 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinical Evaluation of a Low-Cost Strain Gauge Respiration Belt and Machine Learning to Detect Sleep Apnea
Jan 07, 2021
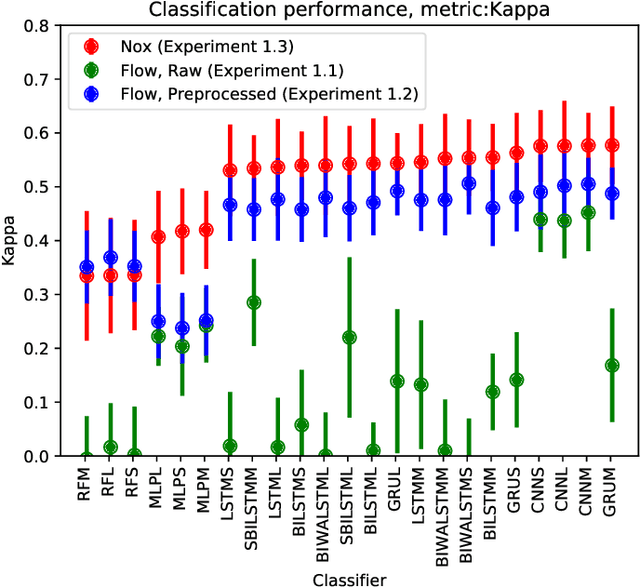

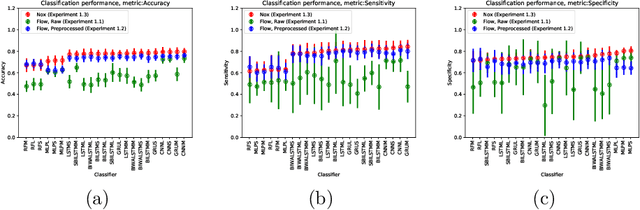
Sleep apnea is a serious and severely under-diagnosed sleep-related respiration disorder characterized by repeated disrupted breathing events during sleep. It is diagnosed via polysomnography which is an expensive test conducted in a sleep lab requiring sleep experts to manually score the recorded data. Since the symptoms of sleep apnea are often ambiguous, it is difficult for a physician to decide whether to prescribe polysomnography. In this study, we investigate whether helpful information can be obtained by collecting and automatically analysing sleep data using a smartphone and an inexpensive strain gauge respiration belt. We evaluate how accurately we can detect sleep apnea with wide variety of machine learning techniques with data from a clinical study with 49 overnight sleep recordings. With less than one hour of training, we can distinguish between normal and apneic minutes with an accuracy, sensitivity, and specificity of 0.7609, 0.7833, and 0.7217, respectively. These results can be achieved even if we train only on high-quality data from an entirely separate, clinically certified sensor, which has the potential to substantially reduce the cost of data collection. Data from a complete night can be analyzed in about one second on a smartphone.
My Health Sensor, my Classifier: Adapting a Trained Classifier to Unlabeled End-User Data
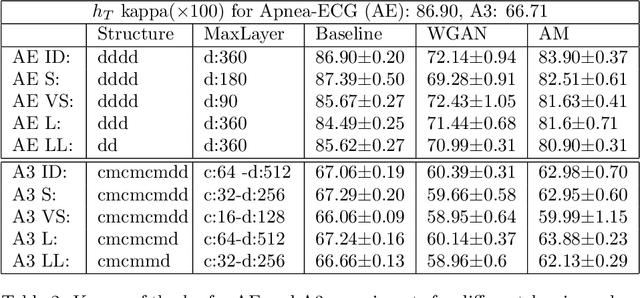
Sep 22, 2020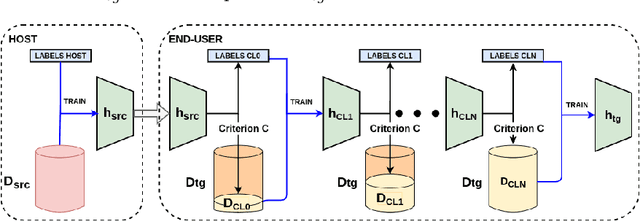
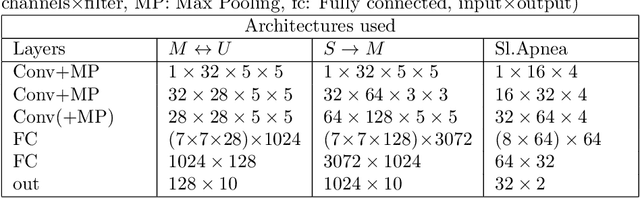


In this work, we present an approach for unsupervised domain adaptation (DA) with the constraint, that the labeled source data are not directly available, and instead only access to a classifier trained on the source data is provided. Our solution, iteratively labels only high confidence sub-regions of the target data distribution, based on the belief of the classifier. Then it iteratively learns new classifiers from the expanding high-confidence dataset. The goal is to apply the proposed approach on DA for the task of sleep apnea detection and achieve personalization based on the needs of the patient. In a series of experiments with both open and closed sleep monitoring datasets, the proposed approach is applied to data from different sensors, for DA between the different datasets. The proposed approach outperforms in all experiments the classifier trained in the source domain, with an improvement of the kappa coefficient that varies from 0.012 to 0.242. Additionally, our solution is applied to digit classification DA between three well established digit datasets, to investigate the generalizability of the approach, and to allow for comparison with related work. Even without direct access to the source data, it achieves good results, and outperforms several well established unsupervised DA methods.
Learning Realistic Patterns from Unrealistic Stimuli: Generalization and Data Anonymization
Sep 21, 2020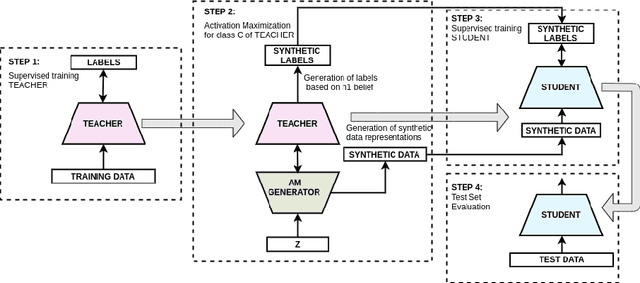
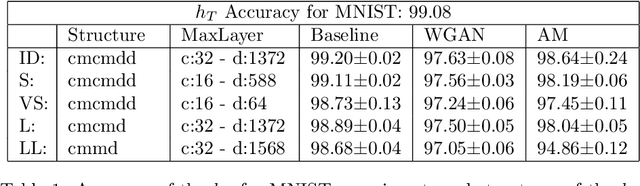
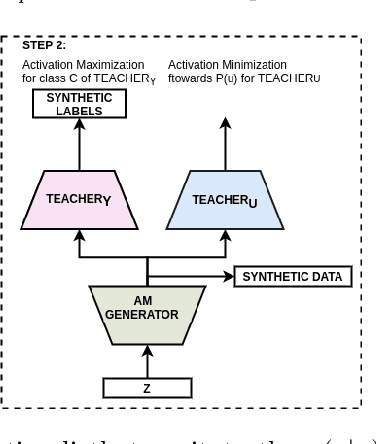
Good training data is a prerequisite to develop useful ML applications. However, in many domains existing data sets cannot be shared due to privacy regulations (e.g., from medical studies). This work investigates a simple yet unconventional approach for anonymized data synthesis to enable third parties to benefit from such private data. We explore the feasibility of learning implicitly from unrealistic, task-relevant stimuli, which are synthesized by exciting the neurons of a trained deep neural network (DNN). As such, neuronal excitation serves as a pseudo-generative model. The stimuli data is used to train new classification models. Furthermore, we extend this framework to inhibit representations that are associated with specific individuals. We use sleep monitoring data from both an open and a large closed clinical study and evaluate whether (1) end-users can create and successfully use customized classification models for sleep apnea detection, and (2) the identity of participants in the study is protected. Extensive comparative empirical investigation shows that different algorithms trained on the stimuli are able generalize successfully on the same task as the original model. However, architectural and algorithmic similarity between new and original models play an important role in performance. For similar architectures, the performance is close to that of using the true data (e.g., Accuracy difference of 0.56\%, Kappa coefficient difference of 0.03-0.04). Further experiments show that the stimuli can to a large extent successfully anonymize participants of the clinical studies.