 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeNToS: Tracklets Association with a Space-Time Memory Network
Jul 15, 2021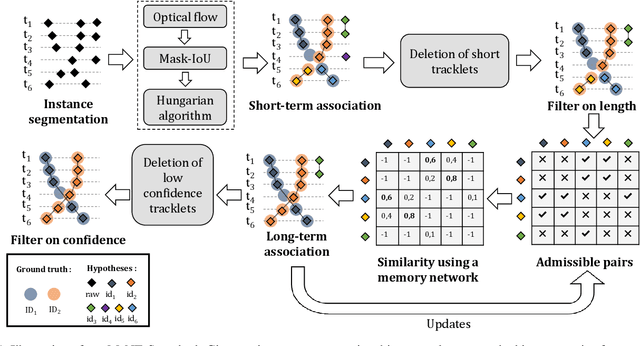
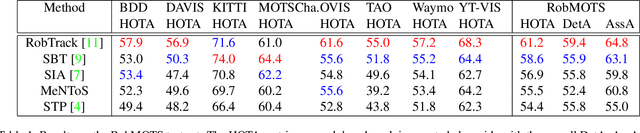
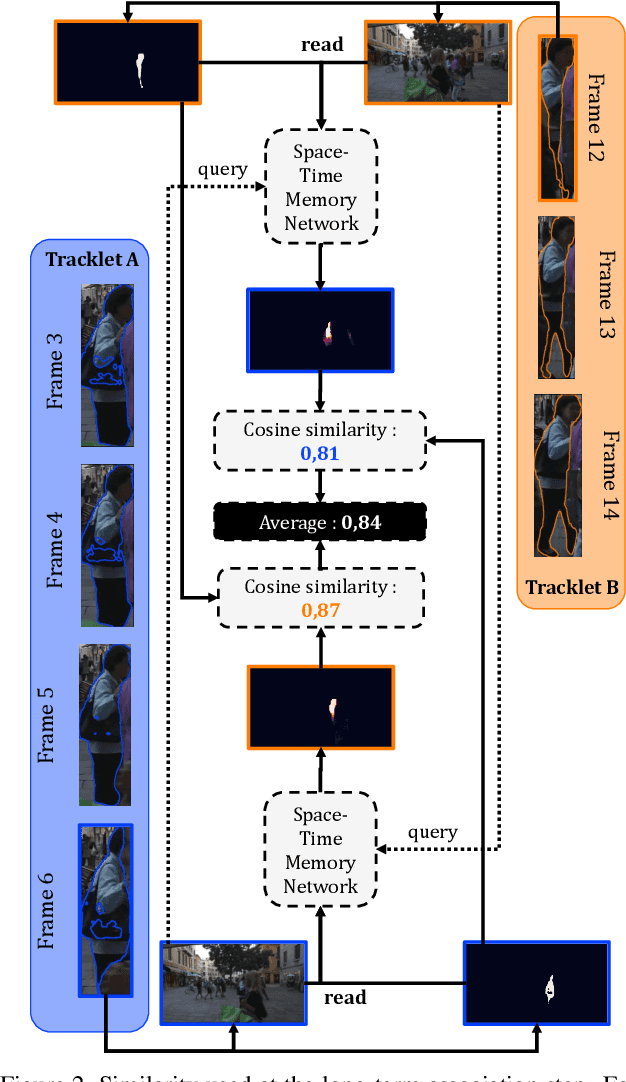
We propose a method for multi-object tracking and segmentation (MOTS) that does not require fine-tuning or per benchmark hyperparameter selection. The proposed method addresses particularly the data association problem. Indeed, the recently introduced HOTA metric, that has a better alignment with the human visual assessment by evenly balancing detections and associations quality, has shown that improvements are still needed for data association. After creating tracklets using instance segmentation and optical flow, the proposed method relies on a space-time memory network (STM) developed for one-shot video object segmentation to improve the association of tracklets with temporal gaps. To the best of our knowledge, our method, named MeNToS, is the first to use the STM network to track object masks for MOTS. We took the 4th place in the RobMOTS challenge. The project page is https://mehdimiah.com/mentos.html.
Predicting Next Local Appearance for Video Anomaly Detection
Jun 10, 2021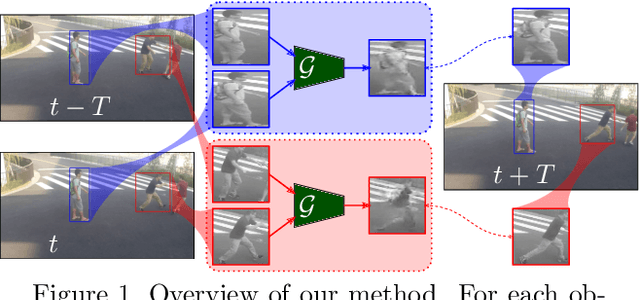
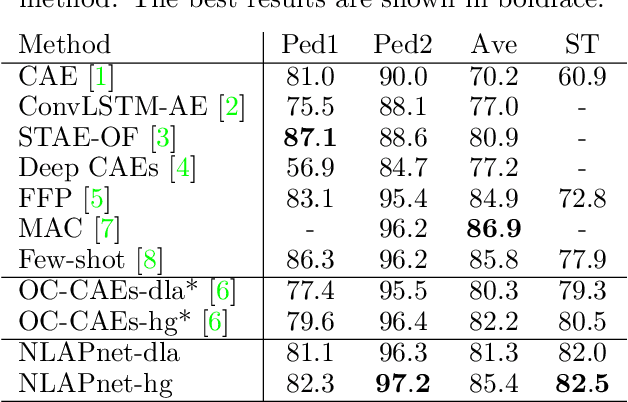
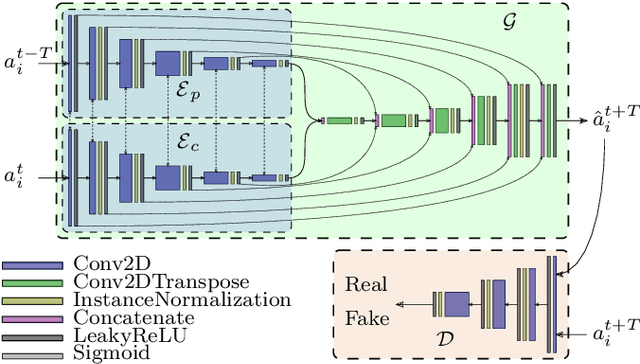
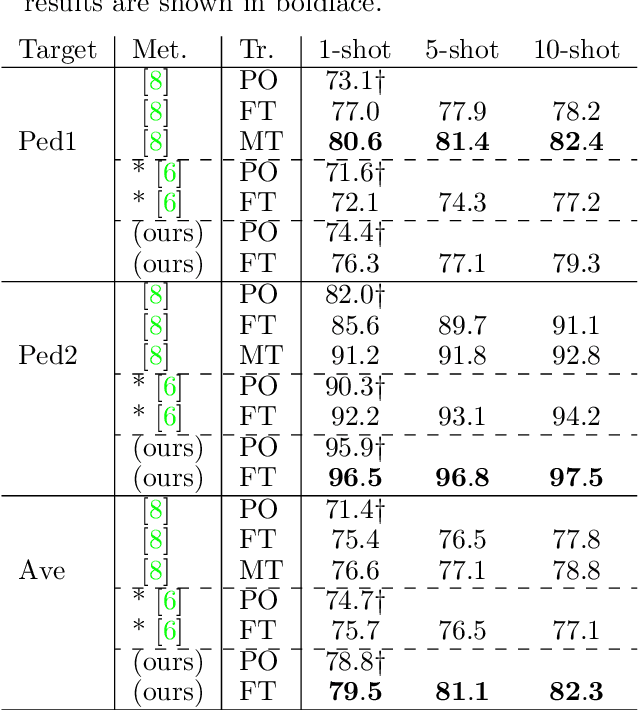
We present a local anomaly detection method in videos. As opposed to most existing methods that are computationally expensive and are not very generalizable across different video scenes, we propose an adversarial framework that learns the temporal local appearance variations by predicting the appearance of a normally behaving object in the next frame of a scene by only relying on its current and past appearances. In the presence of an abnormally behaving object, the reconstruction error between the real and the predicted next appearance of that object indicates the likelihood of an anomaly. Our method is competitive with the existing state-of-the-art while being significantly faster for both training and inference and being better at generalizing to unseen video scenes.
Multiple Convolutional Features in Siamese Networks for Object Tracking
Mar 01, 2021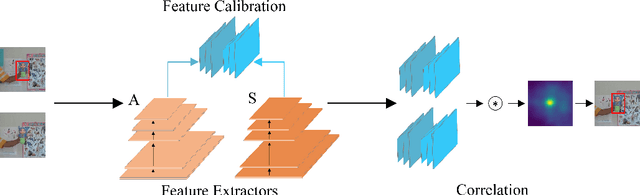
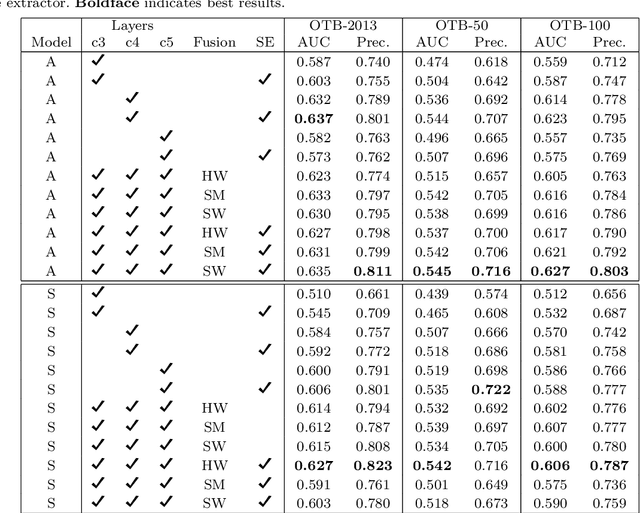
Siamese trackers demonstrated high performance in object tracking due to their balance between accuracy and speed. Unlike classification-based CNNs, deep similarity networks are specifically designed to address the image similarity problem, and thus are inherently more appropriate for the tracking task. However, Siamese trackers mainly use the last convolutional layers for similarity analysis and target search, which restricts their performance. In this paper, we argue that using a single convolutional layer as feature representation is not an optimal choice in a deep similarity framework. We present a Multiple Features-Siamese Tracker (MFST), a novel tracking algorithm exploiting several hierarchical feature maps for robust tracking. Since convolutional layers provide several abstraction levels in characterizing an object, fusing hierarchical features allows to obtain a richer and more efficient representation of the target. Moreover, we handle the target appearance variations by calibrating the deep features extracted from two different CNN models. Based on this advanced feature representation, our method achieves high tracking accuracy, while outperforming the standard siamese tracker on object tracking benchmarks. The source code and trained models are available at https://github.com/zhenxili96/MFST.
MFST: Multi-Features Siamese Tracker
Mar 01, 2021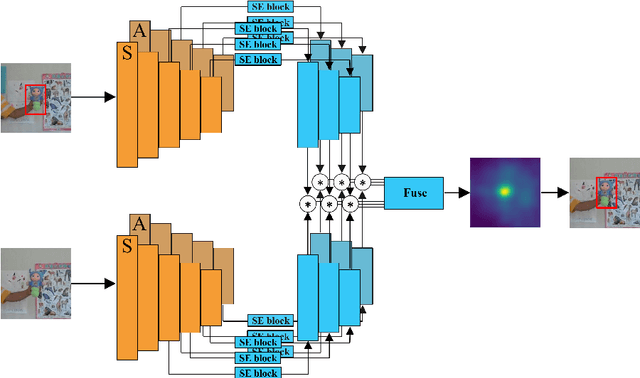
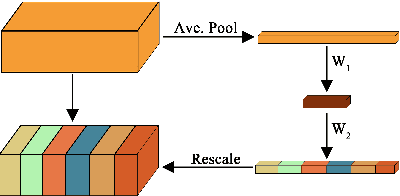
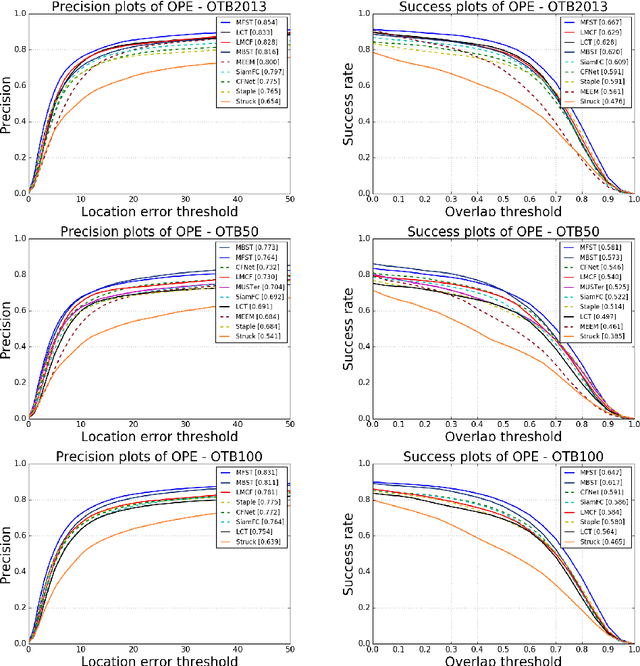
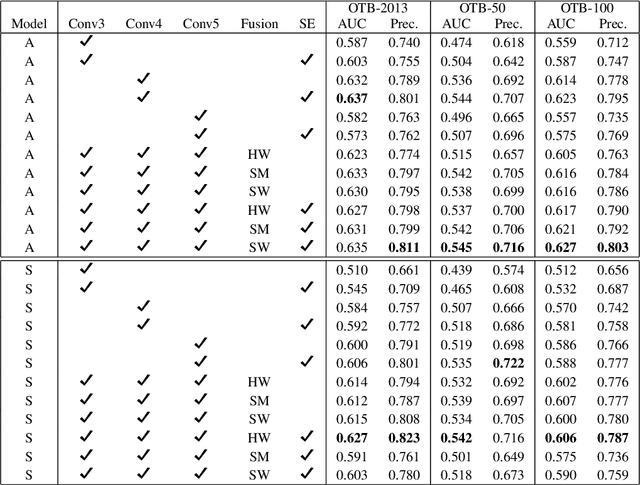
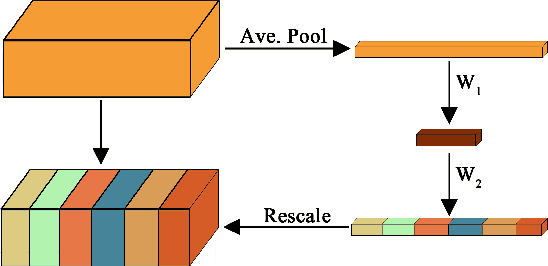
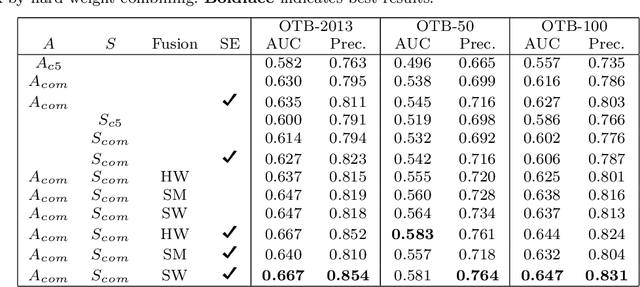
Siamese trackers have recently achieved interesting results due to their balance between accuracy and speed. This success is mainly due to the fact that deep similarity networks were specifically designed to address the image similarity problem. Therefore, they are inherently more appropriate than classical CNNs for the tracking task. However, Siamese trackers rely on the last convolutional layers for similarity analysis and target search, which restricts their performance. In this paper, we argue that using a single convolutional layer as feature representation is not the optimal choice within the deep similarity framework, as multiple convolutional layers provide several abstraction levels in characterizing an object. Starting from this motivation, we present the Multi-Features Siamese Tracker (MFST), a novel tracking algorithm exploiting several hierarchical feature maps for robust deep similarity tracking. MFST proceeds by fusing hierarchical features to ensure a richer and more efficient representation. Moreover, we handle appearance variation by calibrating deep features extracted from two different CNN models. Based on this advanced feature representation, our algorithm achieves high tracking accuracy, while outperforming several state-of-the-art trackers, including standard Siamese trackers. The code and trained models are available at https://github.com/zhenxili96/MFST.
Local Anomaly Detection in Videos using Object-Centric Adversarial Learning
Nov 13, 2020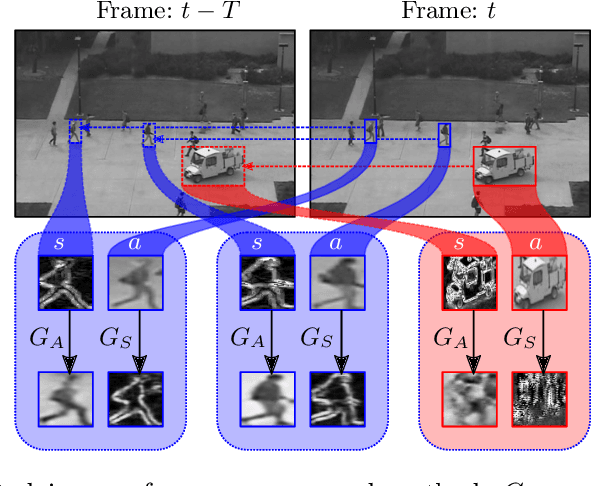
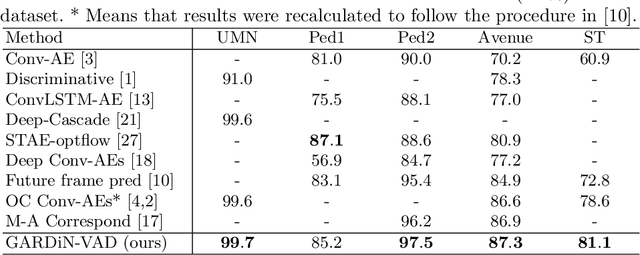
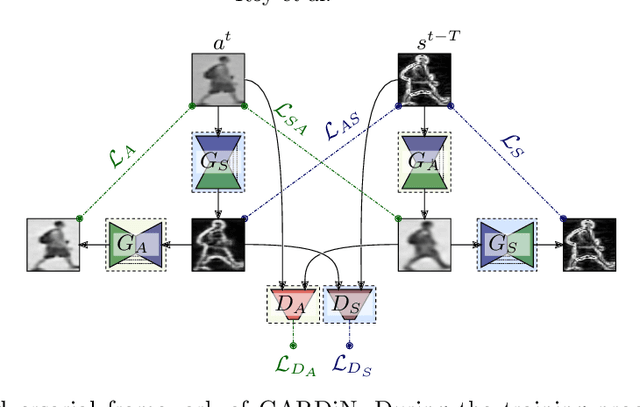
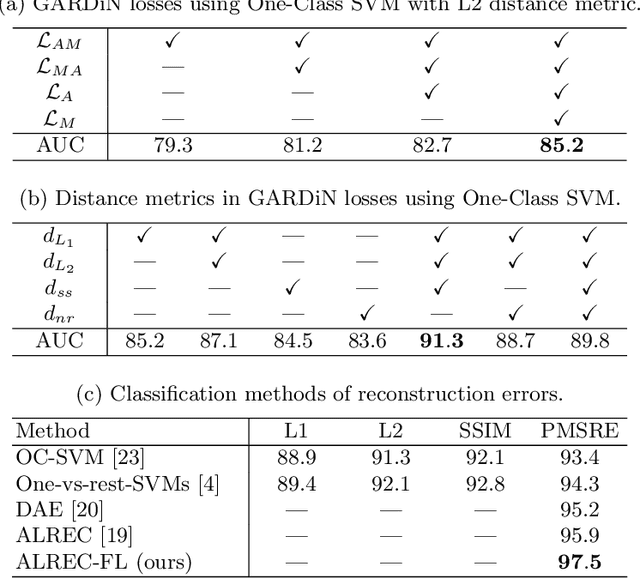
We propose a novel unsupervised approach based on a two-stage object-centric adversarial framework that only needs object regions for detecting frame-level local anomalies in videos. The first stage consists in learning the correspondence between the current appearance and past gradient images of objects in scenes deemed normal, allowing us to either generate the past gradient from current appearance or the reverse. The second stage extracts the partial reconstruction errors between real and generated images (appearance and past gradient) with normal object behaviour, and trains a discriminator in an adversarial fashion. In inference mode, we employ the trained image generators with the adversarially learned binary classifier for outputting region-level anomaly detection scores. We tested our method on four public benchmarks, UMN, UCSD, Avenue and ShanghaiTech and our proposed object-centric adversarial approach yields competitive or even superior results compared to state-of-the-art methods.
A Grid-based Representation for Human Action Recognition
Oct 29, 2020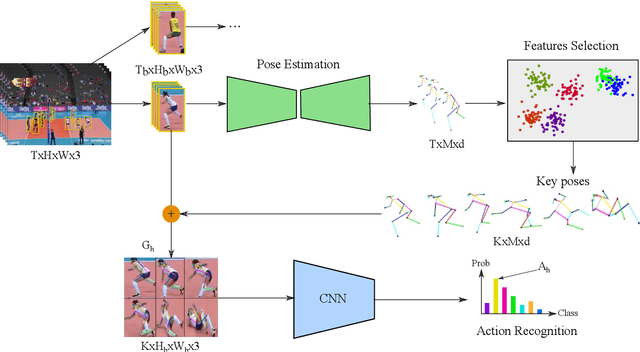
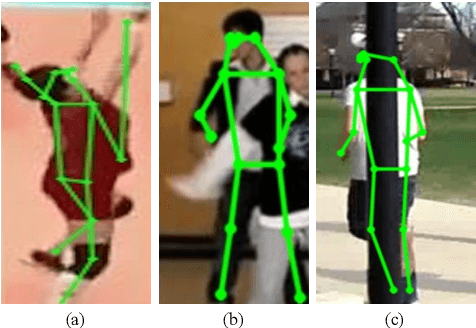


Human action recognition (HAR) in videos is a fundamental research topic in computer vision. It consists mainly in understanding actions performed by humans based on a sequence of visual observations. In recent years, HAR have witnessed significant progress, especially with the emergence of deep learning models. However, most of existing approaches for action recognition rely on information that is not always relevant for this task, and are limited in the way they fuse the temporal information. In this paper, we propose a novel method for human action recognition that encodes efficiently the most discriminative appearance information of an action with explicit attention on representative pose features, into a new compact grid representation. Our GRAR (Grid-based Representation for Action Recognition) method is tested on several benchmark datasets demonstrating that our model can accurately recognize human actions, despite intra-class appearance variations and occlusion challenges.
An Empirical Analysis of Visual Features for Multiple Object Tracking in Urban Scenes
Oct 15, 2020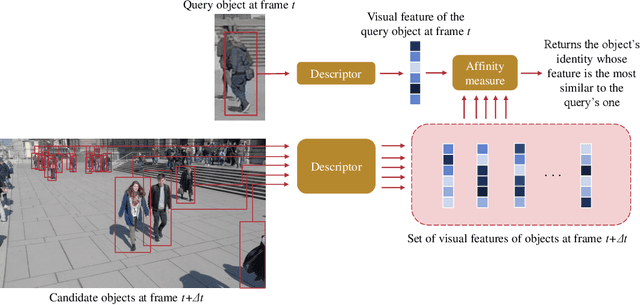
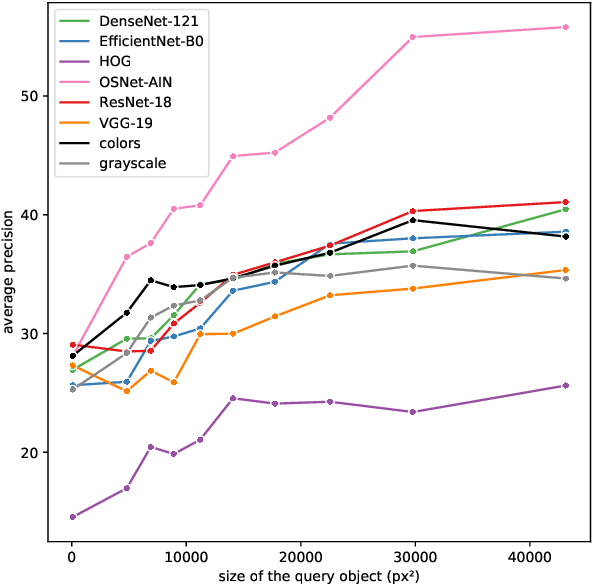

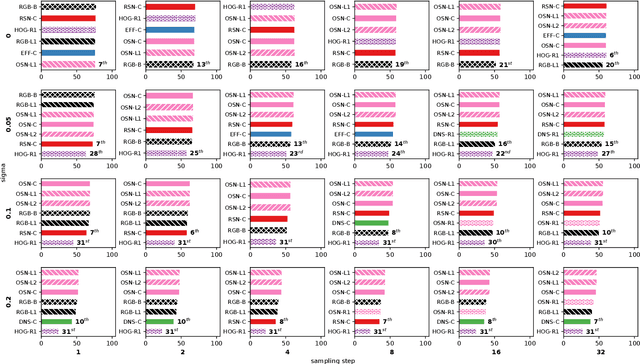
This paper addresses the problem of selecting appearance features for multiple object tracking (MOT) in urban scenes. Over the years, a large number of features has been used for MOT. However, it is not clear whether some of them are better than others. Commonly used features are color histograms, histograms of oriented gradients, deep features from convolutional neural networks and re-identification (ReID) features. In this study, we assess how good these features are at discriminating objects enclosed by a bounding box in urban scene tracking scenarios. Several affinity measures, namely the $\mathrm{L}_1$, $\mathrm{L}_2$ and the Bhattacharyya distances, Rank-1 counts and the cosine similarity, are also assessed for their impact on the discriminative power of the features. Results on several datasets show that features from ReID networks are the best for discriminating instances from one another regardless of the quality of the detector. If a ReID model is not available, color histograms may be selected if the detector has a good recall and there are few occlusions; otherwise, deep features are more robust to detectors with lower recall. The project page is http://www.mehdimiah.com/visual_features.
Unsupervised Disentanglement GAN for Domain Adaptive Person Re-Identification
Jul 30, 2020
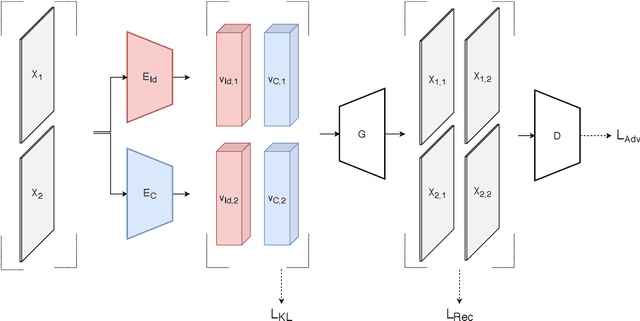
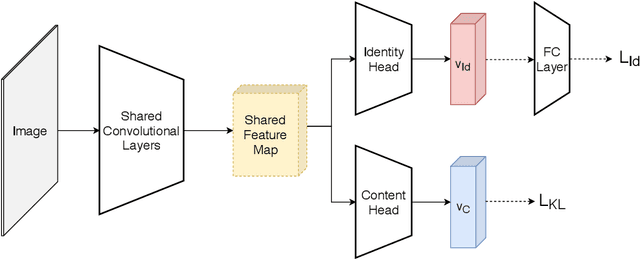
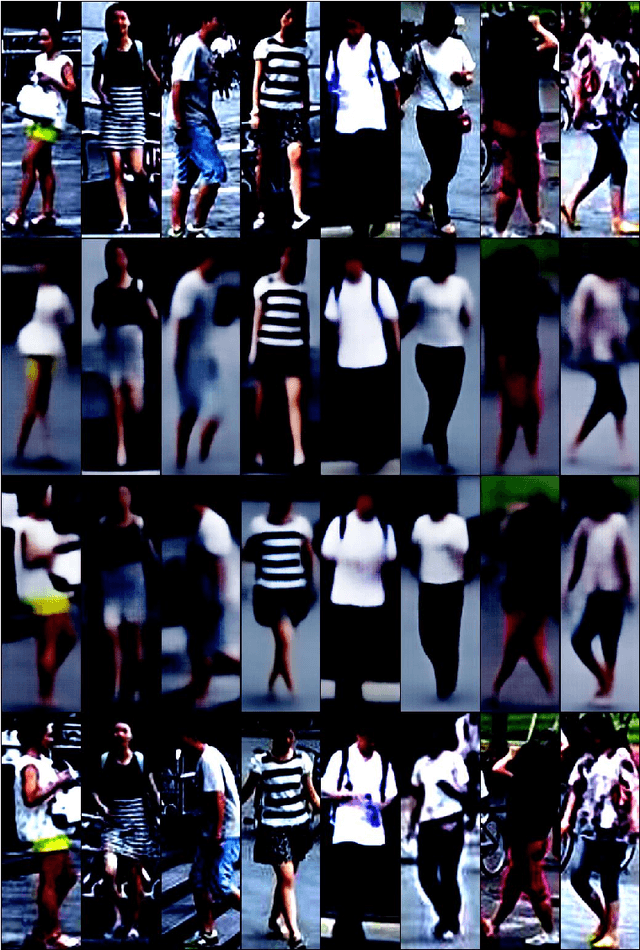
While recent person re-identification (ReID) methods achieve high accuracy in a supervised setting, their generalization to an unlabelled domain is still an open problem. In this paper, we introduce a novel unsupervised disentanglement generative adversarial network (UD-GAN) to address the domain adaptation issue of supervised person ReID. Our framework jointly trains a ReID network for discriminative features extraction in a source labelled domain using identity annotation, and adapts the ReID model to an unlabelled target domain by learning disentangled latent representations on the domain. Identity-unrelated features in the target domain are distilled from the latent features. As a result, the ReID features better encompass the identity of a person in the unsupervised domain. We conducted experiments on the Market1501, DukeMTMC and MSMT17 datasets. Results show that the unsupervised domain adaptation problem in ReID is very challenging. Nevertheless, our method shows improvement in half of the domain transfers and achieve state-of-the-art performance for one of them.
Domain Siamese CNNs for Sparse Multispectral Disparity Estimation
Apr 30, 2020
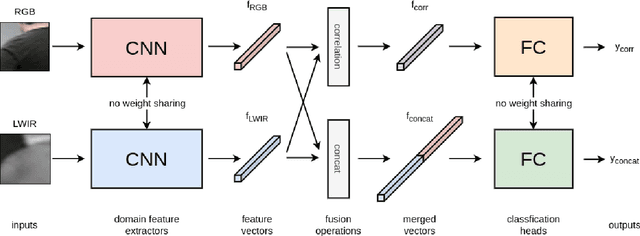

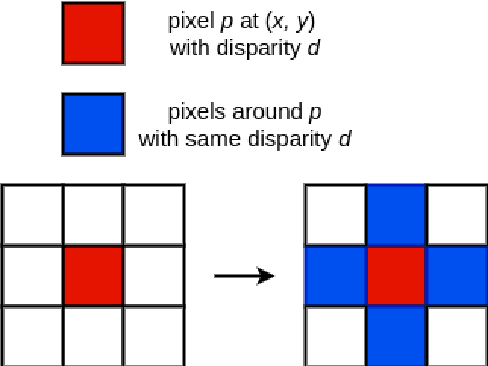
Multispectral disparity estimation is a difficult task for many reasons: it has all the same challenges as traditional visible-visible disparity estimation (occlusions, repetitive patterns, textureless surfaces), in addition of having very few common visual information between images (e.g. color information vs. thermal information). In this paper, we propose a new CNN architecture able to do disparity estimation between images from different spectrum, namely thermal and visible in our case. Our proposed model takes two patches as input and proceeds to do domain feature extraction for each of them. Features from both domains are then merged with two fusion operations, namely correlation and concatenation. These merged vectors are then forwarded to their respective classification heads, which are responsible for classifying the inputs as being same or not. Using two merging operations gives more robustness to our feature extraction process, which leads to more precise disparity estimation. Our method was tested using the publicly available LITIV 2014 and LITIV 2018 datasets, and showed best results when compared to other state of the art methods.
RN-VID: A Feature Fusion Architecture for Video Object Detection
Apr 02, 2020
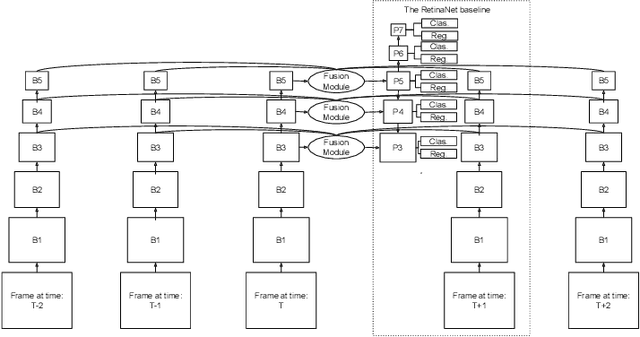
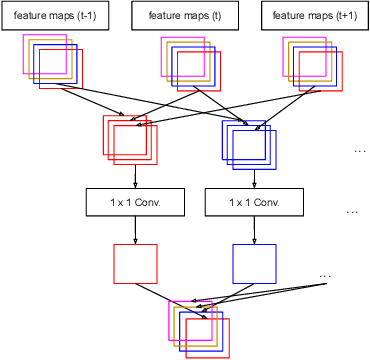

Consecutive frames in a video are highly redundant. Therefore, to perform the task of video object detection, executing single frame detectors on every frame without reusing any information is quite wasteful. It is with this idea in mind that we propose RN-VID (standing for RetinaNet-VIDeo), a novel approach to video object detection. Our contributions are twofold. First, we propose a new architecture that allows the usage of information from nearby frames to enhance feature maps. Second, we propose a novel module to merge feature maps of same dimensions using re-ordering of channels and 1 x 1 convolutions. We then demonstrate that RN-VID achieves better mean average precision (mAP) than corresponding single frame detectors with little additional cost during inference.