 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation and Processing of German Court Decisions from Open Legal Data
Jan 04, 2026The availability of structured legal data is important for advancing Natural Language Processing (NLP) techniques for the German legal system. One of the most widely used datasets, Open Legal Data, provides a large-scale collection of German court decisions. While the metadata in this raw dataset is consistently structured, the decision texts themselves are inconsistently formatted and often lack clearly marked sections. Reliable separation of these sections is important not only for rhetorical role classification but also for downstream tasks such as retrieval and citation analysis. In this work, we introduce a cleaned and sectioned dataset of 251,038 German court decisions derived from the official Open Legal Data dataset. We systematically separated three important sections in German court decisions, namely Tenor (operative part of the decision), Tatbestand (facts of the case), and Entscheidungsgründe (judicial reasoning), which are often inconsistently represented in the original dataset. To ensure the reliability of our extraction process, we used Cochran's formula with a 95% confidence level and a 5% margin of error to draw a statistically representative random sample of 384 cases, and manually verified that all three sections were correctly identified. We also extracted the Rechtsmittelbelehrung (appeal notice) as a separate field, since it is a procedural instruction and not part of the decision itself. The resulting corpus is publicly available in the JSONL format, making it an accessible resource for further research on the German legal system.
* Accepted and published as a research article in Legal Knowledge and Information Systems (JURIX 2025 proceedings, IOS Press). Pages 276--281
Investigating Sparsity in Recurrent Neural Networks
Jul 30, 2024



In the past few years, neural networks have evolved from simple Feedforward Neural Networks to more complex neural networks, such as Convolutional Neural Networks and Recurrent Neural Networks. Where CNNs are a perfect fit for tasks where the sequence is not important such as image recognition, RNNs are useful when order is important such as machine translation. An increasing number of layers in a neural network is one way to improve its performance, but it also increases its complexity making it much more time and power-consuming to train. One way to tackle this problem is to introduce sparsity in the architecture of the neural network. Pruning is one of the many methods to make a neural network architecture sparse by clipping out weights below a certain threshold while keeping the performance near to the original. Another way is to generate arbitrary structures using random graphs and embed them between an input and output layer of an Artificial Neural Network. Many researchers in past years have focused on pruning mainly CNNs, while hardly any research is done for the same in RNNs. The same also holds in creating sparse architectures for RNNs by generating and embedding arbitrary structures. Therefore, this thesis focuses on investigating the effects of the before-mentioned two techniques on the performance of RNNs. We first describe the pruning of RNNs, its impact on the performance of RNNs, and the number of training epochs required to regain accuracy after the pruning is performed. Next, we continue with the creation and training of Sparse Recurrent Neural Networks and identify the relation between the performance and the graph properties of its underlying arbitrary structure. We perform these experiments on RNN with Tanh nonlinearity (RNN-Tanh), RNN with ReLU nonlinearity (RNN-ReLU), GRU, and LSTM. Finally, we analyze and discuss the results achieved from both the experiments.
German BERT Model for Legal Named Entity Recognition
Mar 07, 2023



The use of BERT, one of the most popular language models, has led to improvements in many Natural Language Processing (NLP) tasks. One such task is Named Entity Recognition (NER) i.e. automatic identification of named entities such as location, person, organization, etc. from a given text. It is also an important base step for many NLP tasks such as information extraction and argumentation mining. Even though there is much research done on NER using BERT and other popular language models, the same is not explored in detail when it comes to Legal NLP or Legal Tech. Legal NLP applies various NLP techniques such as sentence similarity or NER specifically on legal data. There are only a handful of models for NER tasks using BERT language models, however, none of these are aimed at legal documents in German. In this paper, we fine-tune a popular BERT language model trained on German data (German BERT) on a Legal Entity Recognition (LER) dataset. To make sure our model is not overfitting, we performed a stratified 10-fold cross-validation. The results we achieve by fine-tuning German BERT on the LER dataset outperform the BiLSTM-CRF+ model used by the authors of the same LER dataset. Finally, we make the model openly available via HuggingFace.
* Presented at ICAART 2023
Experiments on Properties of Hidden Structures of Sparse Neural Networks
Jul 27, 2021
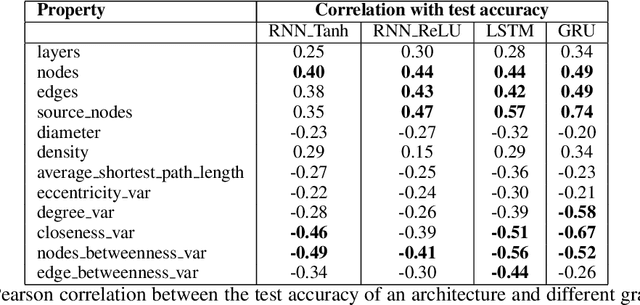
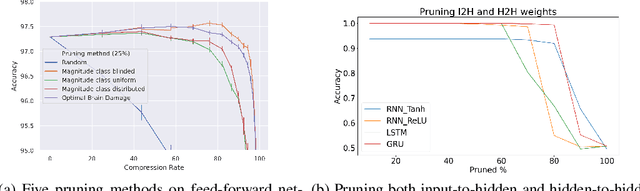
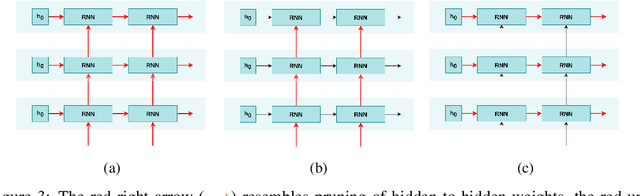
Sparsity in the structure of Neural Networks can lead to less energy consumption, less memory usage, faster computation times on convenient hardware, and automated machine learning. If sparsity gives rise to certain kinds of structure, it can explain automatically obtained features during learning. We provide insights into experiments in which we show how sparsity can be achieved through prior initialization, pruning, and during learning, and answer questions on the relationship between the structure of Neural Networks and their performance. This includes the first work of inducing priors from network theory into Recurrent Neural Networks and an architectural performance prediction during a Neural Architecture Search. Within our experiments, we show how magnitude class blinded pruning achieves 97.5% on MNIST with 80% compression and re-training, which is 0.5 points more than without compression, that magnitude class uniform pruning is significantly inferior to it and how a genetic search enhanced with performance prediction achieves 82.4% on CIFAR10. Further, performance prediction for Recurrent Networks learning the Reber grammar shows an $R^2$ of up to 0.81 given only structural information.