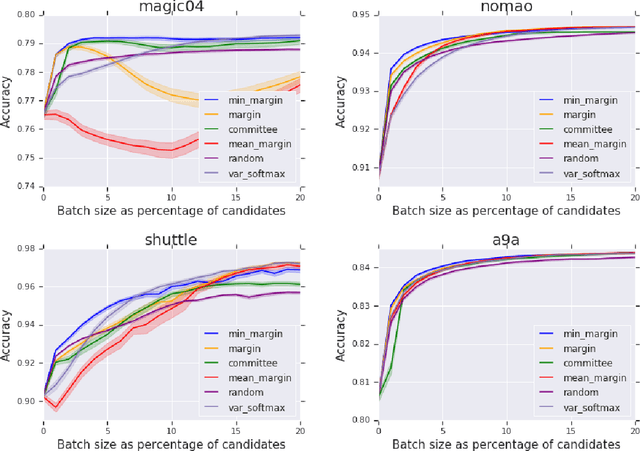
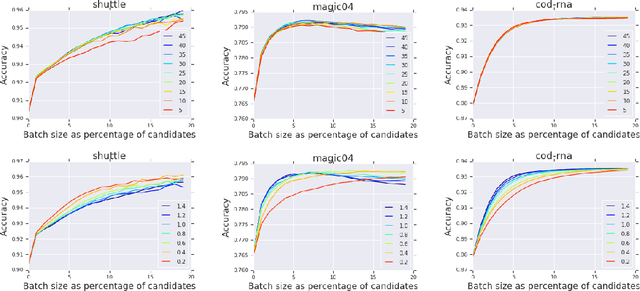
We present a new active sampling method we call min-margin which trains multiple learners on bootstrap samples and then chooses the examples to label based on the candidates' minimum margin amongst the bootstrapped models. This extends standard margin sampling in a way that increases its diversity in a supervised manner as it arises from the model uncertainty. We focus on the one-shot batch active learning setting, and show theoretically and through extensive experiments on a broad set of problems that min-margin outperforms other methods, particularly as batch size grows.
Identifying and Correcting Label Bias in Machine Learning
Jan 15, 2019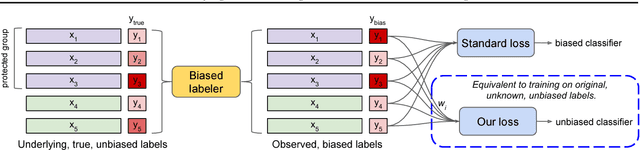
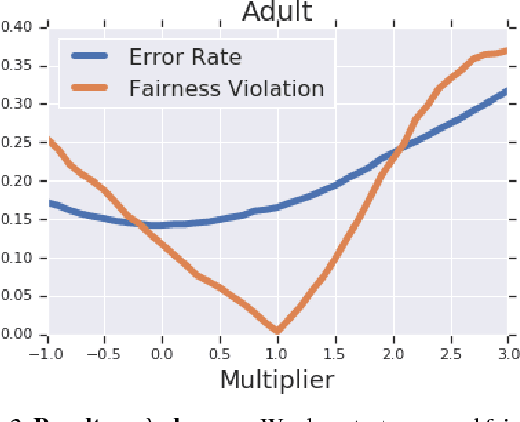
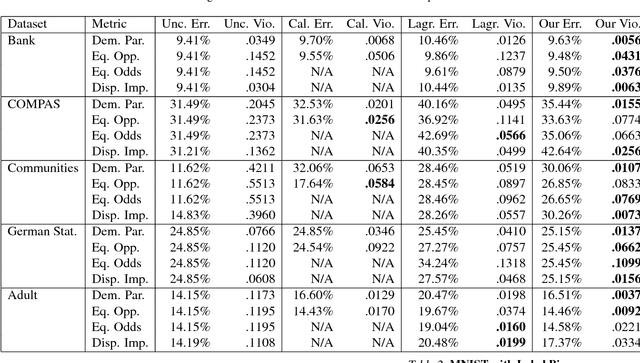
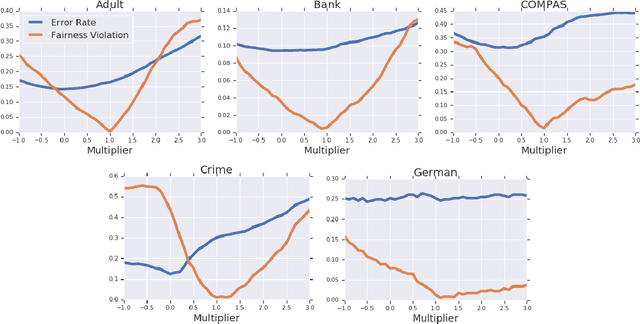
Datasets often contain biases which unfairly disadvantage certain groups, and classifiers trained on such datasets can inherit these biases. In this paper, we provide a mathematical formulation of how this bias can arise. We do so by assuming the existence of underlying, unknown, and unbiased labels which are overwritten by an agent who intends to provide accurate labels but may have biases against certain groups. Despite the fact that we only observe the biased labels, we are able to show that the bias may nevertheless be corrected by re-weighting the data points without changing the labels. We show, with theoretical guarantees, that training on the re-weighted dataset corresponds to training on the unobserved but unbiased labels, thus leading to an unbiased machine learning classifier. Our procedure is fast and robust and can be used with virtually any learning algorithm. We evaluate on a number of standard machine learning fairness datasets and a variety of fairness notions, finding that our method outperforms standard approaches in achieving fair classification.
Non-Asymptotic Uniform Rates of Consistency for k-NN Regression
Nov 03, 2018We derive high-probability finite-sample uniform rates of consistency for $k$-NN regression that are optimal up to logarithmic factors under mild assumptions. We moreover show that $k$-NN regression adapts to an unknown lower intrinsic dimension automatically. We then apply the $k$-NN regression rates to establish new results about estimating the level sets and global maxima of a function from noisy observations.