 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Generation in Dialogue using Lexicalized and Delexicalized Data
Apr 21, 2017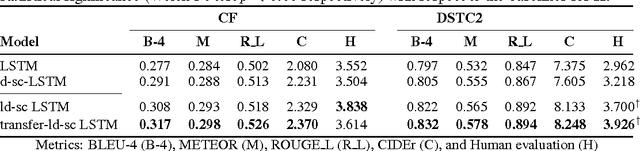
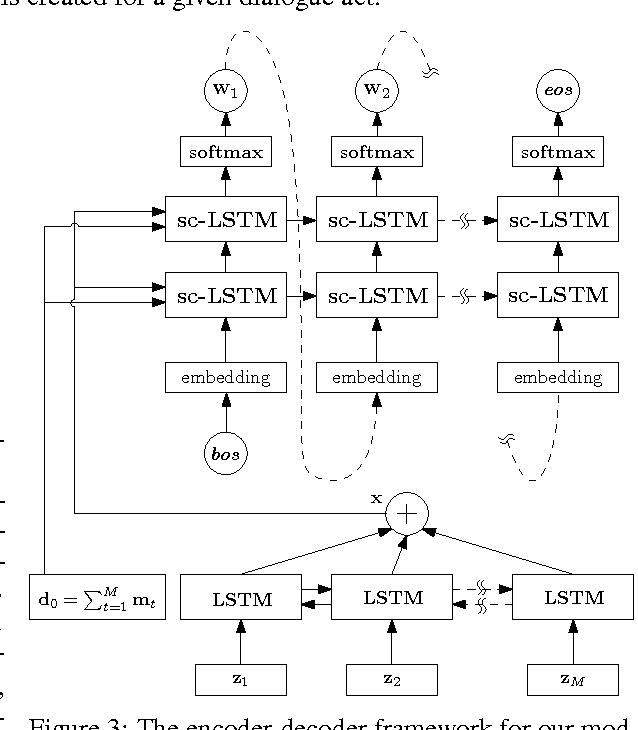
Natural language generation plays a critical role in spoken dialogue systems. We present a new approach to natural language generation for task-oriented dialogue using recurrent neural networks in an encoder-decoder framework. In contrast to previous work, our model uses both lexicalized and delexicalized components i.e. slot-value pairs for dialogue acts, with slots and corresponding values aligned together. This allows our model to learn from all available data including the slot-value pairing, rather than being restricted to delexicalized slots. We show that this helps our model generate more natural sentences with better grammar. We further improve our model's performance by transferring weights learnt from a pretrained sentence auto-encoder. Human evaluation of our best-performing model indicates that it generates sentences which users find more appealing.
Frames: A Corpus for Adding Memory to Goal-Oriented Dialogue Systems
Apr 13, 2017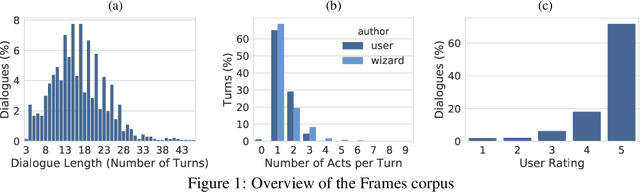

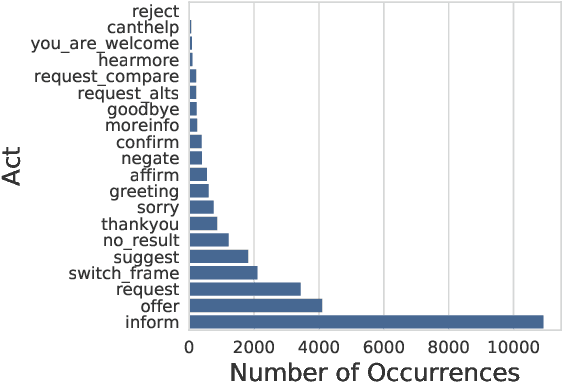

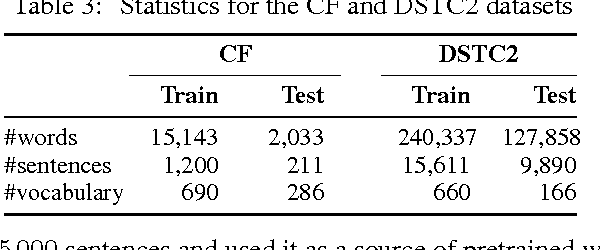
This paper presents the Frames dataset (Frames is available at http://datasets.maluuba.com/Frames), a corpus of 1369 human-human dialogues with an average of 15 turns per dialogue. We developed this dataset to study the role of memory in goal-oriented dialogue systems. Based on Frames, we introduce a task called frame tracking, which extends state tracking to a setting where several states are tracked simultaneously. We propose a baseline model for this task. We show that Frames can also be used to study memory in dialogue management and information presentation through natural language generation.
Policy Networks with Two-Stage Training for Dialogue Systems
Sep 12, 2016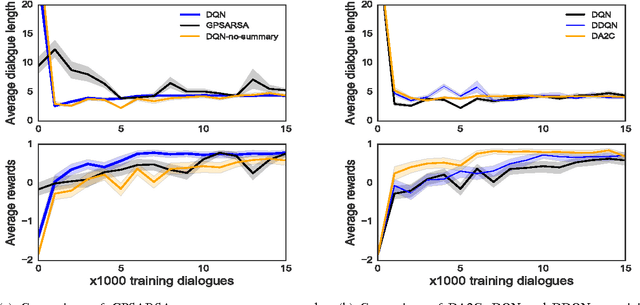
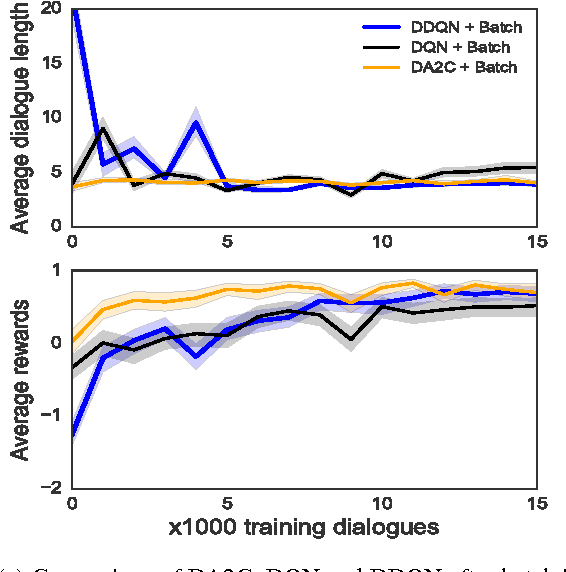
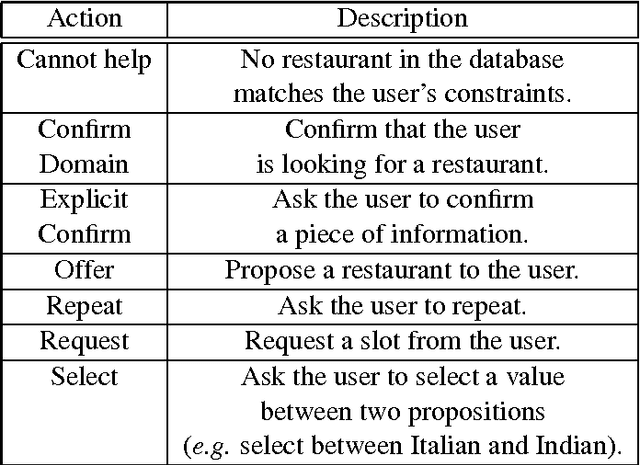
In this paper, we propose to use deep policy networks which are trained with an advantage actor-critic method for statistically optimised dialogue systems. First, we show that, on summary state and action spaces, deep Reinforcement Learning (RL) outperforms Gaussian Processes methods. Summary state and action spaces lead to good performance but require pre-engineering effort, RL knowledge, and domain expertise. In order to remove the need to define such summary spaces, we show that deep RL can also be trained efficiently on the original state and action spaces. Dialogue systems based on partially observable Markov decision processes are known to require many dialogues to train, which makes them unappealing for practical deployment. We show that a deep RL method based on an actor-critic architecture can exploit a small amount of data very efficiently. Indeed, with only a few hundred dialogues collected with a handcrafted policy, the actor-critic deep learner is considerably bootstrapped from a combination of supervised and batch RL. In addition, convergence to an optimal policy is significantly sped up compared to other deep RL methods initialized on the data with batch RL. All experiments are performed on a restaurant domain derived from the Dialogue State Tracking Challenge 2 (DSTC2) dataset.
* SIGDial 2016 (Submitted: May 2016; Accepted: Jun 30, 2016)