 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering
Apr 29, 2024Table Question Answering (TQA) aims at composing an answer to a question based on tabular data. While prior research has shown that TQA models lack robustness, understanding the underlying cause and nature of this issue remains predominantly unclear, posing a significant obstacle to the development of robust TQA systems. In this paper, we formalize three major desiderata for a fine-grained evaluation of robustness of TQA systems. They should (i) answer questions regardless of alterations in table structure, (ii) base their responses on the content of relevant cells rather than on biases, and (iii) demonstrate robust numerical reasoning capabilities. To investigate these aspects, we create and publish a novel TQA evaluation benchmark in English. Our extensive experimental analysis reveals that none of the examined state-of-the-art TQA systems consistently excels in these three aspects. Our benchmark is a crucial instrument for monitoring the behavior of TQA systems and paves the way for the development of robust TQA systems. We release our benchmark publicly.
Rehearsal-Free Modular and Compositional Continual Learning for Language Models
Mar 31, 2024Continual learning aims at incrementally acquiring new knowledge while not forgetting existing knowledge. To overcome catastrophic forgetting, methods are either rehearsal-based, i.e., store data examples from previous tasks for data replay, or isolate parameters dedicated to each task. However, rehearsal-based methods raise privacy and memory issues, and parameter-isolation continual learning does not consider interaction between tasks, thus hindering knowledge transfer. In this work, we propose MoCL, a rehearsal-free Modular and Compositional Continual Learning framework which continually adds new modules to language models and composes them with existing modules. Experiments on various benchmarks show that MoCL outperforms state of the art and effectively facilitates knowledge transfer.
Explaining Pre-Trained Language Models with Attribution Scores: An Analysis in Low-Resource Settings
Mar 08, 2024



Attribution scores indicate the importance of different input parts and can, thus, explain model behaviour. Currently, prompt-based models are gaining popularity, i.a., due to their easier adaptability in low-resource settings. However, the quality of attribution scores extracted from prompt-based models has not been investigated yet. In this work, we address this topic by analyzing attribution scores extracted from prompt-based models w.r.t. plausibility and faithfulness and comparing them with attribution scores extracted from fine-tuned models and large language models. In contrast to previous work, we introduce training size as another dimension into the analysis. We find that using the prompting paradigm (with either encoder-based or decoder-based models) yields more plausible explanations than fine-tuning the models in low-resource settings and Shapley Value Sampling consistently outperforms attention and Integrated Gradients in terms of leading to more plausible and faithful explanations.
GradSim: Gradient-Based Language Grouping for Effective Multilingual Training
Oct 23, 2023Most languages of the world pose low-resource challenges to natural language processing models. With multilingual training, knowledge can be shared among languages. However, not all languages positively influence each other and it is an open research question how to select the most suitable set of languages for multilingual training and avoid negative interference among languages whose characteristics or data distributions are not compatible. In this paper, we propose GradSim, a language grouping method based on gradient similarity. Our experiments on three diverse multilingual benchmark datasets show that it leads to the largest performance gains compared to other similarity measures and it is better correlated with cross-lingual model performance. As a result, we set the new state of the art on AfriSenti, a benchmark dataset for sentiment analysis on low-resource African languages. In our extensive analysis, we further reveal that besides linguistic features, the topics of the datasets play an important role for language grouping and that lower layers of transformer models encode language-specific features while higher layers capture task-specific information.
Neighboring Words Affect Human Interpretation of Saliency Explanations
May 06, 2023Word-level saliency explanations ("heat maps over words") are often used to communicate feature-attribution in text-based models. Recent studies found that superficial factors such as word length can distort human interpretation of the communicated saliency scores. We conduct a user study to investigate how the marking of a word's neighboring words affect the explainee's perception of the word's importance in the context of a saliency explanation. We find that neighboring words have significant effects on the word's importance rating. Concretely, we identify that the influence changes based on neighboring direction (left vs. right) and a-priori linguistic and computational measures of phrases and collocations (vs. unrelated neighboring words). Our results question whether text-based saliency explanations should be continued to be communicated at word level, and inform future research on alternative saliency explanation methods.
NLNDE at SemEval-2023 Task 12: Adaptive Pretraining and Source Language Selection for Low-Resource Multilingual Sentiment Analysis
Apr 28, 2023



This paper describes our system developed for the SemEval-2023 Task 12 "Sentiment Analysis for Low-resource African Languages using Twitter Dataset". Sentiment analysis is one of the most widely studied applications in natural language processing. However, most prior work still focuses on a small number of high-resource languages. Building reliable sentiment analysis systems for low-resource languages remains challenging, due to the limited training data in this task. In this work, we propose to leverage language-adaptive and task-adaptive pretraining on African texts and study transfer learning with source language selection on top of an African language-centric pretrained language model. Our key findings are: (1) Adapting the pretrained model to the target language and task using a small yet relevant corpus improves performance remarkably by more than 10 F1 score points. (2) Selecting source languages with positive transfer gains during training can avoid harmful interference from dissimilar languages, leading to better results in multilingual and cross-lingual settings. In the shared task, our system wins 8 out of 15 tracks and, in particular, performs best in the multilingual evaluation.
SwitchPrompt: Learning Domain-Specific Gated Soft Prompts for Classification in Low-Resource Domains
Feb 14, 2023Prompting pre-trained language models leads to promising results across natural language processing tasks but is less effective when applied in low-resource domains, due to the domain gap between the pre-training data and the downstream task. In this work, we bridge this gap with a novel and lightweight prompting methodology called SwitchPrompt for the adaptation of language models trained on datasets from the general domain to diverse low-resource domains. Using domain-specific keywords with a trainable gated prompt, SwitchPrompt offers domain-oriented prompting, that is, effective guidance on the target domains for general-domain language models. Our few-shot experiments on three text classification benchmarks demonstrate the efficacy of the general-domain pre-trained language models when used with SwitchPrompt. They often even outperform their domain-specific counterparts trained with baseline state-of-the-art prompting methods by up to 10.7% performance increase in accuracy. This result indicates that SwitchPrompt effectively reduces the need for domain-specific language model pre-training.
How (Not) To Evaluate Explanation Quality
Oct 13, 2022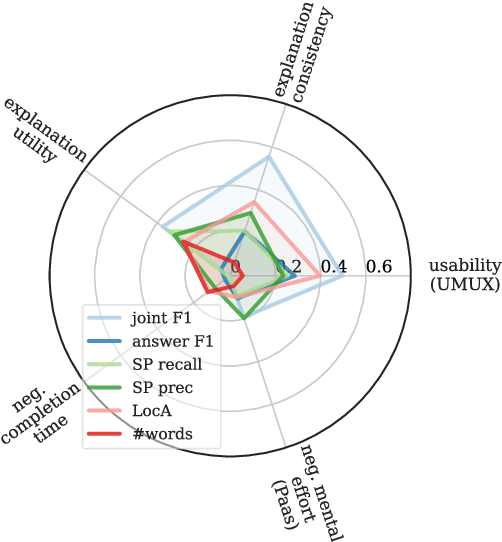

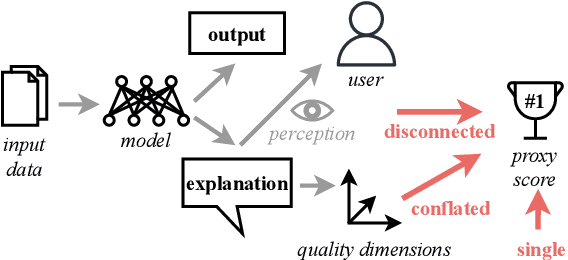

The importance of explainability is increasingly acknowledged in natural language processing. However, it is still unclear how the quality of explanations can be assessed effectively. The predominant approach is to compare proxy scores (such as BLEU or explanation F1) evaluated against gold explanations in the dataset. The assumption is that an increase of the proxy score implies a higher utility of explanations to users. In this paper, we question this assumption. In particular, we (i) formulate desired characteristics of explanation quality that apply across tasks and domains, (ii) point out how current evaluation practices violate those characteristics, and (iii) propose actionable guidelines to overcome obstacles that limit today's evaluation of explanation quality and to enable the development of explainable systems that provide tangible benefits for human users. We substantiate our theoretical claims (i.e., the lack of validity and temporal decline of currently-used proxy scores) with empirical evidence from a crowdsourcing case study in which we investigate the explanation quality of state-of-the-art explainable question answering systems.
Multilingual Normalization of Temporal Expressions with Masked Language Models
May 20, 2022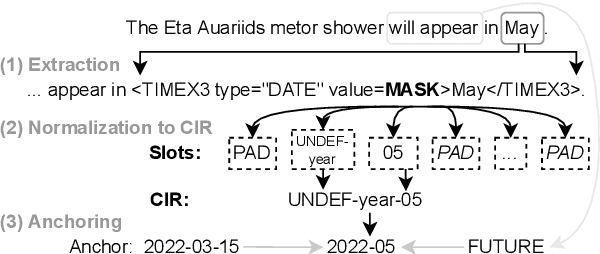
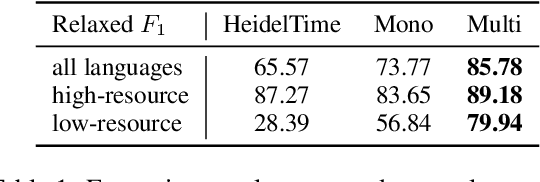
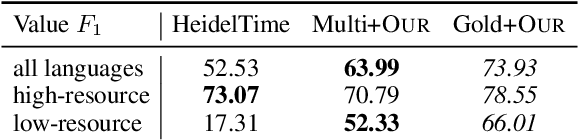
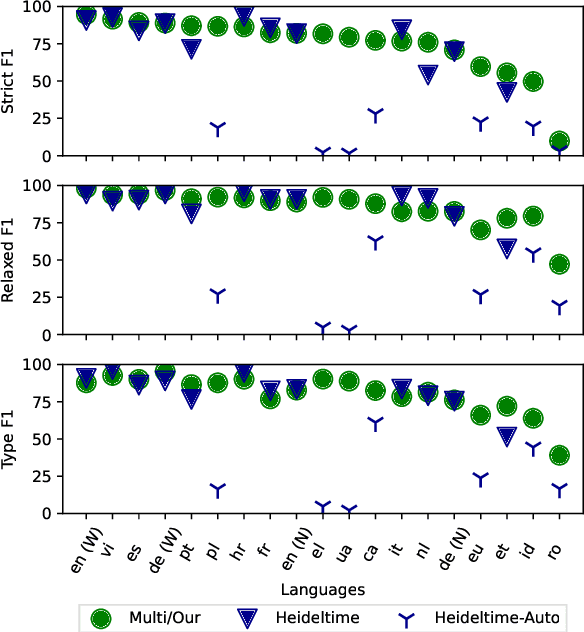
The detection and normalization of temporal expressions is an important task and a preprocessing step for many applications. However, prior work on normalization is rule-based, which severely limits the applicability in real-world multilingual settings, due to the costly creation of new rules. We propose a novel neural method for normalizing temporal expressions based on masked language modeling. Our multilingual method outperforms prior rule-based systems in many languages, and in particular, for low-resource languages with performance improvements of up to 35 F1 on average compared to the state of the art.
Human Interpretation of Saliency-based Explanation Over Text
Jan 27, 2022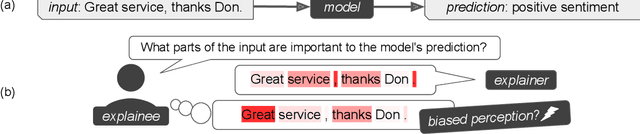

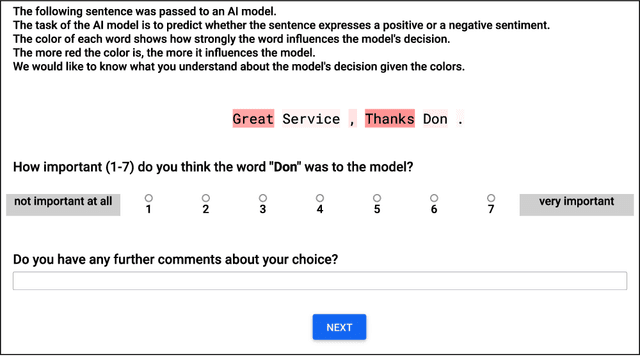
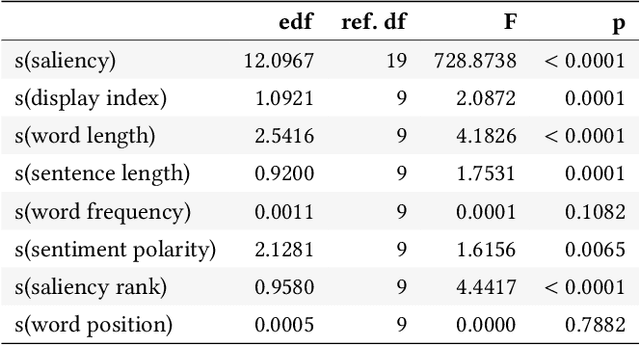
While a lot of research in explainable AI focuses on producing effective explanations, less work is devoted to the question of how people understand and interpret the explanation. In this work, we focus on this question through a study of saliency-based explanations over textual data. Feature-attribution explanations of text models aim to communicate which parts of the input text were more influential than others towards the model decision. Many current explanation methods, such as gradient-based or Shapley value-based methods, provide measures of importance which are well-understood mathematically. But how does a person receiving the explanation (the explainee) comprehend it? And does their understanding match what the explanation attempted to communicate? We empirically investigate the effect of various factors of the input, the feature-attribution explanation, and visualization procedure, on laypeople's interpretation of the explanation. We query crowdworkers for their interpretation on tasks in English and German, and fit a GAMM model to their responses considering the factors of interest. We find that people often mis-interpret the explanations: superficial and unrelated factors, such as word length, influence the explainees' importance assignment despite the explanation communicating importance directly. We then show that some of this distortion can be attenuated: we propose a method to adjust saliencies based on model estimates of over- and under-perception, and explore bar charts as an alternative to heatmap saliency visualization. We find that both approaches can attenuate the distorting effect of specific factors, leading to better-calibrated understanding of the explanation.