 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-scale Pedestrian Detection Based on Somatic Topology Localization and Temporal Feature Aggregation
Jul 04, 2018
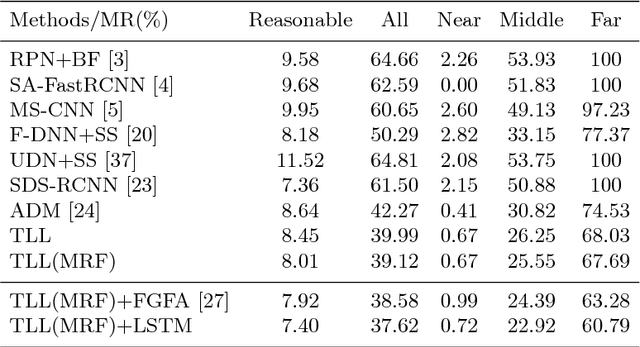
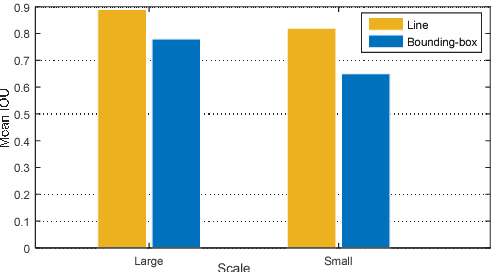
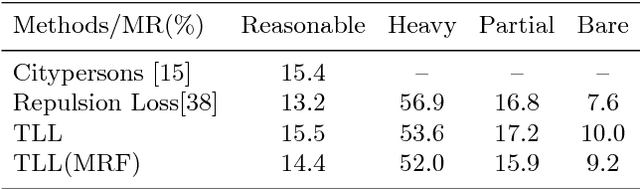
A critical issue in pedestrian detection is to detect small-scale objects that will introduce feeble contrast and motion blur in images and videos, which in our opinion should partially resort to deep-rooted annotation bias. Motivated by this, we propose a novel method integrated with somatic topological line localization (TLL) and temporal feature aggregation for detecting multi-scale pedestrians, which works particularly well with small-scale pedestrians that are relatively far from the camera. Moreover, a post-processing scheme based on Markov Random Field (MRF) is introduced to eliminate ambiguities in occlusion cases. Applying with these methodologies comprehensively, we achieve best detection performance on Caltech benchmark and improve performance of small-scale objects significantly (miss rate decreases from 74.53% to 60.79%). Beyond this, we also achieve competitive performance on CityPersons dataset and show the existence of annotation bias in KITTI dataset.
Mixed context networks for semantic segmentation
Oct 19, 2016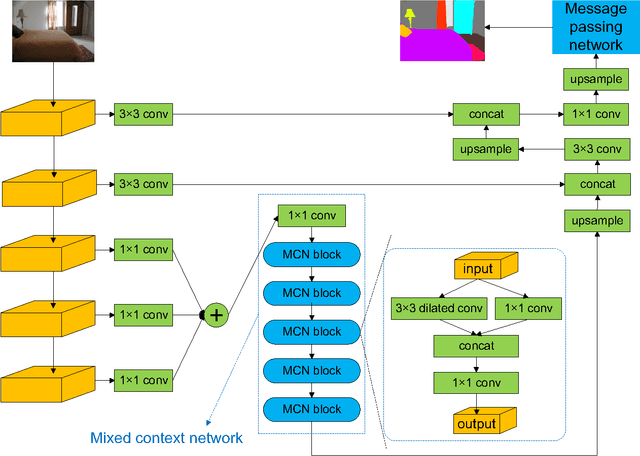
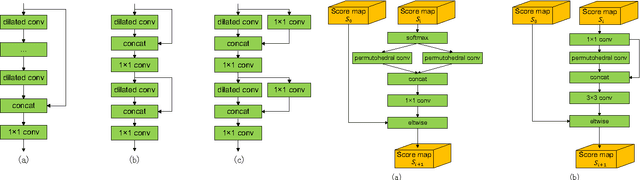

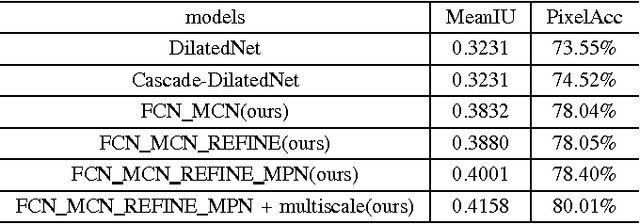
Semantic segmentation is challenging as it requires both object-level information and pixel-level accuracy. Recently, FCN-based systems gained great improvement in this area. Unlike classification networks, combining features of different layers plays an important role in these dense prediction models, as these features contains information of different levels. A number of models have been proposed to show how to use these features. However, what is the best architecture to make use of features of different layers is still a question. In this paper, we propose a module, called mixed context network, and show that our presented system outperforms most existing semantic segmentation systems by making use of this module.