 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations from 3D Gaussian Splats
May 28, 20263D Gaussian Splatting (3DGS) is a recent approach for scene rendering. Although primarily designed for view synthesis, its potential for scene understanding tasks remains underexplored. In this work, we conduct a comparative evaluation of various geometric deep learning architectures for the classification of 3D scenes represented using Gaussian Splatting. We benchmark point-based and graph-based models across both traditional point cloud datasets and dedicated Gaussian Splatting datasets. Scenes are embedded into latent representations, which are evaluated through end-to-end classification, linear probing, and clustering analysis. Our study provides insight into the suitability of different geometry-aware architectures and input feature configurations for learning effective 3D Gaussian Splat representations. The results highlight consistent differences between architectural families and reveal the impact of Gaussian-specific attributes on the quality of representation.
Snapshot Spectral Clustering -- a costless approach to deep clustering ensembles generation
Jul 17, 2023



Despite tremendous advancements in Artificial Intelligence, learning from large sets of data in an unsupervised manner remains a significant challenge. Classical clustering algorithms often fail to discover complex dependencies in large datasets, especially considering sparse, high-dimensional spaces. However, deep learning techniques proved to be successful when dealing with large quantities of data, efficiently reducing their dimensionality without losing track of underlying information. Several interesting advancements have already been made to combine deep learning and clustering. Still, the idea of enhancing the clustering results by combining multiple views of the data generated by deep neural networks appears to be insufficiently explored yet. This paper aims to investigate this direction and bridge the gap between deep neural networks, clustering techniques and ensemble learning methods. To achieve this goal, we propose a novel deep clustering ensemble method - Snapshot Spectral Clustering, designed to maximize the gain from combining multiple data views while minimizing the computational costs of creating the ensemble. Comparative analysis and experiments described in this paper prove the proposed concept, while the conducted hyperparameter study provides a valuable intuition to follow when selecting proper values.
Hierarchy of Groups Evaluation Using Different F-score Variants
Mar 28, 2016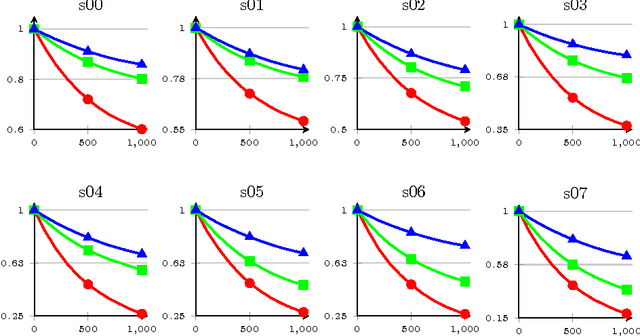
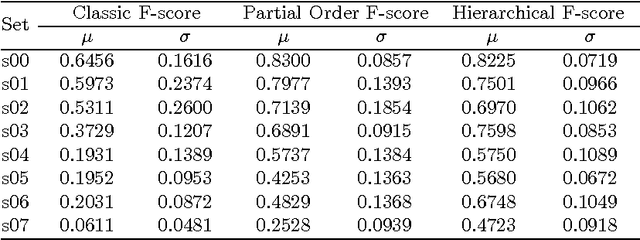
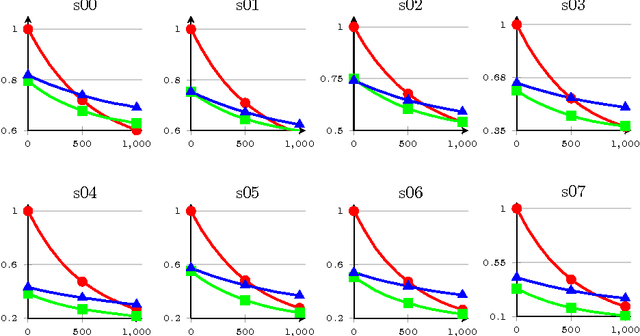
The paper presents a cursory examination of clustering, focusing on a rarely explored field of hierarchy of clusters. Based on this, a short discussion of clustering quality measures is presented and the F-score measure is examined more deeply. As there are no attempts to assess the quality for hierarchies of clusters, three variants of the F-Score based index are presented: classic, hierarchical and partial order. The partial order index is the authors' approach to the subject. Conducted experiments show the properties of the considered measures. In conclusions, the strong and weak sides of each variant are presented.
* Presented on ACIIDS2016 conference https://aciids.pwr.edu.pl/. The final publication is available at Springer via http://dx.doi.org/10.1007/978-3-662-49381-6_63