 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent multiple shared layers in Depth for Neural Machine Translation
Aug 26, 2021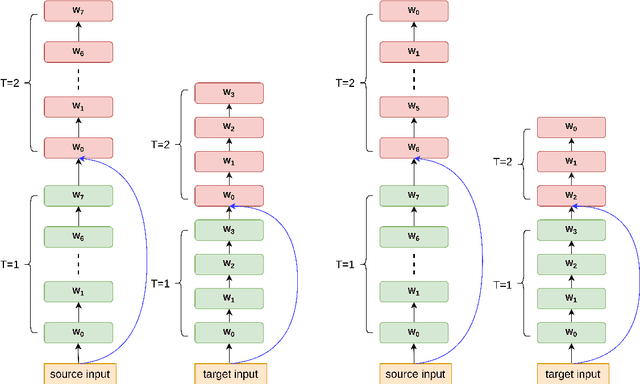

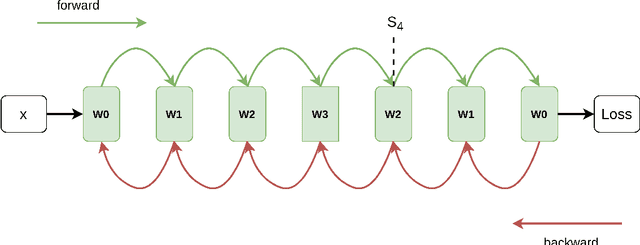

Learning deeper models is usually a simple and effective approach to improve model performance, but deeper models have larger model parameters and are more difficult to train. To get a deeper model, simply stacking more layers of the model seems to work well, but previous works have claimed that it cannot benefit the model. We propose to train a deeper model with recurrent mechanism, which loops the encoder and decoder blocks of Transformer in the depth direction. To address the increasing of model parameters, we choose to share parameters in different recursive moments. We conduct our experiments on WMT16 English-to-German and WMT14 English-to-France translation tasks, our model outperforms the shallow Transformer-Base/Big baseline by 0.35, 1.45 BLEU points, which is 27.23% of Transformer-Big model parameters. Compared to the deep Transformer(20-layer encoder, 6-layer decoder), our model has similar model performance and infer speed, but our model parameters are 54.72% of the former.
Residual Tree Aggregation of Layers for Neural Machine Translation
Jul 19, 2021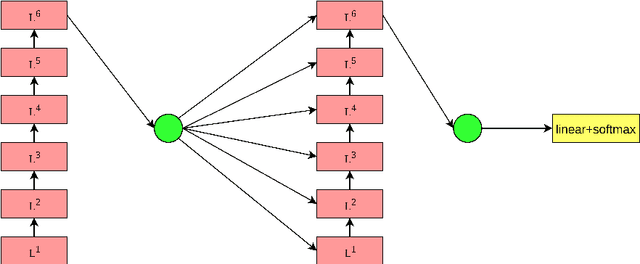
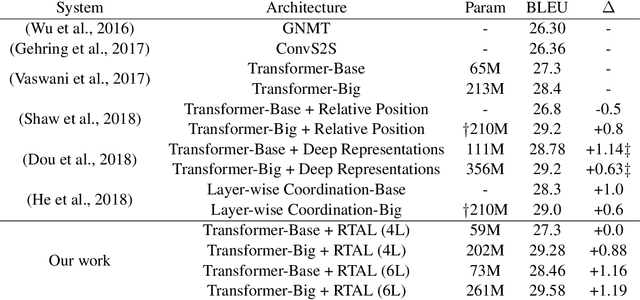
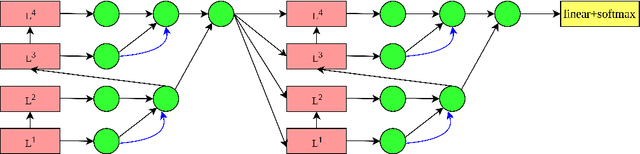

Although attention-based Neural Machine Translation has achieved remarkable progress in recent layers, it still suffers from issue of making insufficient use of the output of each layer. In transformer, it only uses the top layer of encoder and decoder in the subsequent process, which makes it impossible to take advantage of the useful information in other layers. To address this issue, we propose a residual tree aggregation of layers for Transformer(RTAL), which helps to fuse information across layers. Specifically, we try to fuse the information across layers by constructing a post-order binary tree. In additional to the last node, we add the residual connection to the process of generating child nodes. Our model is based on the Neural Machine Translation model Transformer and we conduct our experiments on WMT14 English-to-German and WMT17 English-to-France translation tasks. Experimental results across language pairs show that the proposed approach outperforms the strong baseline model significantly