 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe large learning rate phase of deep learning: the catapult mechanism
Mar 04, 2020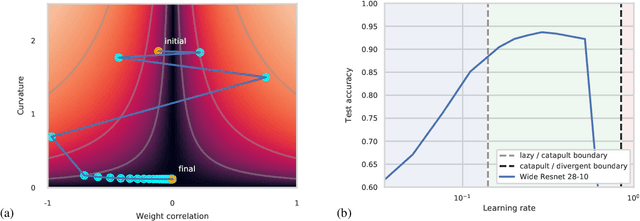
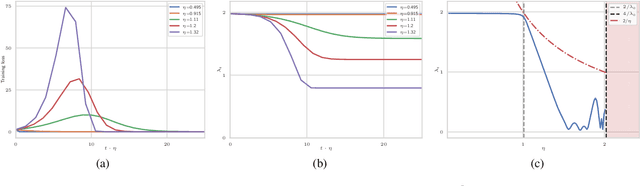
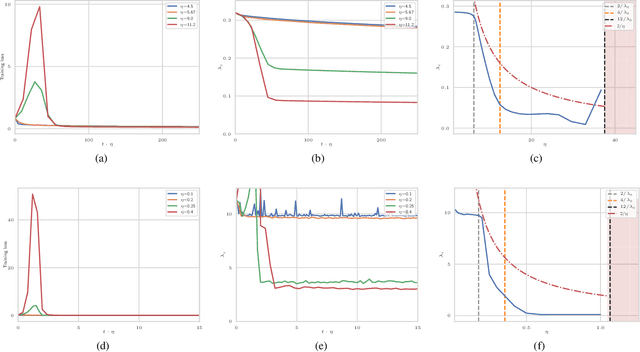
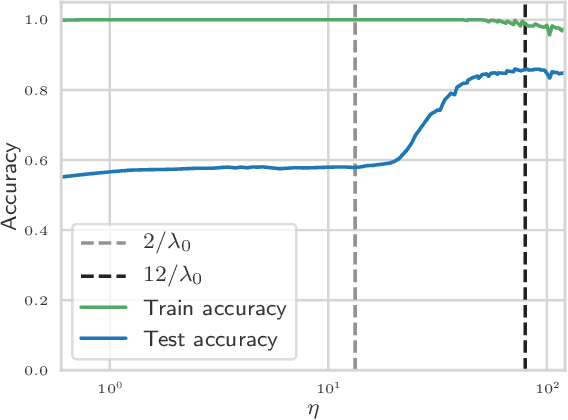
The choice of initial learning rate can have a profound effect on the performance of deep networks. We present a class of neural networks with solvable training dynamics, and confirm their predictions empirically in practical deep learning settings. The networks exhibit sharply distinct behaviors at small and large learning rates. The two regimes are separated by a phase transition. In the small learning rate phase, training can be understood using the existing theory of infinitely wide neural networks. At large learning rates the model captures qualitatively distinct phenomena, including the convergence of gradient descent dynamics to flatter minima. One key prediction of our model is a narrow range of large, stable learning rates. We find good agreement between our model's predictions and training dynamics in realistic deep learning settings. Furthermore, we find that the optimal performance in such settings is often found in the large learning rate phase. We believe our results shed light on characteristics of models trained at different learning rates. In particular, they fill a gap between existing wide neural network theory, and the nonlinear, large learning rate, training dynamics relevant to practice.
Wider Networks Learn Better Features
Sep 25, 2019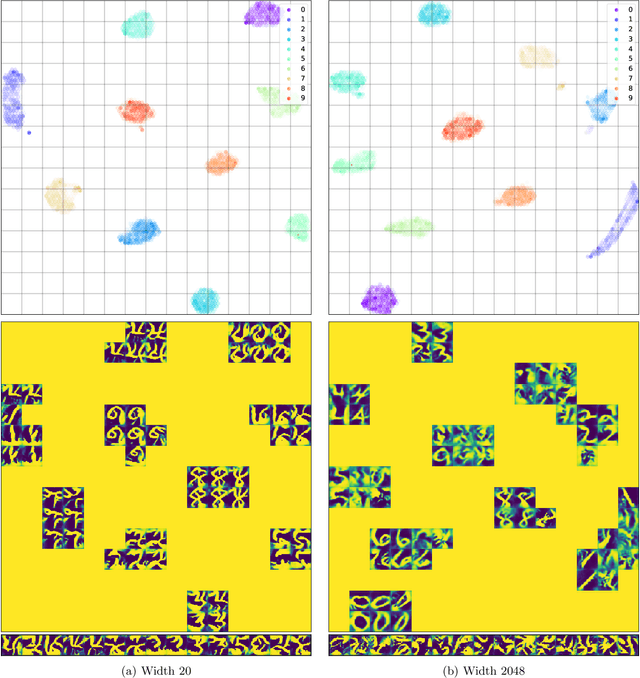
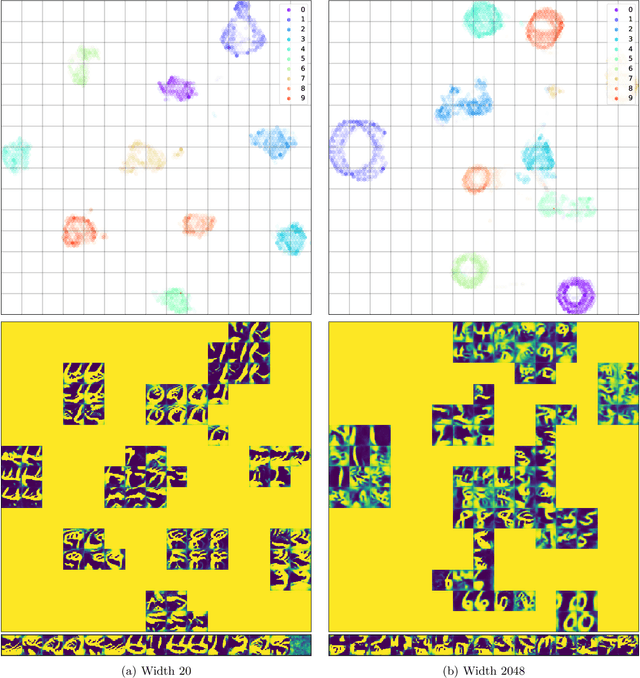

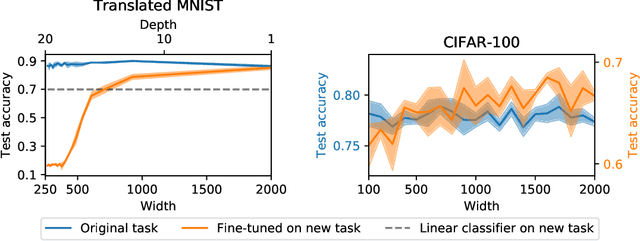
Transferability of learned features between tasks can massively reduce the cost of training a neural network on a novel task. We investigate the effect of network width on learned features using activation atlases --- a visualization technique that captures features the entire hidden state responds to, as opposed to individual neurons alone. We find that, while individual neurons do not learn interpretable features in wide networks, groups of neurons do. In addition, the hidden state of a wide network contains more information about the inputs than that of a narrow network trained to the same test accuracy. Inspired by this observation, we show that when fine-tuning the last layer of a network on a new task, performance improves significantly as the width of the network is increased, even though test accuracy on the original task is independent of width.
Asymptotics of Wide Networks from Feynman Diagrams
Sep 25, 2019
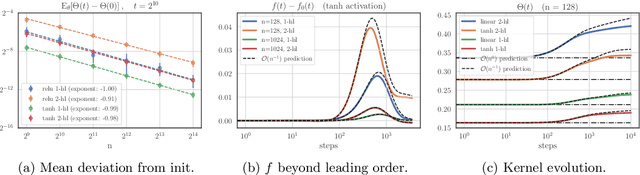

Understanding the asymptotic behavior of wide networks is of considerable interest. In this work, we present a general method for analyzing this large width behavior. The method is an adaptation of Feynman diagrams, a standard tool for computing multivariate Gaussian integrals. We apply our method to study training dynamics, improving existing bounds and deriving new results on wide network evolution during stochastic gradient descent. Going beyond the strict large width limit, we present closed-form expressions for higher-order terms governing wide network training, and test these predictions empirically.
Gradient Descent Happens in a Tiny Subspace
Dec 12, 2018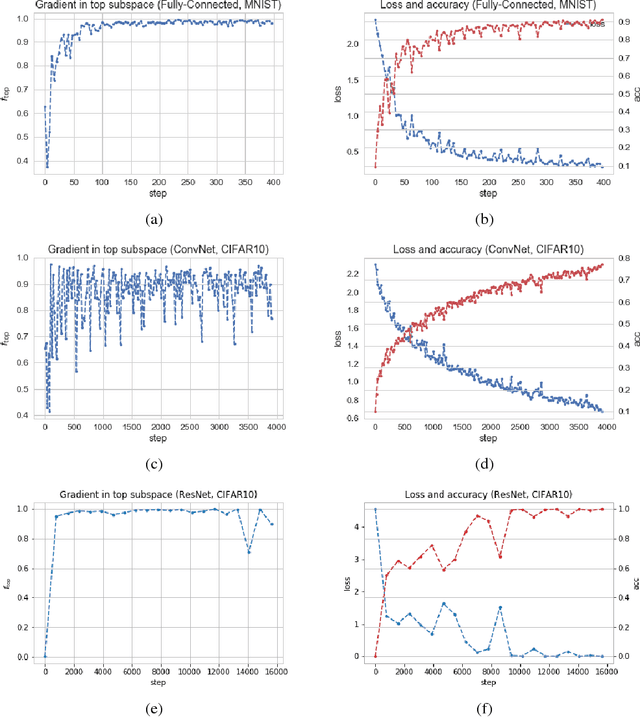
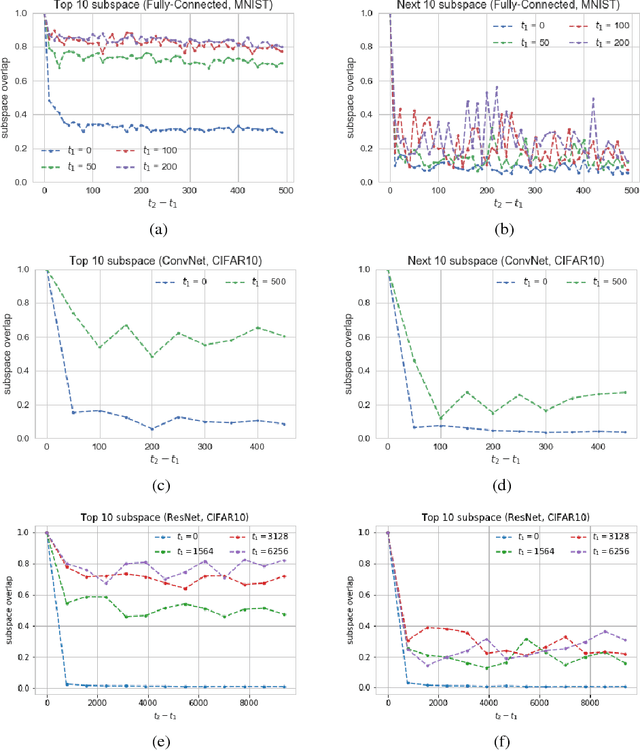
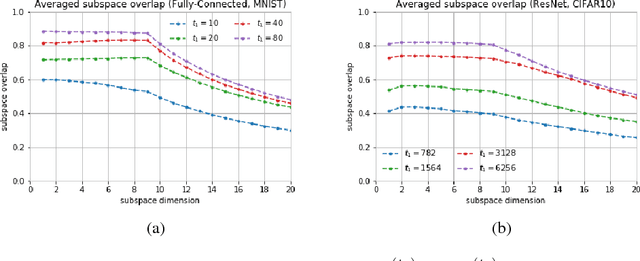
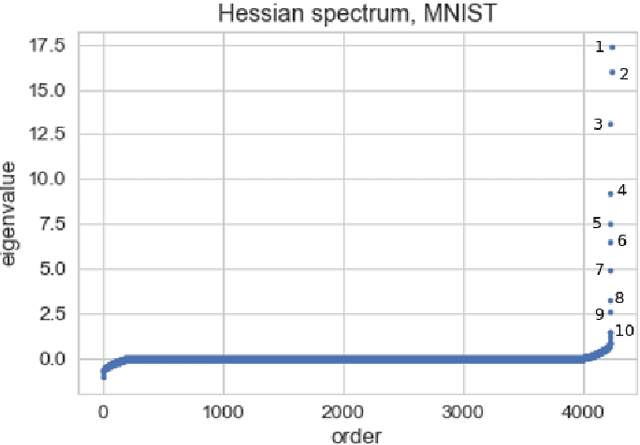
We show that in a variety of large-scale deep learning scenarios the gradient dynamically converges to a very small subspace after a short period of training. The subspace is spanned by a few top eigenvectors of the Hessian (equal to the number of classes in the dataset), and is mostly preserved over long periods of training. A simple argument then suggests that gradient descent may happen mostly in this subspace. We give an example of this effect in a solvable model of classification, and we comment on possible implications for optimization and learning.