 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNesterov's Accelerated Gradient and Momentum as approximations to Regularised Update Descent
Jul 11, 2016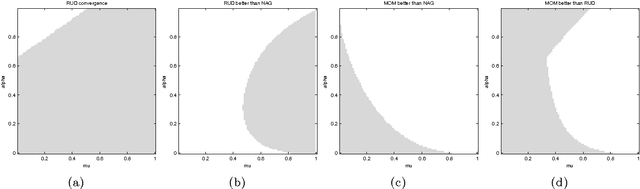
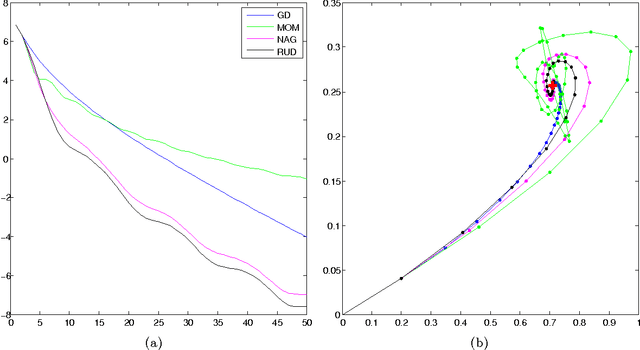
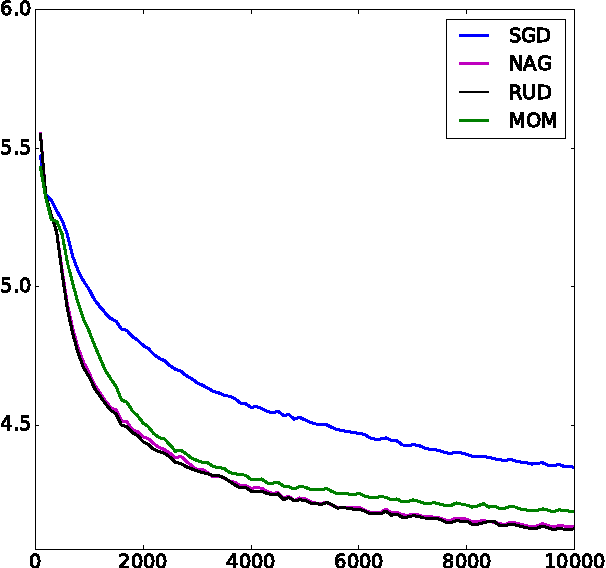
We present a unifying framework for adapting the update direction in gradient-based iterative optimization methods. As natural special cases we re-derive classical momentum and Nesterov's accelerated gradient method, lending a new intuitive interpretation to the latter algorithm. We show that a new algorithm, which we term Regularised Gradient Descent, can converge more quickly than either Nesterov's algorithm or the classical momentum algorithm.
A Gauss-Newton Method for Markov Decision Processes
Aug 06, 2015

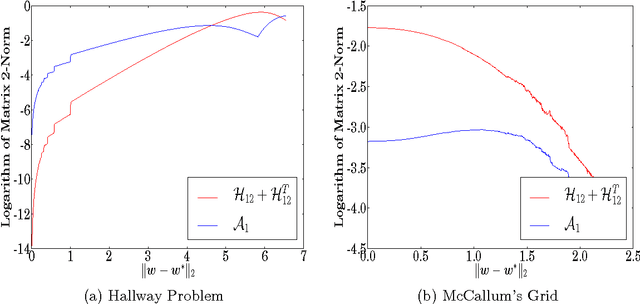
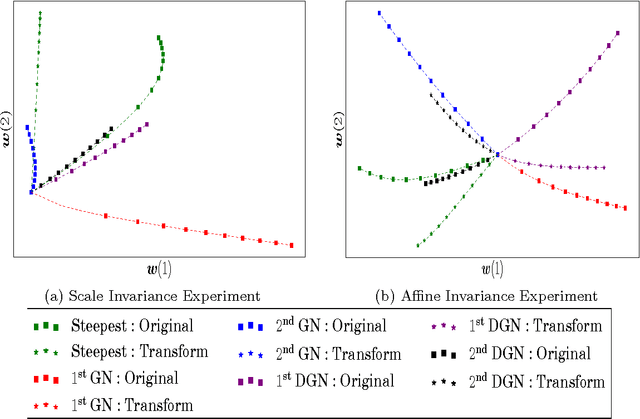
Approximate Newton methods are a standard optimization tool which aim to maintain the benefits of Newton's method, such as a fast rate of convergence, whilst alleviating its drawbacks, such as computationally expensive calculation or estimation of the inverse Hessian. In this work we investigate approximate Newton methods for policy optimization in Markov Decision Processes (MDPs). We first analyse the structure of the Hessian of the objective function for MDPs. We show that, like the gradient, the Hessian exhibits useful structure in the context of MDPs and we use this analysis to motivate two Gauss-Newton Methods for MDPs. Like the Gauss-Newton method for non-linear least squares, these methods involve approximating the Hessian by ignoring certain terms in the Hessian which are difficult to estimate. The approximate Hessians possess desirable properties, such as negative definiteness, and we demonstrate several important performance guarantees including guaranteed ascent directions, invariance to affine transformation of the parameter space, and convergence guarantees. We finally provide a unifying perspective of key policy search algorithms, demonstrating that our second Gauss-Newton algorithm is closely related to both the EM-algorithm and natural gradient ascent applied to MDPs, but performs significantly better in practice on a range of challenging domains.
Modeling transition dynamics in MDPs with RKHS embeddings of conditional distributions
Oct 18, 2012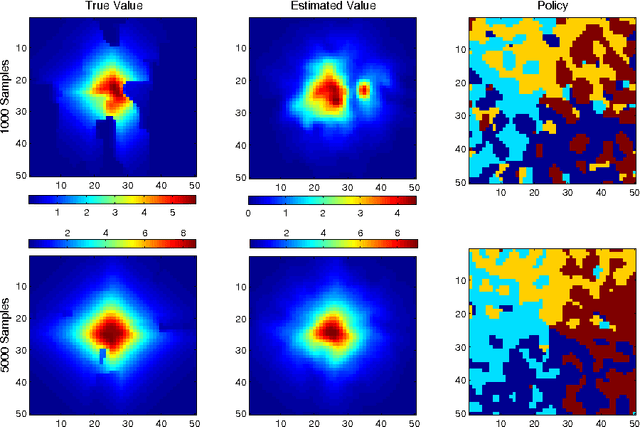
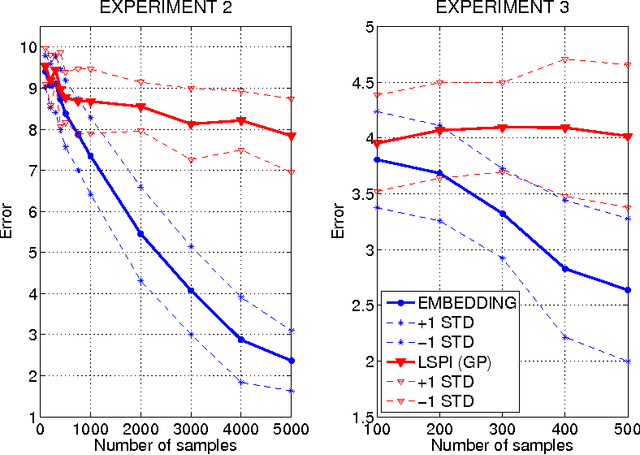
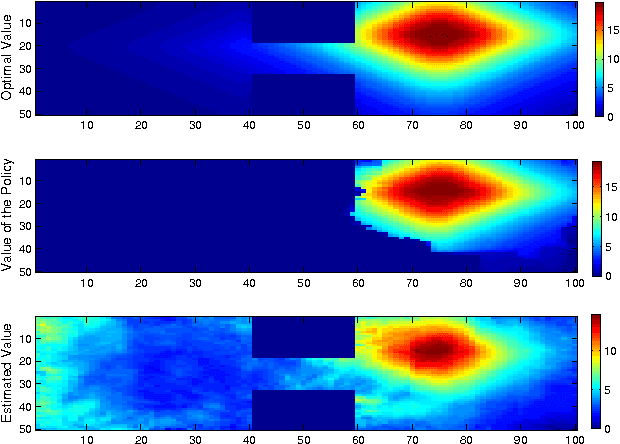
We propose a new, nonparametric approach to estimating the value function in reinforcement learning. This approach makes use of a recently developed representation of conditional distributions as functions in a reproducing kernel Hilbert space. Such representations bypass the need for estimating transition probabilities, and apply to any domain on which kernels can be defined. Our approach avoids the need to approximate intractable integrals since expectations are represented as RKHS inner products whose computation has linear complexity in the sample size. Thus, we can efficiently perform value function estimation in a wide variety of settings, including finite state spaces, continuous states spaces, and partially observable tasks where only sensor measurements are available. A second advantage of the approach is that we learn the conditional distribution representation from a training sample, and do not require an exhaustive exploration of the state space. We prove convergence of our approach either to the optimal policy, or to the closest projection of the optimal policy in our model class, under reasonable assumptions. In experiments, we demonstrate the performance of our algorithm on a learning task in a continuous state space (the under-actuated pendulum), and on a navigation problem where only images from a sensor are observed. We compare with least-squares policy iteration where a Gaussian process is used for value function estimation. Our algorithm achieves better performance in both tasks.
Conditional mean embeddings as regressors - supplementary
Jul 24, 2012
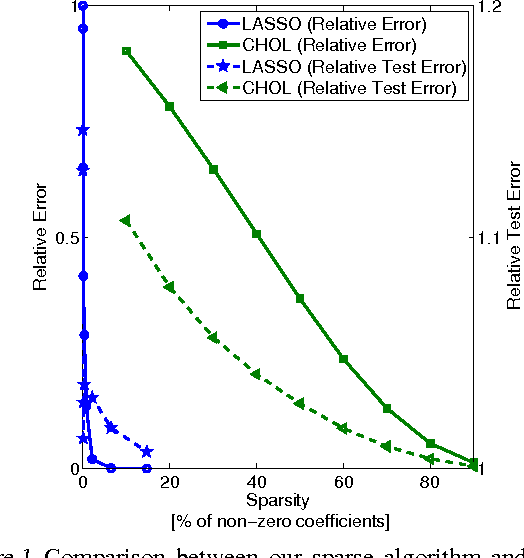
We demonstrate an equivalence between reproducing kernel Hilbert space (RKHS) embeddings of conditional distributions and vector-valued regressors. This connection introduces a natural regularized loss function which the RKHS embeddings minimise, providing an intuitive understanding of the embeddings and a justification for their use. Furthermore, the equivalence allows the application of vector-valued regression methods and results to the problem of learning conditional distributions. Using this link we derive a sparse version of the embedding by considering alternative formulations. Further, by applying convergence results for vector-valued regression to the embedding problem we derive minimax convergence rates which are O(\log(n)/n) -- compared to current state of the art rates of O(n^{-1/4}) -- and are valid under milder and more intuitive assumptions. These minimax upper rates coincide with lower rates up to a logarithmic factor, showing that the embedding method achieves nearly optimal rates. We study our sparse embedding algorithm in a reinforcement learning task where the algorithm shows significant improvement in sparsity over an incomplete Cholesky decomposition.
Modelling transition dynamics in MDPs with RKHS embeddings
Jun 18, 2012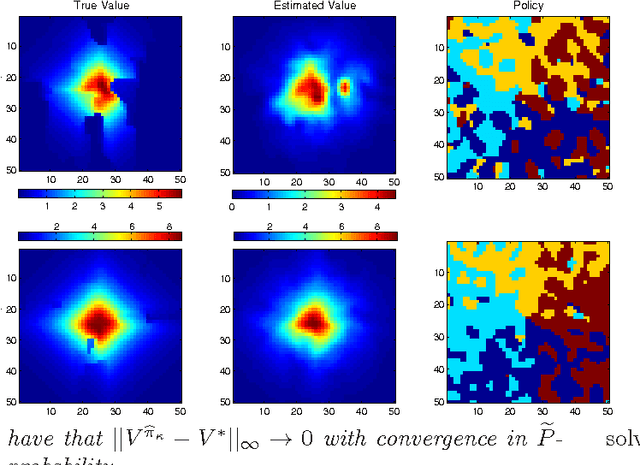
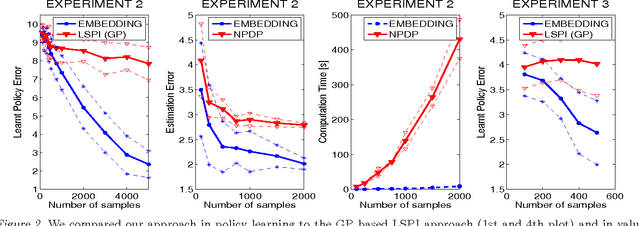
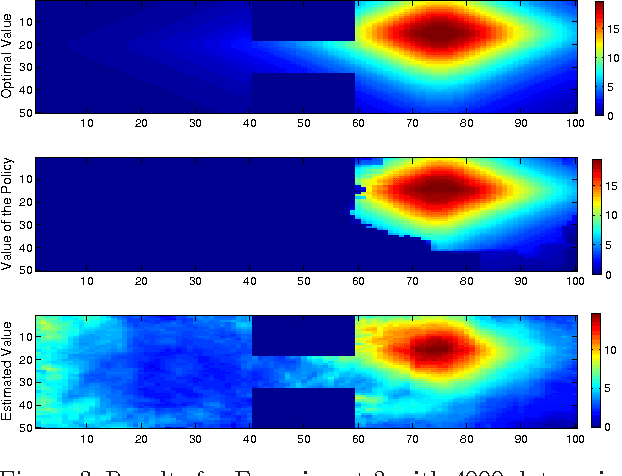
We propose a new, nonparametric approach to learning and representing transition dynamics in Markov decision processes (MDPs), which can be combined easily with dynamic programming methods for policy optimisation and value estimation. This approach makes use of a recently developed representation of conditional distributions as \emph{embeddings} in a reproducing kernel Hilbert space (RKHS). Such representations bypass the need for estimating transition probabilities or densities, and apply to any domain on which kernels can be defined. This avoids the need to calculate intractable integrals, since expectations are represented as RKHS inner products whose computation has linear complexity in the number of points used to represent the embedding. We provide guarantees for the proposed applications in MDPs: in the context of a value iteration algorithm, we prove convergence to either the optimal policy, or to the closest projection of the optimal policy in our model class (an RKHS), under reasonable assumptions. In experiments, we investigate a learning task in a typical classical control setting (the under-actuated pendulum), and on a navigation problem where only images from a sensor are observed. For policy optimisation we compare with least-squares policy iteration where a Gaussian process is used for value function estimation. For value estimation we also compare to the NPDP method. Our approach achieves better performance in all experiments.
Data-dependent kernels in nearly-linear time
Oct 20, 2011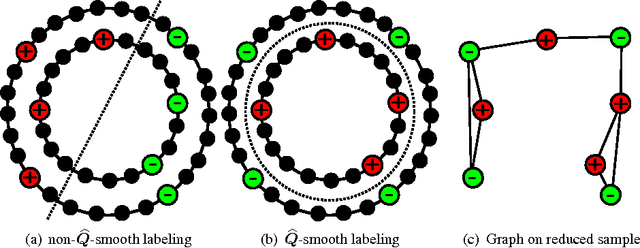
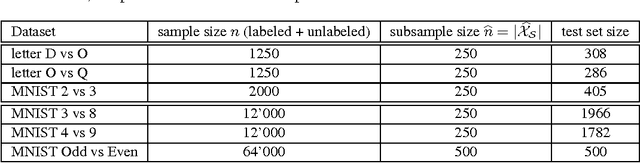
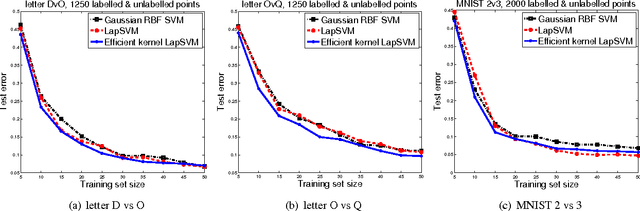
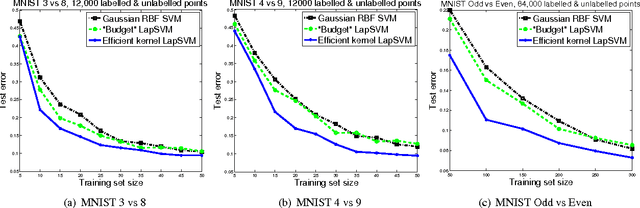
We propose a method to efficiently construct data-dependent kernels which can make use of large quantities of (unlabeled) data. Our construction makes an approximation in the standard construction of semi-supervised kernels in Sindhwani et al. 2005. In typical cases these kernels can be computed in nearly-linear time (in the amount of data), improving on the cubic time of the standard construction, enabling large scale semi-supervised learning in a variety of contexts. The methods are validated on semi-supervised and unsupervised problems on data sets containing upto 64,000 sample points.