 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract-and-Adaptation Network for 3D Interacting Hand Mesh Recovery
Sep 05, 2023Understanding how two hands interact with each other is a key component of accurate 3D interacting hand mesh recovery. However, recent Transformer-based methods struggle to learn the interaction between two hands as they directly utilize two hand features as input tokens, which results in distant token problem. The distant token problem represents that input tokens are in heterogeneous spaces, leading Transformer to fail in capturing correlation between input tokens. Previous Transformer-based methods suffer from the problem especially when poses of two hands are very different as they project features from a backbone to separate left and right hand-dedicated features. We present EANet, extract-and-adaptation network, with EABlock, the main component of our network. Rather than directly utilizing two hand features as input tokens, our EABlock utilizes two complementary types of novel tokens, SimToken and JoinToken, as input tokens. Our two novel tokens are from a combination of separated two hand features; hence, it is much more robust to the distant token problem. Using the two type of tokens, our EABlock effectively extracts interaction feature and adapts it to each hand. The proposed EANet achieves the state-of-the-art performance on 3D interacting hands benchmarks. The codes are available at https://github.com/jkpark0825/EANet.
Three Recipes for Better 3D Pseudo-GTs of 3D Human Mesh Estimation in the Wild
Apr 10, 2023



Recovering 3D human mesh in the wild is greatly challenging as in-the-wild (ITW) datasets provide only 2D pose ground truths (GTs). Recently, 3D pseudo-GTs have been widely used to train 3D human mesh estimation networks as the 3D pseudo-GTs enable 3D mesh supervision when training the networks on ITW datasets. However, despite the great potential of the 3D pseudo-GTs, there has been no extensive analysis that investigates which factors are important to make more beneficial 3D pseudo-GTs. In this paper, we provide three recipes to obtain highly beneficial 3D pseudo-GTs of ITW datasets. The main challenge is that only 2D-based weak supervision is allowed when obtaining the 3D pseudo-GTs. Each of our three recipes addresses the challenge in each aspect: depth ambiguity, sub-optimality of weak supervision, and implausible articulation. Experimental results show that simply re-training state-of-the-art networks with our new 3D pseudo-GTs elevates their performance to the next level without bells and whistles. The 3D pseudo-GT is publicly available in https://github.com/mks0601/NeuralAnnot_RELEASE.
Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
Mar 27, 2023Hands, one of the most dynamic parts of our body, suffer from blur due to their active movements. However, previous 3D hand mesh recovery methods have mainly focused on sharp hand images rather than considering blur due to the absence of datasets providing blurry hand images. We first present a novel dataset BlurHand, which contains blurry hand images with 3D groundtruths. The BlurHand is constructed by synthesizing motion blur from sequential sharp hand images, imitating realistic and natural motion blurs. In addition to the new dataset, we propose BlurHandNet, a baseline network for accurate 3D hand mesh recovery from a blurry hand image. Our BlurHandNet unfolds a blurry input image to a 3D hand mesh sequence to utilize temporal information in the blurry input image, while previous works output a static single hand mesh. We demonstrate the usefulness of BlurHand for the 3D hand mesh recovery from blurry images in our experiments. The proposed BlurHandNet produces much more robust results on blurry images while generalizing well to in-the-wild images. The training codes and BlurHand dataset are available at https://github.com/JaehaKim97/BlurHand_RELEASE.
Bringing Inputs to Shared Domains for 3D Interacting Hands Recovery in the Wild
Mar 23, 2023Despite recent achievements, existing 3D interacting hands recovery methods have shown results mainly on motion capture (MoCap) environments, not on in-the-wild (ITW) ones. This is because collecting 3D interacting hands data in the wild is extremely challenging, even for the 2D data. We present InterWild, which brings MoCap and ITW samples to shared domains for robust 3D interacting hands recovery in the wild with a limited amount of ITW 2D/3D interacting hands data. 3D interacting hands recovery consists of two sub-problems: 1) 3D recovery of each hand and 2) 3D relative translation recovery between two hands. For the first sub-problem, we bring MoCap and ITW samples to a shared 2D scale space. Although ITW datasets provide a limited amount of 2D/3D interacting hands, they contain large-scale 2D single hand data. Motivated by this, we use a single hand image as an input for the first sub-problem regardless of whether two hands are interacting. Hence, interacting hands of MoCap datasets are brought to the 2D scale space of single hands of ITW datasets. For the second sub-problem, we bring MoCap and ITW samples to a shared appearance-invariant space. Unlike the first sub-problem, 2D labels of ITW datasets are not helpful for the second sub-problem due to the 3D translation's ambiguity. Hence, instead of relying on ITW samples, we amplify the generalizability of MoCap samples by taking only a geometric feature without an image as an input for the second sub-problem. As the geometric feature is invariant to appearances, MoCap and ITW samples do not suffer from a huge appearance gap between the two datasets. The code is publicly available at https://github.com/facebookresearch/InterWild.
Rethinking Self-Supervised Visual Representation Learning in Pre-training for 3D Human Pose and Shape Estimation
Mar 09, 2023



Recently, a few self-supervised representation learning (SSL) methods have outperformed the ImageNet classification pre-training for vision tasks such as object detection. However, its effects on 3D human body pose and shape estimation (3DHPSE) are open to question, whose target is fixed to a unique class, the human, and has an inherent task gap with SSL. We empirically study and analyze the effects of SSL and further compare it with other pre-training alternatives for 3DHPSE. The alternatives are 2D annotation-based pre-training and synthetic data pre-training, which share the motivation of SSL that aims to reduce the labeling cost. They have been widely utilized as a source of weak-supervision or fine-tuning, but have not been remarked as a pre-training source. SSL methods underperform the conventional ImageNet classification pre-training on multiple 3DHPSE benchmarks by 7.7% on average. In contrast, despite a much less amount of pre-training data, the 2D annotation-based pre-training improves accuracy on all benchmarks and shows faster convergence during fine-tuning. Our observations challenge the naive application of the current SSL pre-training to 3DHPSE and relight the value of other data types in the pre-training aspect.
MultiAct: Long-Term 3D Human Motion Generation from Multiple Action Labels
Dec 12, 2022



We tackle the problem of generating long-term 3D human motion from multiple action labels. Two main previous approaches, such as action- and motion-conditioned methods, have limitations to solve this problem. The action-conditioned methods generate a sequence of motion from a single action. Hence, it cannot generate long-term motions composed of multiple actions and transitions between actions. Meanwhile, the motion-conditioned methods generate future motions from initial motion. The generated future motions only depend on the past, so they are not controllable by the user's desired actions. We present MultiAct, the first framework to generate long-term 3D human motion from multiple action labels. MultiAct takes account of both action and motion conditions with a unified recurrent generation system. It repetitively takes the previous motion and action label; then, it generates a smooth transition and the motion of the given action. As a result, MultiAct produces realistic long-term motion controlled by the given sequence of multiple action labels. The code will be released.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
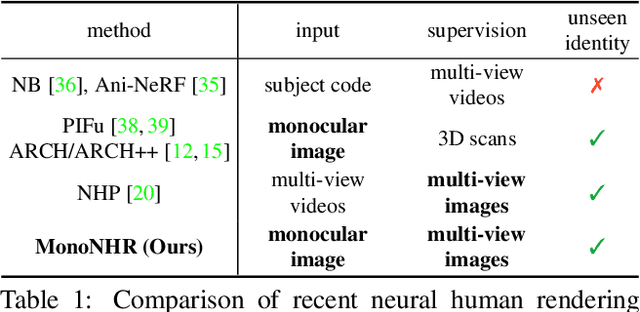
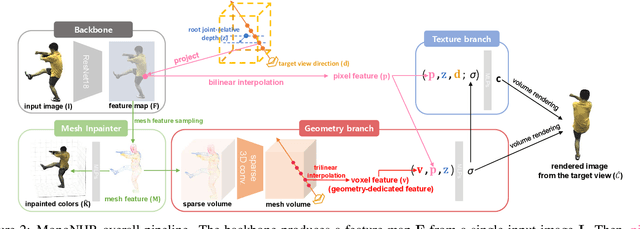
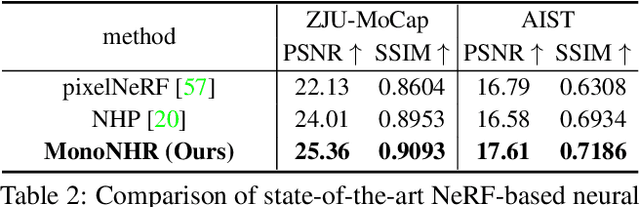
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
3D Clothed Human Reconstruction in the Wild
Jul 20, 2022
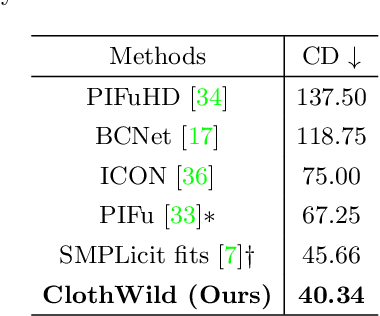
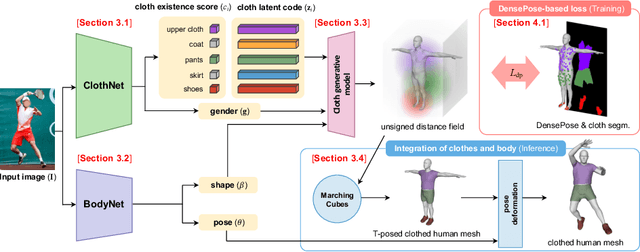
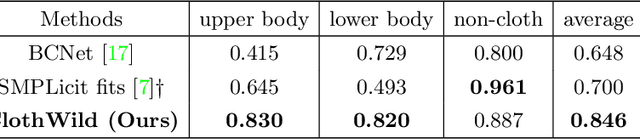
Although much progress has been made in 3D clothed human reconstruction, most of the existing methods fail to produce robust results from in-the-wild images, which contain diverse human poses and appearances. This is mainly due to the large domain gap between training datasets and in-the-wild datasets. The training datasets are usually synthetic ones, which contain rendered images from GT 3D scans. However, such datasets contain simple human poses and less natural image appearances compared to those of real in-the-wild datasets, which makes generalization of it to in-the-wild images extremely challenging. To resolve this issue, in this work, we propose ClothWild, a 3D clothed human reconstruction framework that firstly addresses the robustness on in-thewild images. First, for the robustness to the domain gap, we propose a weakly supervised pipeline that is trainable with 2D supervision targets of in-the-wild datasets. Second, we design a DensePose-based loss function to reduce ambiguities of the weak supervision. Extensive empirical tests on several public in-the-wild datasets demonstrate that our proposed ClothWild produces much more accurate and robust results than the state-of-the-art methods. The codes are available in here: https://github.com/hygenie1228/ClothWild_RELEASE.
HandOccNet: Occlusion-Robust 3D Hand Mesh Estimation Network
Mar 28, 2022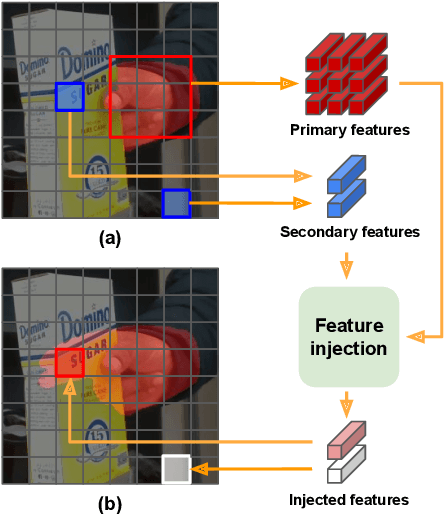
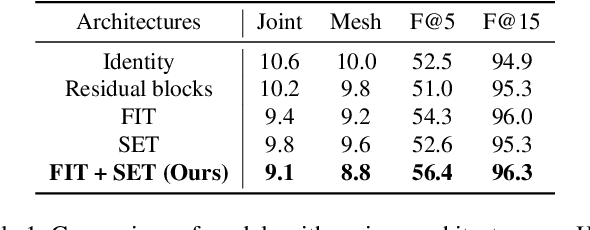
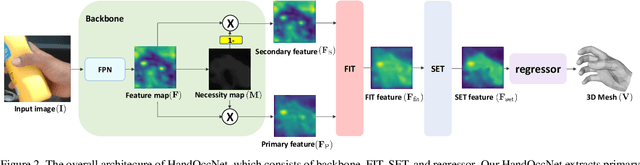

Hands are often severely occluded by objects, which makes 3D hand mesh estimation challenging. Previous works often have disregarded information at occluded regions. However, we argue that occluded regions have strong correlations with hands so that they can provide highly beneficial information for complete 3D hand mesh estimation. Thus, in this work, we propose a novel 3D hand mesh estimation network HandOccNet, that can fully exploits the information at occluded regions as a secondary means to enhance image features and make it much richer. To this end, we design two successive Transformer-based modules, called feature injecting transformer (FIT) and self- enhancing transformer (SET). FIT injects hand information into occluded region by considering their correlation. SET refines the output of FIT by using a self-attention mechanism. By injecting the hand information to the occluded region, our HandOccNet reaches the state-of-the-art performance on 3D hand mesh benchmarks that contain challenging hand-object occlusions. The codes are available in: https://github.com/namepllet/HandOccNet.
* also attached the supplementary material
3DCrowdNet: 2D Human Pose-Guided3D Crowd Human Pose and Shape Estimation in the Wild
Apr 15, 2021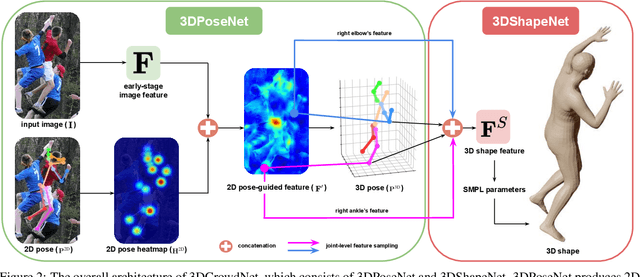

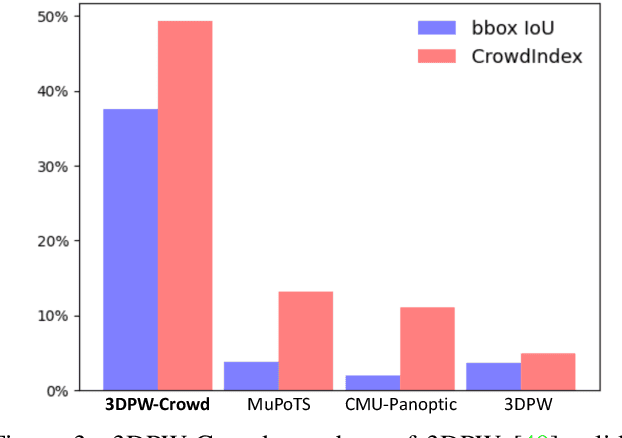
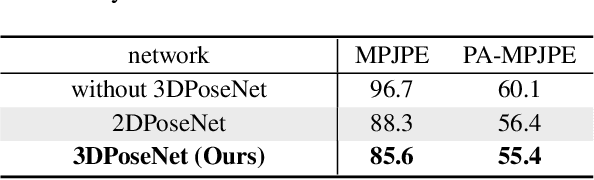
Recovering accurate 3D human pose and shape from in-the-wild crowd scenes is highly challenging and barely studied, despite their common presence. In this regard, we present 3DCrowdNet, a 2D human pose-guided 3D crowd pose and shape estimation system for in-the-wild scenes. 2D human pose estimation methods provide relatively robust outputs on crowd scenes than 3D human pose estimation methods, as they can exploit in-the-wild multi-person 2D datasets that include crowd scenes. On the other hand, the 3D methods leverage 3D datasets, of which images mostly contain a single actor without a crowd. The train data difference impedes the 3D methods' ability to focus on a target person in in-the-wild crowd scenes. Thus, we design our system to leverage the robust 2D pose outputs from off-the-shelf 2D pose estimators, which guide a network to focus on a target person and provide essential human articulation information. We show that our 3DCrowdNet outperforms previous methods on in-the-wild crowd scenes. We will release the codes.