 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised and Unsupervised Detections for Multiple Object Tracking in Traffic Scenes: A Comparative Study
Mar 30, 2020
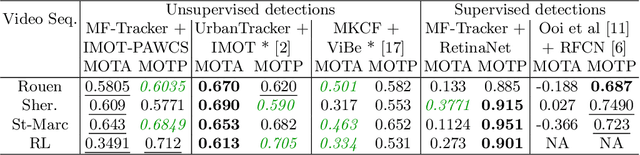
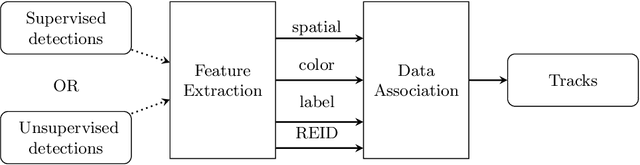
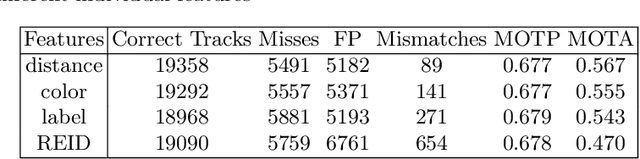
In this paper, we propose a multiple object tracker, called MF-Tracker, that integrates multiple classical features (spatial distances and colours) and modern features (detection labels and re-identification features) in its tracking framework. Since our tracker can work with detections coming either from unsupervised and supervised object detectors, we also investigated the impact of supervised and unsupervised detection inputs in our method and for tracking road users in general. We also compared our results with existing methods that were applied on the UA-Detrac and the UrbanTracker datasets. Results show that our proposed method is performing very well in both datasets with different inputs (MOTA ranging from 0:3491 to 0:5805 for unsupervised inputs on the UrbanTracker dataset and an average MOTA of 0:7638 for supervised inputs on the UA Detrac dataset) under different circumstances. A well-trained supervised object detector can give better results in challenging scenarios. However, in simpler scenarios, if good training data is not available, unsupervised method can perform well and can be a good alternative.
Tracking Road Users using Constraint Programming
Mar 10, 2020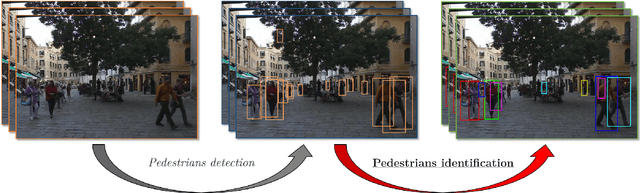

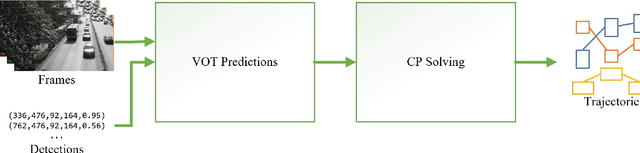
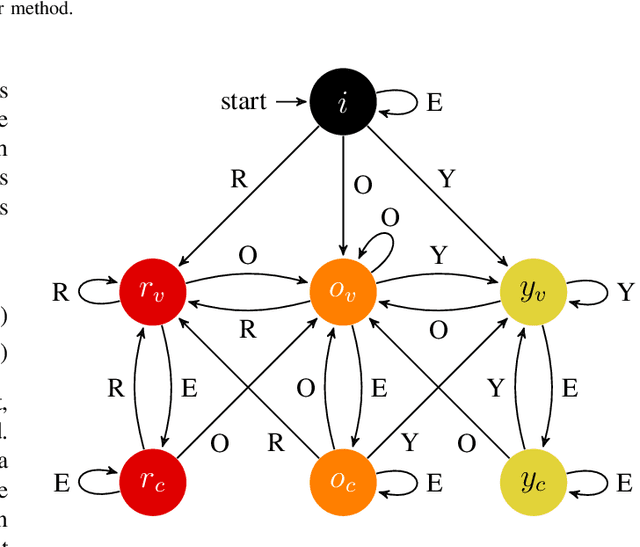
In this paper, we aim at improving the tracking of road users in urban scenes. We present a constraint programming (CP) approach for the data association phase found in the tracking-by-detection paradigm of the multiple object tracking (MOT) problem. Such an approach can solve the data association problem more efficiently than graph-based methods and can handle better the combinatorial explosion occurring when multiple frames are analyzed. Because our focus is on the data association problem, our MOT method only uses simple image features, which are the center position and color of detections for each frame. Constraints are defined on these two features and on the general MOT problem. For example, we enforce color appearance preservation over trajectories and constrain the extent of motion between frames. Filtering layers are used in order to eliminate detection candidates before using CP and to remove dummy trajectories produced by the CP solver. Our proposed method was tested on a motorized vehicles tracking dataset and produces results that outperform the top methods of the UA-DETRAC benchmark.
SpotNet: Self-Attention Multi-Task Network for Object Detection
Feb 13, 2020
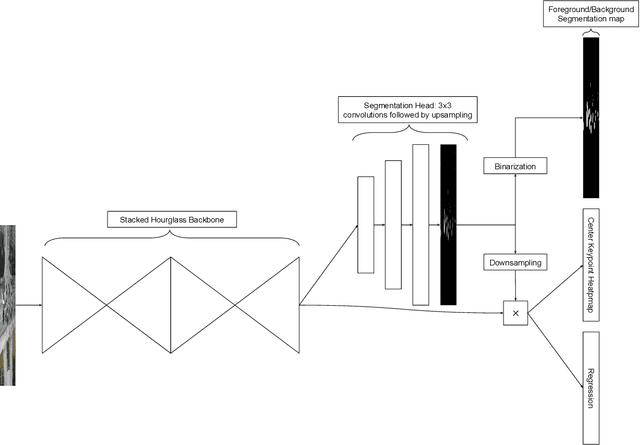


Humans are very good at directing their visual attention toward relevant areas when they search for different types of objects. For instance, when we search for cars, we will look at the streets, not at the top of buildings. The motivation of this paper is to train a network to do the same via a multi-task learning approach. To train visual attention, we produce foreground/background segmentation labels in a semi-supervised way, using background subtraction or optical flow. Using these labels, we train an object detection model to produce foreground/background segmentation maps as well as bounding boxes while sharing most model parameters. We use those segmentation maps inside the network as a self-attention mechanism to weight the feature map used to produce the bounding boxes, decreasing the signal of non-relevant areas. We show that by using this method, we obtain a significant mAP improvement on two traffic surveillance datasets, with state-of-the-art results on both UA-DETRAC and UAVDT.
Color inference from semantic labeling for person search in videos
Nov 29, 2019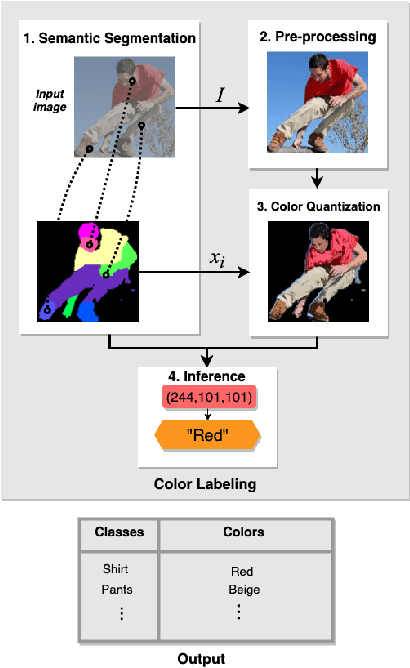
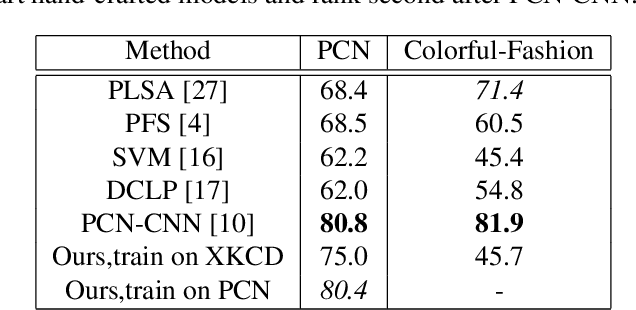

We propose an explainable model to generate semantic color labels for person search. In this context, persons are described from their semantic parts, such as hat, shirt, etc. Person search consists in looking for people based on these descriptions. In this work, we aim to improve the accuracy of color labels for people. Our goal is to handle the high variability of human perception. Existing solutions are based on hand-crafted features or learnt features that are not explainable. Moreover most of them only focus on a limited set of colors. We propose a method based on binary search trees and a large peer-labelled color name dataset. This allows us to synthesize the human perception of colors. Using semantic segmentation and our color labeling method, we label segments of pedestrians with their associated colors. We evaluate our solution on person search on datasets such as PCN, and show a precision as high as 80.4%.
Deep 1D-Convnet for accurate Parkinson disease detection and severity prediction from gait
Nov 22, 2019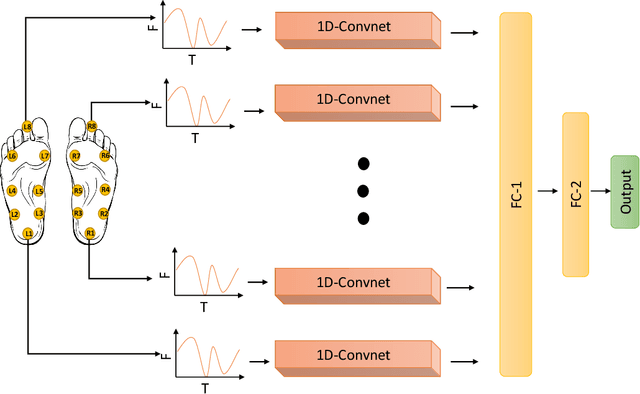
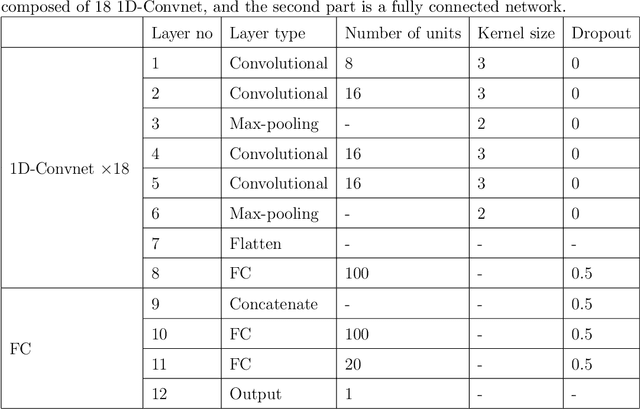
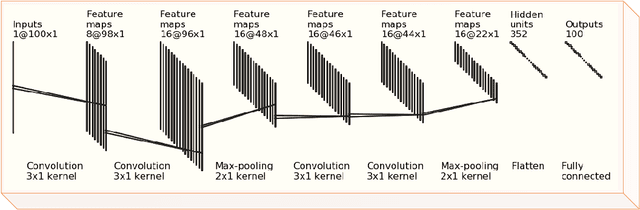
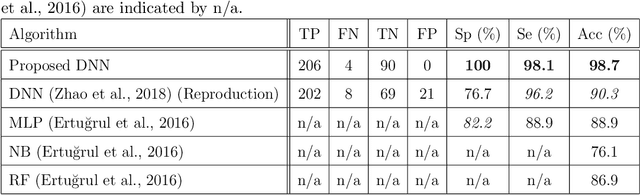
Diagnosing Parkinson's disease is a complex task that requires the evaluation of several motor and non-motor symptoms. During diagnosis, gait abnormalities are among the important symptoms that physicians should consider. However, gait evaluation is challenging and relies on the expertise and subjectivity of clinicians. In this context, the use of an intelligent gait analysis algorithm may assist physicians in order to facilitate the diagnosis process. This paper proposes a novel intelligent Parkinson detection system based on deep learning techniques to analyze gait information. We used 1D convolutional neural network (1D-Convnet) to build a Deep Neural Network (DNN) classifier. The proposed model processes 18 1D-signals coming from foot sensors measuring the vertical ground reaction force (VGRF). The first part of the network consists of 18 parallel 1D-Convnet corresponding to system inputs. The second part is a fully connected network that connects the concatenated outputs of the 1D-Convnets to obtain a final classification. We tested our algorithm in Parkinson's detection and in the prediction of the severity of the disease with the Unified Parkinson's Disease Rating Scale (UPDRS). Our experiments demonstrate the high efficiency of the proposed method in the detection of Parkinson disease based on gait data. The proposed algorithm achieved an accuracy of 98.7 %. To our knowledge, this is the state-of-the-start performance in Parkinson's gait recognition. Furthermore, we achieved an accuracy of 85.3 % in Parkinson's severity prediction. To the best of our knowledge, this is the first algorithm to perform a severity prediction based on the UPDRS. Our results show that the model is able to learn intrinsic characteristics from gait data and to generalize to unseen subjects, which could be helpful in a clinical diagnosis.
Tracking in Urban Traffic Scenes from Background Subtraction and Object Detection
May 15, 2019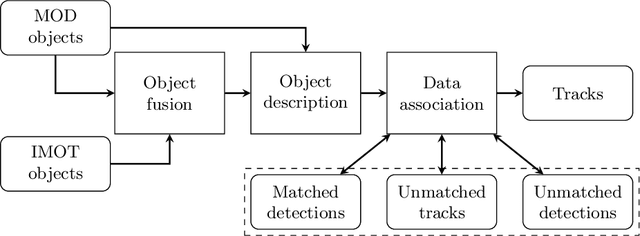
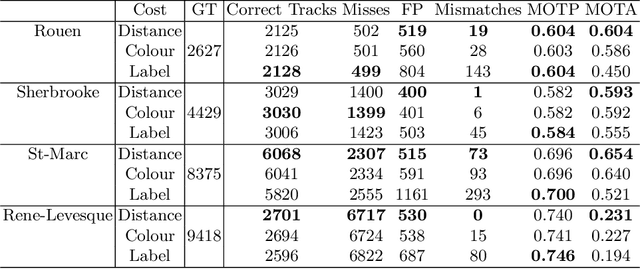


In this paper, we propose to combine detections from background subtraction and from a multiclass object detector for multiple object tracking (MOT) in urban traffic scenes. These objects are associated across frames using spatial, colour and class label information, and trajectory prediction is evaluated to yield the final MOT outputs. The proposed method was tested on the Urban tracker dataset and shows competitive performances compared to state-of-the-art approaches. Results show that the integration of different detection inputs remains a challenging task that greatly affects the MOT performance.
Adversarially Learned Abnormal Trajectory Classifier
Apr 03, 2019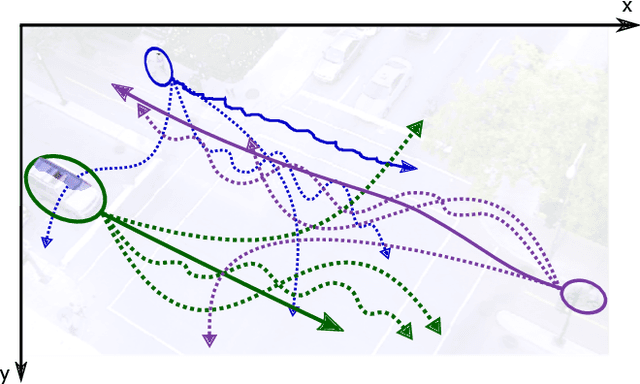
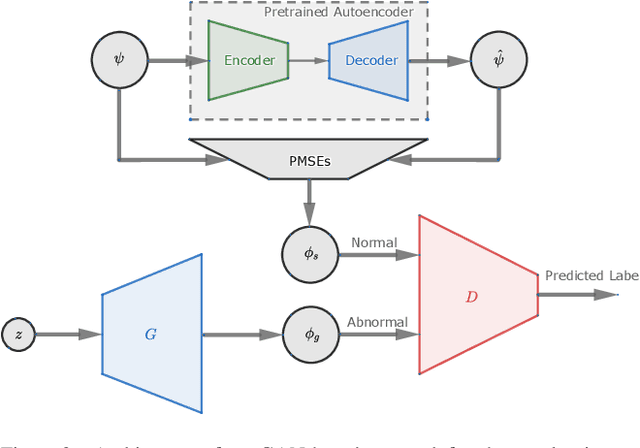
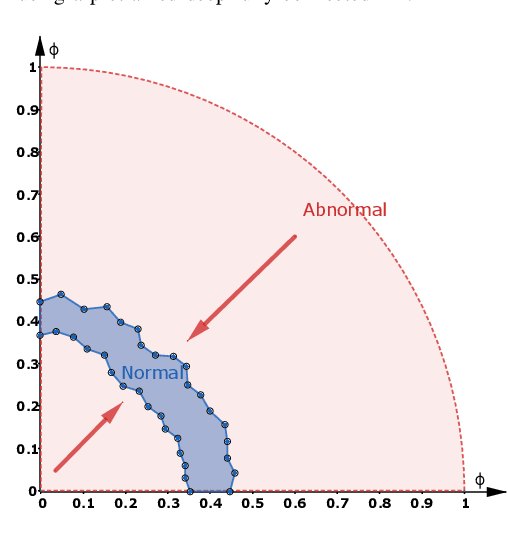
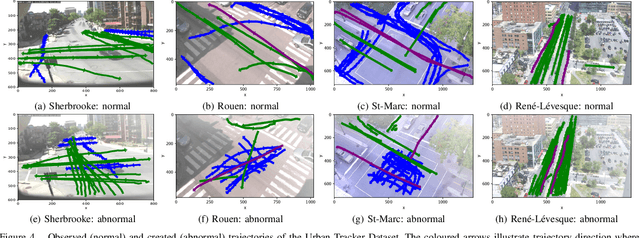
We address the problem of abnormal event detection from trajectory data. In this paper, a new adversarial approach is proposed for building a deep neural network binary classifier, trained in an unsupervised fashion, that can distinguish normal from abnormal trajectory-based events without the need for setting manual detection threshold. Inspired by the generative adversarial network (GAN) framework, our GAN version is a discriminative one in which the discriminator is trained to distinguish normal and abnormal trajectory reconstruction errors given by a deep autoencoder. With urban traffic videos and their associated trajectories, our proposed method gives the best accuracy for abnormal trajectory detection. In addition, our model can easily be generalized for abnormal trajectory-based event detection and can still yield the best behavioural detection results as demonstrated on the CAVIAR dataset.
Road User Detection in Videos
Mar 28, 2019
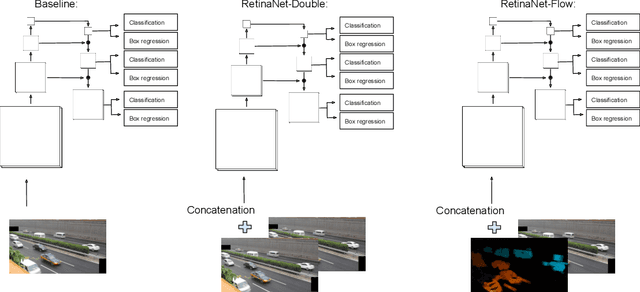


Successive frames of a video are highly redundant, and the most popular object detection methods do not take advantage of this fact. Using multiple consecutive frames can improve detection of small objects or difficult examples and can improve speed and detection consistency in a video sequence, for instance by interpolating features between frames. In this work, a novel approach is introduced to perform online video object detection using two consecutive frames of video sequences involving road users. Two new models, RetinaNet-Double and RetinaNet-Flow, are proposed, based respectively on the concatenation of a target frame with a preceding frame, and the concatenation of the optical flow with the target frame. The models are trained and evaluated on three public datasets. Experiments show that using a preceding frame improves performance over single frame detectors, but using explicit optical flow usually does not.
Domain-Specific Face Synthesis for Video Face Recognition from a Single Sample Per Person
Oct 01, 2018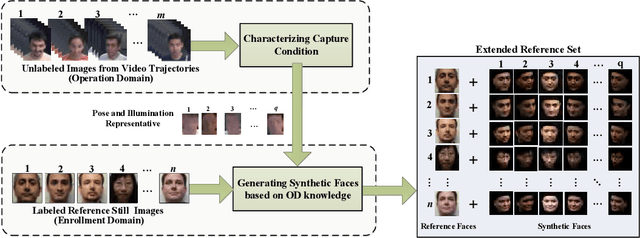
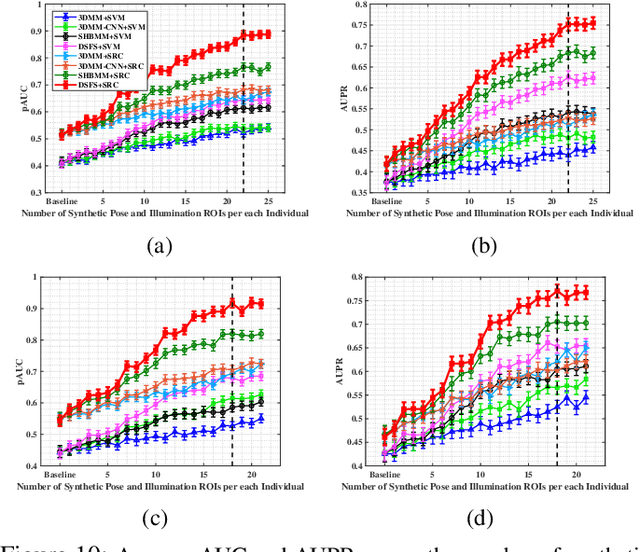
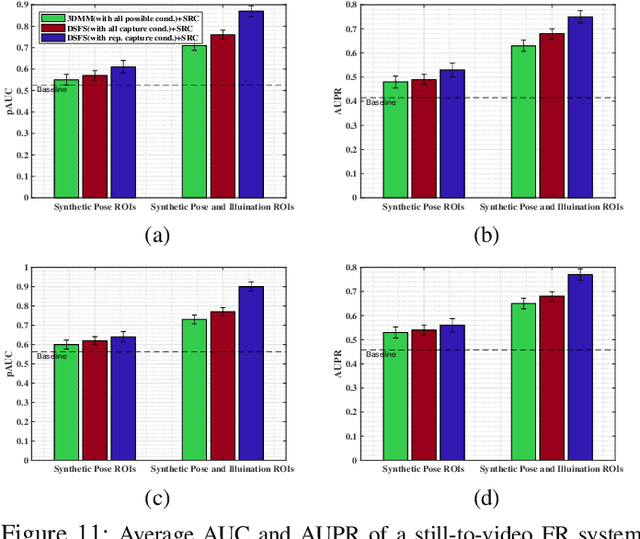
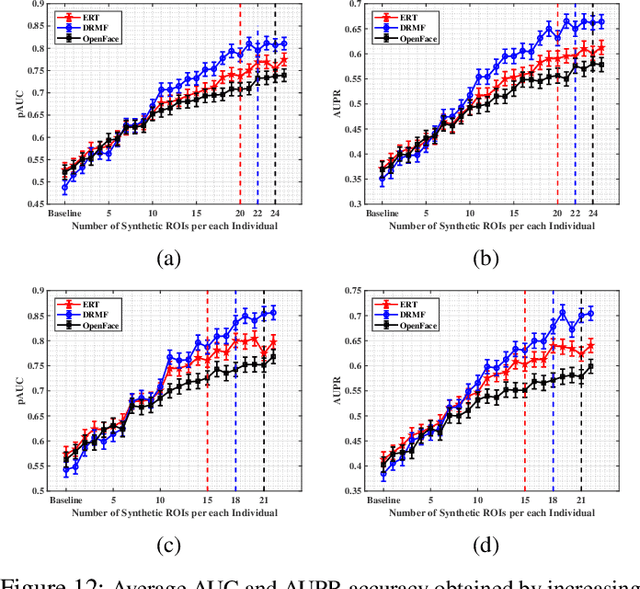
The performance of still-to-video FR systems can decline significantly because faces captured in unconstrained operational domain (OD) over multiple video cameras have a different underlying data distribution compared to faces captured under controlled conditions in the enrollment domain (ED) with a still camera. This is particularly true when individuals are enrolled to the system using a single reference still. To improve the robustness of these systems, it is possible to augment the reference set by generating synthetic faces based on the original still. However, without knowledge of the OD, many synthetic images must be generated to account for all possible capture conditions. FR systems may, therefore, require complex implementations and yield lower accuracy when training on many less relevant images. This paper introduces an algorithm for domain-specific face synthesis (DSFS) that exploits the representative intra-class variation information available from the OD. Prior to operation, a compact set of faces from unknown persons appearing in the OD is selected through clustering in the captured condition space. The domain-specific variations of these face images are projected onto the reference stills by integrating an image-based face relighting technique inside the 3D reconstruction framework. A compact set of synthetic faces is generated that resemble individuals of interest under the capture conditions relevant to the OD. In a particular implementation based on sparse representation classification, the synthetic faces generated with the DSFS are employed to form a cross-domain dictionary that account for structured sparsity. Experimental results reveal that augmenting the reference gallery set of FR systems using the proposed DSFS approach can provide a higher level of accuracy compared to state-of-the-art approaches, with only a moderate increase in its computational complexity.
Online Mutual Foreground Segmentation for Multispectral Stereo Videos
Sep 08, 2018
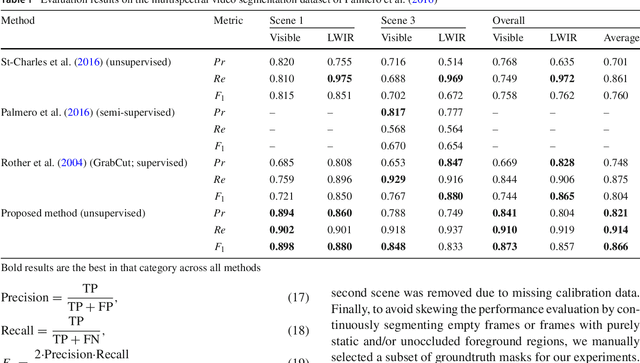
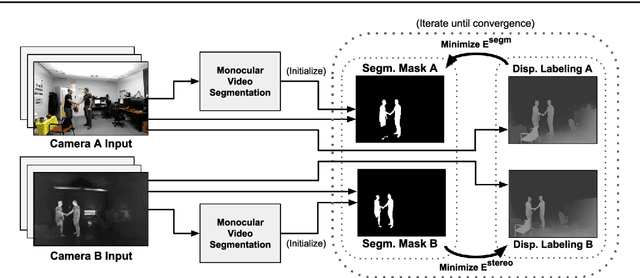
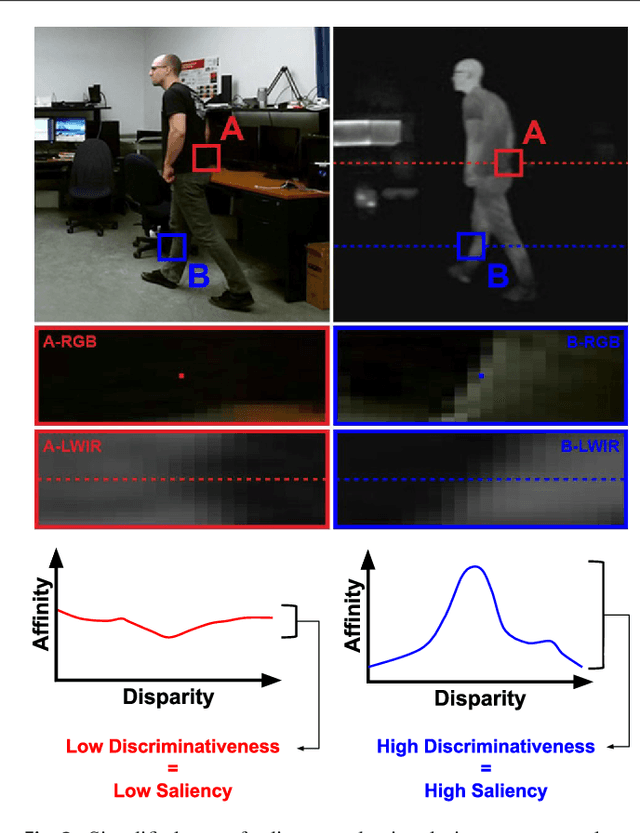
The segmentation of video sequences into foreground and background regions is a low-level process commonly used in video content analysis and smart surveillance applications. Using a multispectral camera setup can improve this process by providing more diverse data to help identify objects despite adverse imaging conditions. The registration of several data sources is however not trivial if the appearance of objects produced by each sensor differs substantially. This problem is further complicated when parallax effects cannot be ignored when using close-range stereo pairs. In this work, we present a new method to simultaneously tackle multispectral segmentation and stereo registration. Using an iterative procedure, we estimate the labeling result for one problem using the provisional result of the other. Our approach is based on the alternating minimization of two energy functions that are linked through the use of dynamic priors. We rely on the integration of shape and appearance cues to find proper multispectral correspondences, and to properly segment objects in low contrast regions. We also formulate our model as a frame processing pipeline using higher order terms to improve the temporal coherence of our results. Our method is evaluated under different configurations on multiple multispectral datasets, and our implementation is available online.