 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-NFS: Bandwidth-adaptive Streaming of Dynamic Gaussian Splats and Point Clouds
Jun 04, 2026Dynamic 3D Gaussian Splatting (3DGS) holds great promise as a 3D video streaming technology since it can represent complex 3D scenes with high fidelity. In this approach, every frame in a 3D video represents the environment as a collection of Gaussians with position and other attributes such as scale, rotation, opacity, and color. Frames capture fine details, permit views from any arbitrary perspective, but are an order of magnitude, or more, larger than 2D video frames. A line of recent work has explored how to compress dynamic 3DGS frames, but these approaches are often slow, in part because their compression techniques are not amenable to efficient acceleration. GS-NFS accelerates dynamic 3DGS compression and decompression on a GPU, to the point where it can encode and decode at full frame rate. It achieves this by developing novel GPU-based parallelizations of existing algorithms for encoding both positions and attributes of Gaussians. As a result, it is 1-2 orders of magnitude faster than the state-of-the-art in encoding and decoding a frame, while offering competitive compression performance and rendering quality.
A Collaborative Process Parameter Recommender System for Fleets of Networked Manufacturing Machines -- with Application to 3D Printing
Jun 13, 2025Fleets of networked manufacturing machines of the same type, that are collocated or geographically distributed, are growing in popularity. An excellent example is the rise of 3D printing farms, which consist of multiple networked 3D printers operating in parallel, enabling faster production and efficient mass customization. However, optimizing process parameters across a fleet of manufacturing machines, even of the same type, remains a challenge due to machine-to-machine variability. Traditional trial-and-error approaches are inefficient, requiring extensive testing to determine optimal process parameters for an entire fleet. In this work, we introduce a machine learning-based collaborative recommender system that optimizes process parameters for each machine in a fleet by modeling the problem as a sequential matrix completion task. Our approach leverages spectral clustering and alternating least squares to iteratively refine parameter predictions, enabling real-time collaboration among the machines in a fleet while minimizing the number of experimental trials. We validate our method using a mini 3D printing farm consisting of ten 3D printers for which we optimize acceleration and speed settings to maximize print quality and productivity. Our approach achieves significantly faster convergence to optimal process parameters compared to non-collaborative matrix completion.
Oort: Informed Participant Selection for Scalable Federated Learning
Oct 12, 2020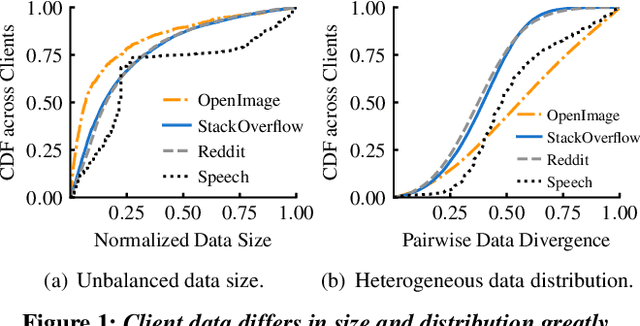
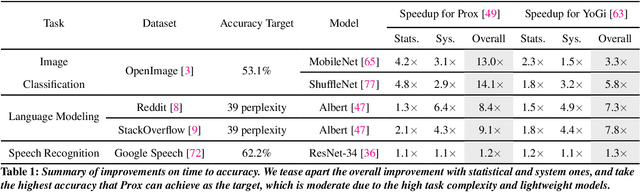
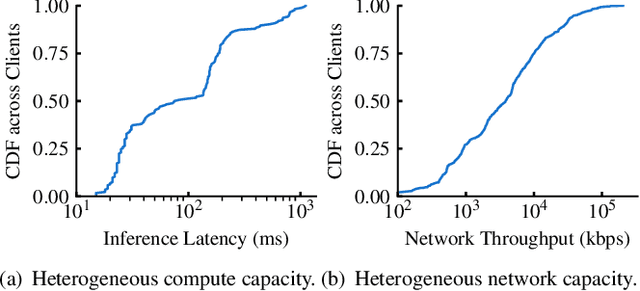
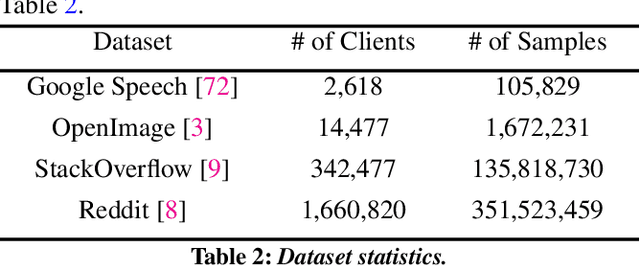
Federated Learning (FL) is an emerging direction in distributed machine learning (ML) that enables in-situ model training and testing on edge data. Despite having the same end goals as traditional ML, FL executions differ significantly in scale, spanning thousands to millions of participating devices. As a result, data characteristics and device capabilities vary widely across clients. Yet, existing efforts randomly select FL participants, which leads to poor model and system efficiency. In this paper, we propose Kuiper to improve the performance of federated training and testing with guided participant selection. With an aim to improve time-to-accuracy performance in model training, Kuiper prioritizes the use of those clients who have both data that offers the greatest utility in improving model accuracy and the capability to run training quickly. To enable FL developers to interpret their results in model testing, Kuiper enforces their requirements on the distribution of participant data while improving the duration of federated testing by cherry-picking clients. Our evaluation shows that, compared to existing participant selection mechanisms, Kuiper improves time-to-accuracy performance by 1.2x-14.1x and final model accuracy by 1.3%-9.8%, while efficiently enforcing developer requirements on data distributions at the scale of millions of clients.