 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOD-VIRAT: A Large-Scale Benchmark for Object Detection in Realistic Surveillance Environments
Jul 16, 2025Realistic human surveillance datasets are crucial for training and evaluating computer vision models under real-world conditions, facilitating the development of robust algorithms for human and human-interacting object detection in complex environments. These datasets need to offer diverse and challenging data to enable a comprehensive assessment of model performance and the creation of more reliable surveillance systems for public safety. To this end, we present two visual object detection benchmarks named OD-VIRAT Large and OD-VIRAT Tiny, aiming at advancing visual understanding tasks in surveillance imagery. The video sequences in both benchmarks cover 10 different scenes of human surveillance recorded from significant height and distance. The proposed benchmarks offer rich annotations of bounding boxes and categories, where OD-VIRAT Large has 8.7 million annotated instances in 599,996 images and OD-VIRAT Tiny has 288,901 annotated instances in 19,860 images. This work also focuses on benchmarking state-of-the-art object detection architectures, including RETMDET, YOLOX, RetinaNet, DETR, and Deformable-DETR on this object detection-specific variant of VIRAT dataset. To the best of our knowledge, it is the first work to examine the performance of these recently published state-of-the-art object detection architectures on realistic surveillance imagery under challenging conditions such as complex backgrounds, occluded objects, and small-scale objects. The proposed benchmarking and experimental settings will help in providing insights concerning the performance of selected object detection models and set the base for developing more efficient and robust object detection architectures.
DVFL-Net: A Lightweight Distilled Video Focal Modulation Network for Spatio-Temporal Action Recognition
Jul 16, 2025The landscape of video recognition has evolved significantly, shifting from traditional Convolutional Neural Networks (CNNs) to Transformer-based architectures for improved accuracy. While 3D CNNs have been effective at capturing spatiotemporal dynamics, recent Transformer models leverage self-attention to model long-range spatial and temporal dependencies. Despite achieving state-of-the-art performance on major benchmarks, Transformers remain computationally expensive, particularly with dense video data. To address this, we propose a lightweight Video Focal Modulation Network, DVFL-Net, which distills spatiotemporal knowledge from a large pre-trained teacher into a compact nano student model, enabling efficient on-device deployment. DVFL-Net utilizes knowledge distillation and spatial-temporal feature modulation to significantly reduce computation while preserving high recognition performance. We employ forward Kullback-Leibler (KL) divergence alongside spatio-temporal focal modulation to effectively transfer both local and global context from the Video-FocalNet Base (teacher) to the proposed VFL-Net (student). We evaluate DVFL-Net on UCF50, UCF101, HMDB51, SSV2, and Kinetics-400, benchmarking it against recent state-of-the-art methods in Human Action Recognition (HAR). Additionally, we conduct a detailed ablation study analyzing the impact of forward KL divergence. The results confirm the superiority of DVFL-Net in achieving an optimal balance between performance and efficiency, demonstrating lower memory usage, reduced GFLOPs, and strong accuracy, making it a practical solution for real-time HAR applications.
Hierarchical Multi-Stage Transformer Architecture for Context-Aware Temporal Action Localization
Jul 08, 2025Inspired by the recent success of transformers and multi-stage architectures in video recognition and object detection domains. We thoroughly explore the rich spatio-temporal properties of transformers within a multi-stage architecture paradigm for the temporal action localization (TAL) task. This exploration led to the development of a hierarchical multi-stage transformer architecture called PCL-Former, where each subtask is handled by a dedicated transformer module with a specialized loss function. Specifically, the Proposal-Former identifies candidate segments in an untrimmed video that may contain actions, the Classification-Former classifies the action categories within those segments, and the Localization-Former precisely predicts the temporal boundaries (i.e., start and end) of the action instances. To evaluate the performance of our method, we have conducted extensive experiments on three challenging benchmark datasets: THUMOS-14, ActivityNet-1.3, and HACS Segments. We also conducted detailed ablation experiments to assess the impact of each individual module of our PCL-Former. The obtained quantitative results validate the effectiveness of the proposed PCL-Former, outperforming state-of-the-art TAL approaches by 2.8%, 1.2%, and 4.8% on THUMOS14, ActivityNet-1.3, and HACS datasets, respectively.
ViT-ReT: Vision and Recurrent Transformer Neural Networks for Human Activity Recognition in Videos
Aug 25, 2022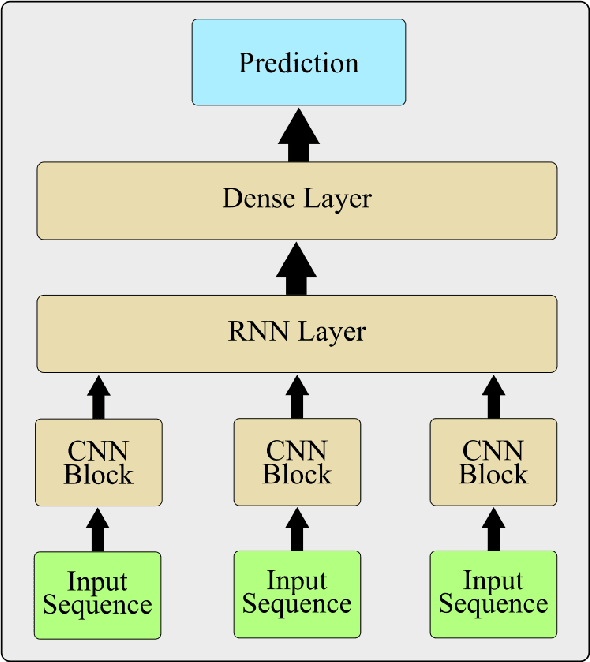
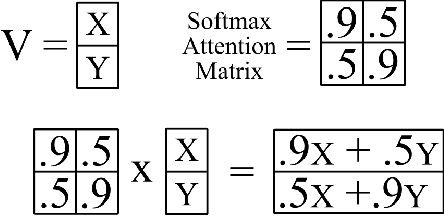
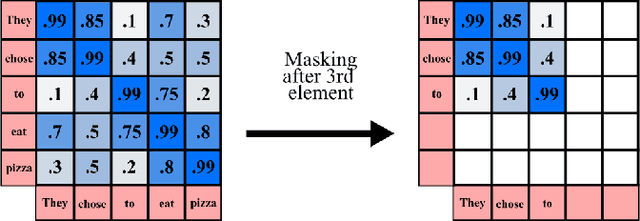
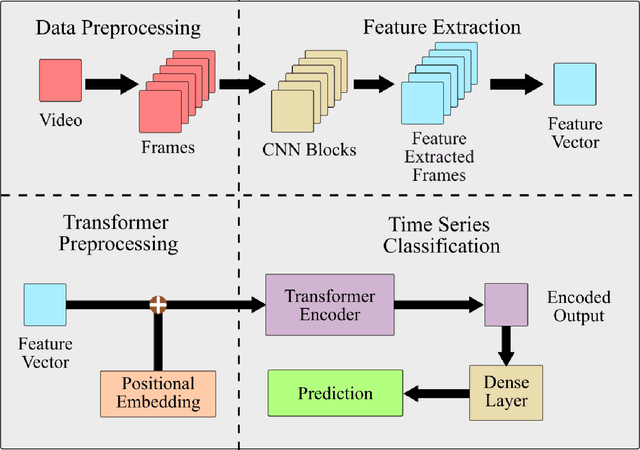
Human activity recognition is an emerging and important area in computer vision which seeks to determine the activity an individual or group of individuals are performing. The applications of this field ranges from generating highlight videos in sports, to intelligent surveillance and gesture recognition. Most activity recognition systems rely on a combination of convolutional neural networks (CNNs) to perform feature extraction from the data and recurrent neural networks (RNNs) to determine the time dependent nature of the data. This paper proposes and designs two transformer neural networks for human activity recognition: a recurrent transformer (ReT), a specialized neural network used to make predictions on sequences of data, as well as a vision transformer (ViT), a transformer optimized for extracting salient features from images, to improve speed and scalability of activity recognition. We have provided an extensive comparison of the proposed transformer neural networks with the contemporary CNN and RNN-based human activity recognition models in terms of speed and accuracy.
Human Activity Recognition Using Cascaded Dual Attention CNN and Bi-Directional GRU Framework
Aug 09, 2022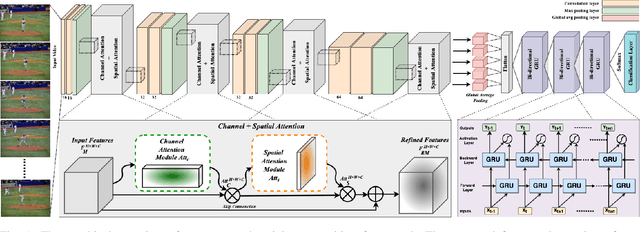
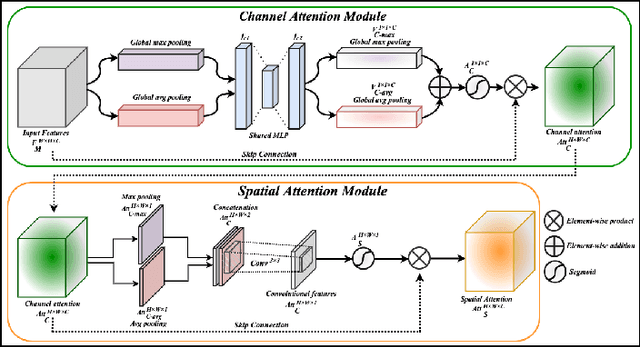

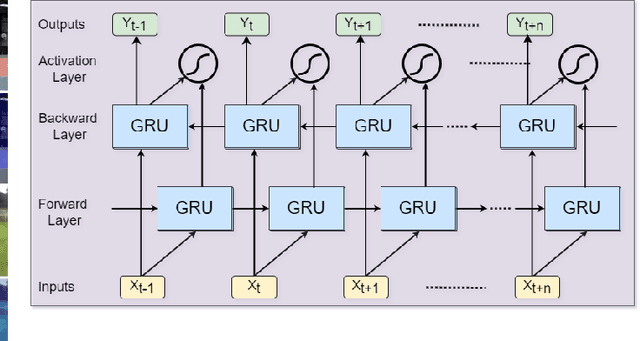
Vision-based human activity recognition has emerged as one of the essential research areas in video analytics domain. Over the last decade, numerous advanced deep learning algorithms have been introduced to recognize complex human actions from video streams. These deep learning algorithms have shown impressive performance for the human activity recognition task. However, these newly introduced methods either exclusively focus on model performance or the effectiveness of these models in terms of computational efficiency and robustness, resulting in a biased tradeoff in their proposals to deal with challenging human activity recognition problem. To overcome the limitations of contemporary deep learning models for human activity recognition, this paper presents a computationally efficient yet generic spatial-temporal cascaded framework that exploits the deep discriminative spatial and temporal features for human activity recognition. For efficient representation of human actions, we have proposed an efficient dual attentional convolutional neural network (CNN) architecture that leverages a unified channel-spatial attention mechanism to extract human-centric salient features in video frames. The dual channel-spatial attention layers together with the convolutional layers learn to be more attentive in the spatial receptive fields having objects over the number of feature maps. The extracted discriminative salient features are then forwarded to stacked bi-directional gated recurrent unit (Bi-GRU) for long-term temporal modeling and recognition of human actions using both forward and backward pass gradient learning. Extensive experiments are conducted, where the obtained results show that the proposed framework attains an improvement in execution time up to 167 times in terms of frames per second as compared to most of the contemporary action recognition methods.