 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-MultispectralNet: Multispectral Stereoscopic Disparity Estimation using Human Masks
Apr 19, 2022
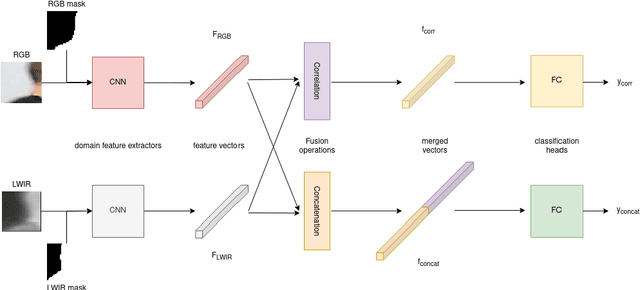
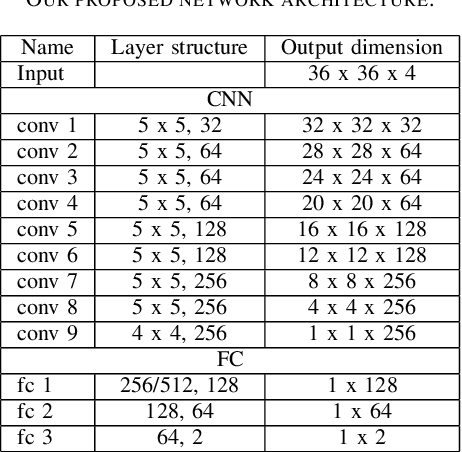
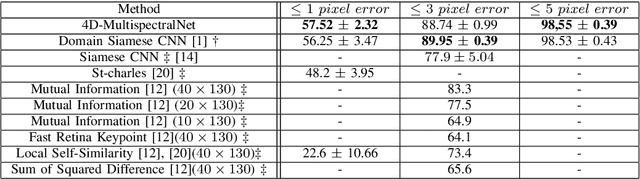
Multispectral stereoscopy is an emerging field. A lot of work has been done in classical stereoscopy, but multispectral stereoscopy is not studied as frequently. This type of stereoscopy can be used in autonomous vehicles to complete the information given by RGB cameras. It helps to identify objects in the surroundings when the conditions are more difficult, such as in night scenes. This paper focuses on the RGB-LWIR spectrum. RGB-LWIR stereoscopy has the same challenges as classical stereoscopy, that is occlusions, textureless surfaces and repetitive patterns, plus specific ones related to the different modalities. Finding matches between two spectrums adds another layer of complexity. Color, texture and shapes are more likely to vary from a spectrum to another. To address this additional challenge, this paper focuses on estimating the disparity of people present in a scene. Given the fact that people's shape is captured in both RGB and LWIR, we propose a novel method that uses segmentation masks of the human in both spectrum and than concatenate them to the original images before the first layer of a Siamese Network. This method helps to improve the accuracy, particularly within the one pixel error range.
ActAR: Actor-Driven Pose Embeddings for Video Action Recognition
Apr 19, 2022

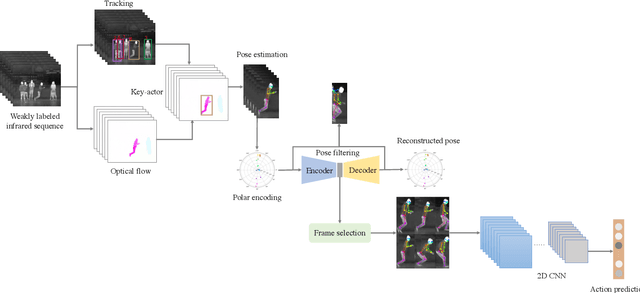
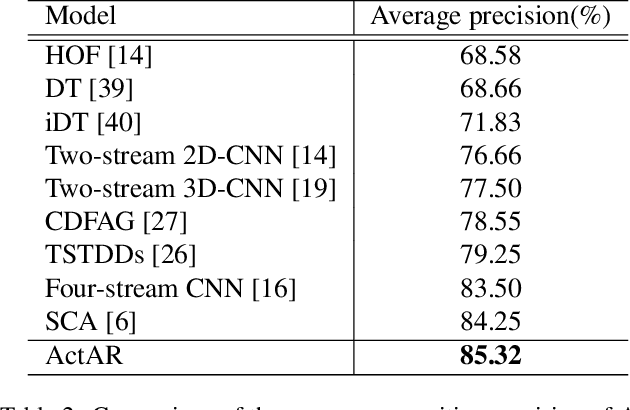
Human action recognition (HAR) in videos is one of the core tasks of video understanding. Based on video sequences, the goal is to recognize actions performed by humans. While HAR has received much attention in the visible spectrum, action recognition in infrared videos is little studied. Accurate recognition of human actions in the infrared domain is a highly challenging task because of the redundant and indistinguishable texture features present in the sequence. Furthermore, in some cases, challenges arise from the irrelevant information induced by the presence of multiple active persons not contributing to the actual action of interest. Therefore, most existing methods consider a standard paradigm that does not take into account these challenges, which is in some part due to the ambiguous definition of the recognition task in some cases. In this paper, we propose a new method that simultaneously learns to recognize efficiently human actions in the infrared spectrum, while automatically identifying the key-actors performing the action without using any prior knowledge or explicit annotations. Our method is composed of three stages. In the first stage, optical flow-based key-actor identification is performed. Then for each key-actor, we estimate key-poses that will guide the frame selection process. A scale-invariant encoding process along with embedded pose filtering are performed in order to enhance the quality of action representations. Experimental results on InfAR dataset show that our proposed model achieves promising recognition performance and learns useful action representations.
Transformers for 1D Signals in Parkinson's Disease Detection from Gait
Apr 01, 2022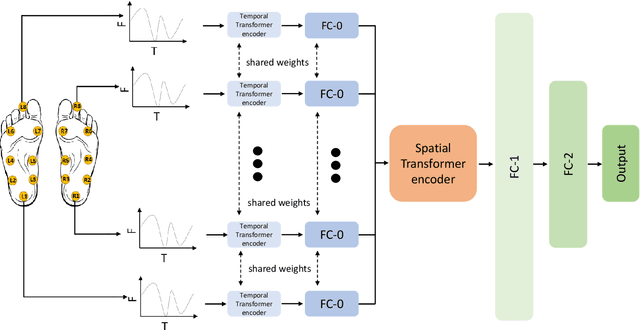
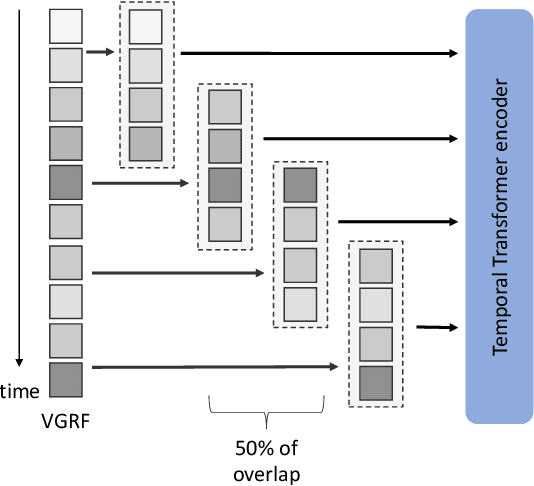
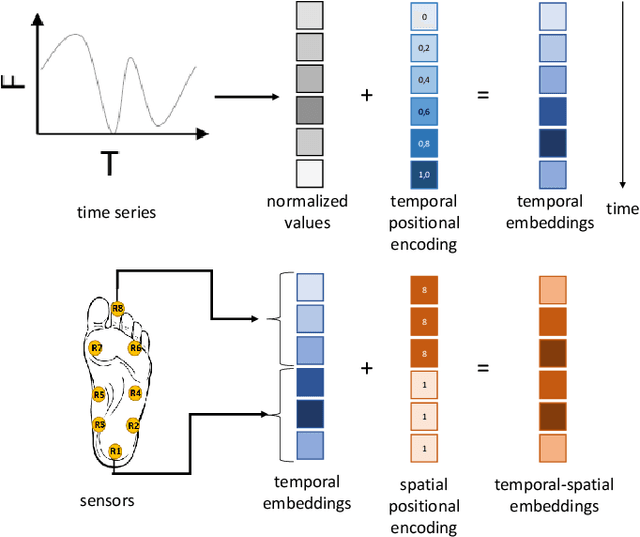
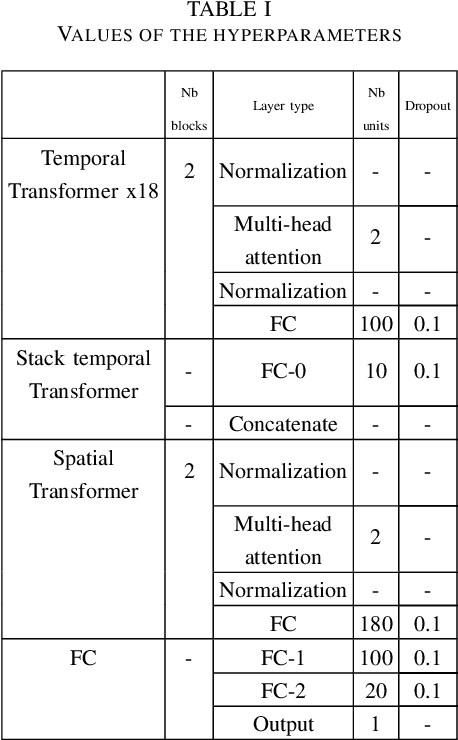
This paper focuses on the detection of Parkinson's disease based on the analysis of a patient's gait. The growing popularity and success of Transformer networks in natural language processing and image recognition motivated us to develop a novel method for this problem based on an automatic features extraction via Transformers. The use of Transformers in 1D signal is not really widespread yet, but we show in this paper that they are effective in extracting relevant features from 1D signals. As Transformers require a lot of memory, we decoupled temporal and spatial information to make the model smaller. Our architecture used temporal Transformers, dimension reduction layers to reduce the dimension of the data, a spatial Transformer, two fully connected layers and an output layer for the final prediction. Our model outperforms the current state-of-the-art algorithm with 95.2\% accuracy in distinguishing a Parkinsonian patient from a healthy one on the Physionet dataset. A key learning from this work is that Transformers allow for greater stability in results. The source code and pre-trained models are released in https://github.com/DucMinhDimitriNguyen/Transformers-for-1D-signals-in-Parkinson-s-disease-detection-from-gait.git
VPTR: Efficient Transformers for Video Prediction
Mar 29, 2022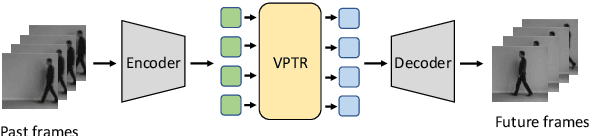
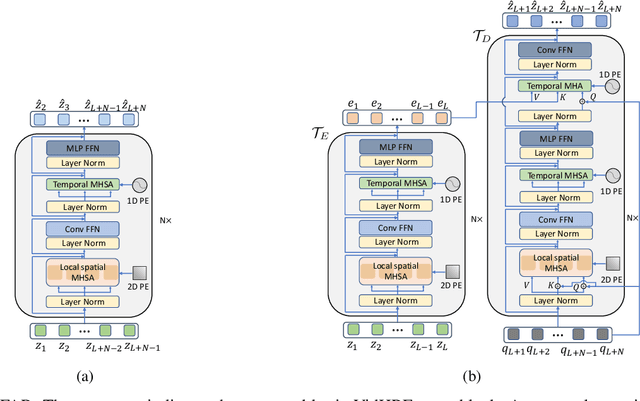
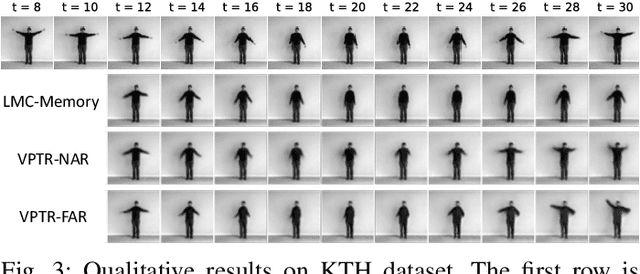
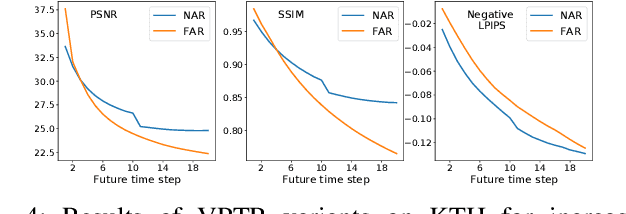
In this paper, we propose a new Transformer block for video future frames prediction based on an efficient local spatial-temporal separation attention mechanism. Based on this new Transformer block, a fully autoregressive video future frames prediction Transformer is proposed. In addition, a non-autoregressive video prediction Transformer is also proposed to increase the inference speed and reduce the accumulated inference errors of its autoregressive counterpart. In order to avoid the prediction of very similar future frames, a contrastive feature loss is applied to maximize the mutual information between predicted and ground-truth future frame features. This work is the first that makes a formal comparison of the two types of attention-based video future frames prediction models over different scenarios. The proposed models reach a performance competitive with more complex state-of-the-art models. The source code is available at \emph{https://github.com/XiYe20/VPTR}.
Leveraging Sentiment Analysis Knowledge to Solve Emotion Detection Tasks
Nov 05, 2021
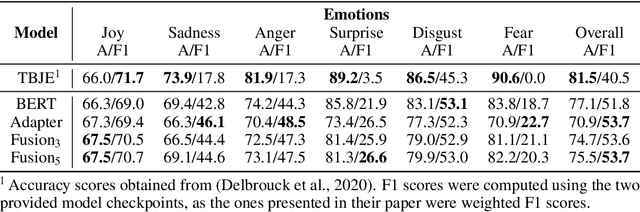
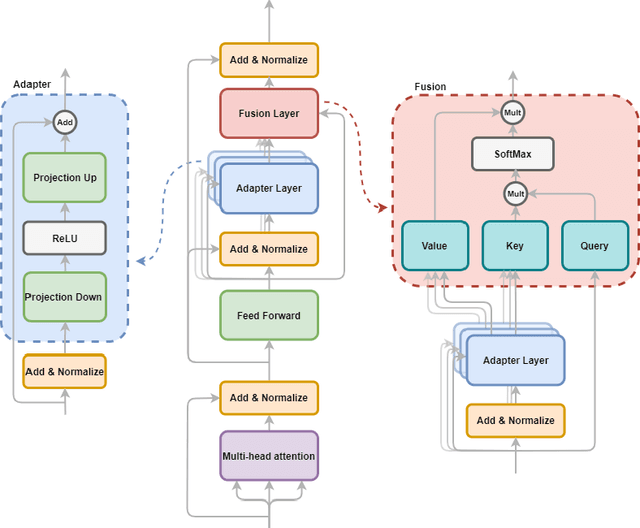

Identifying and understanding underlying sentiment or emotions in text is a key component of multiple natural language processing applications. While simple polarity sentiment analysis is a well-studied subject, fewer advances have been made in identifying more complex, finer-grained emotions using only textual data. In this paper, we present a Transformer-based model with a Fusion of Adapter layers which leverages knowledge from more simple sentiment analysis tasks to improve the emotion detection task on large scale dataset, such as CMU-MOSEI, using the textual modality only. Results show that our proposed method is competitive with other approaches. We obtained state-of-the-art results for emotion recognition on CMU-MOSEI even while using only the textual modality.
PolyTrack: Tracking with Bounding Polygons
Nov 02, 2021

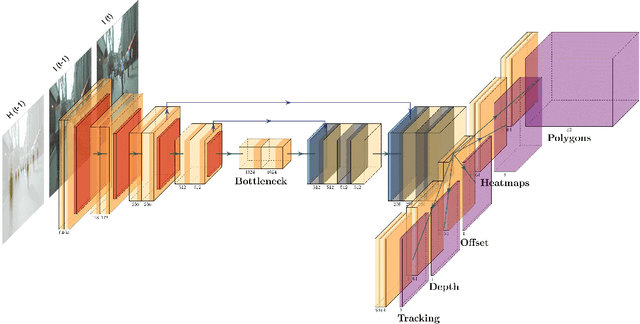
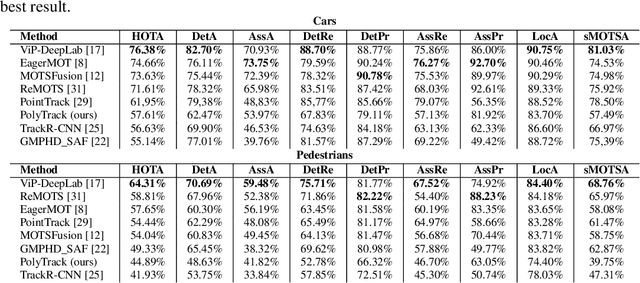
In this paper, we present a novel method called PolyTrack for fast multi-object tracking and segmentation using bounding polygons. Polytrack detects objects by producing heatmaps of their center keypoint. For each of them, a rough segmentation is done by computing a bounding polygon over each instance instead of the traditional bounding box. Tracking is done by taking two consecutive frames as input and computing a center offset for each object detected in the first frame to predict its location in the second frame. A Kalman filter is also applied to reduce the number of ID switches. Since our target application is automated driving systems, we apply our method on urban environment videos. We trained and evaluated PolyTrack on the MOTS and KITTIMOTS datasets. Results show that tracking polygons can be a good alternative to bounding box and mask tracking. The code of PolyTrack is available at https://github.com/gafaua/PolyTrack.
Multi-Object Tracking and Segmentation with a Space-Time Memory Network
Oct 21, 2021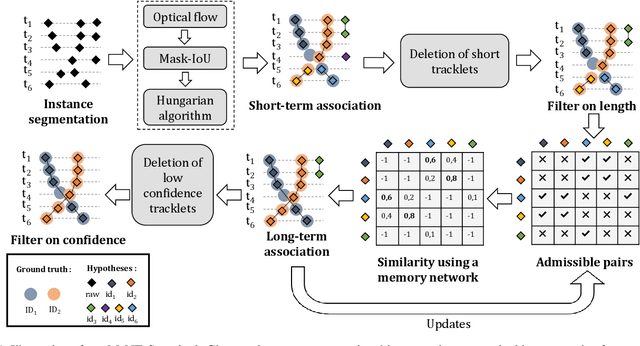
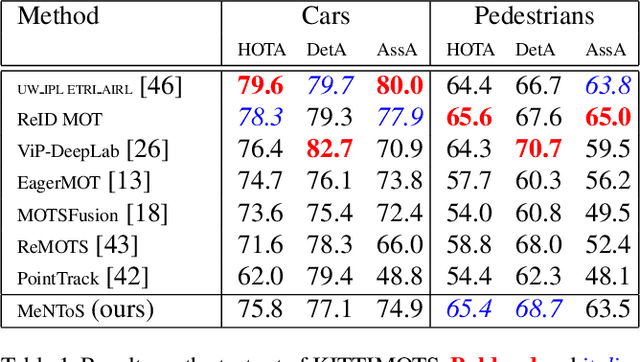
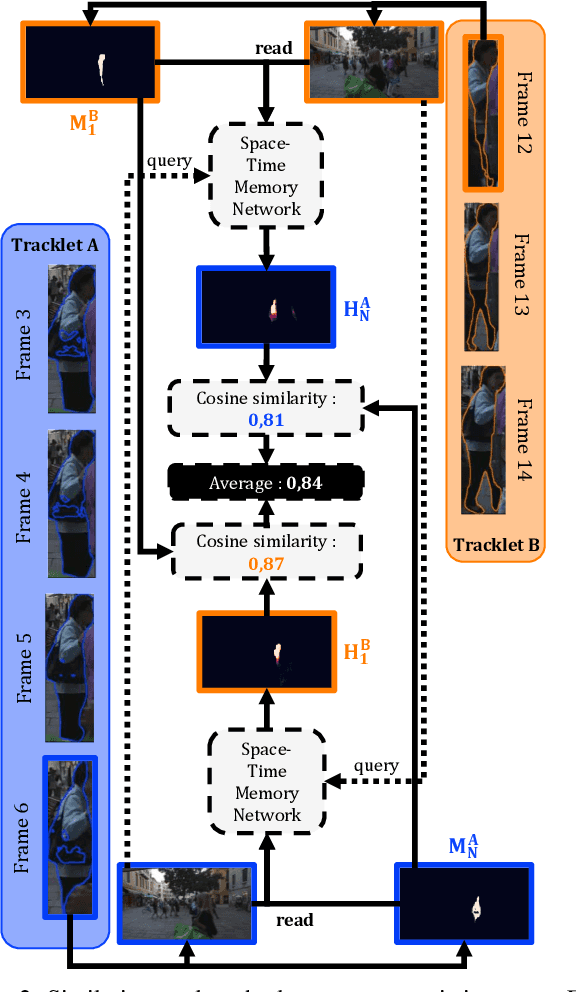
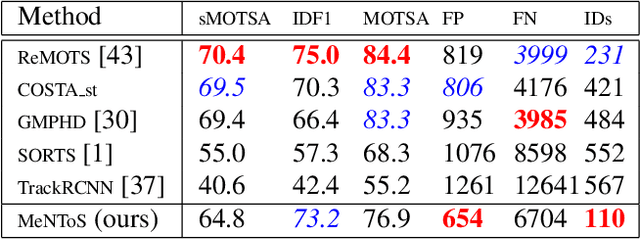
We propose a method for multi-object tracking and segmentation that does not require fine-tuning or per benchmark hyper-parameter selection. The proposed tracker, MeNToS, addresses particularly the data association problem. Indeed, the recently introduced HOTA metric, which has a better alignment with the human visual assessment by evenly balancing detections and associations quality, has shown that improvements are still needed for data association. After creating tracklets using instance segmentation and optical flow, the proposed method relies on a space-time memory network developed for one-shot video object segmentation to improve the association of tracklets with temporal gaps. We evaluated our tracker on KITTIMOTS and MOTSChallenge and show the benefit of our data association strategy with the HOTA metric. The project page is \url{www.mehdimiah.com/mentos+}.
Vehicle Detection and Tracking From Surveillance Cameras in Urban Scenes
Sep 25, 2021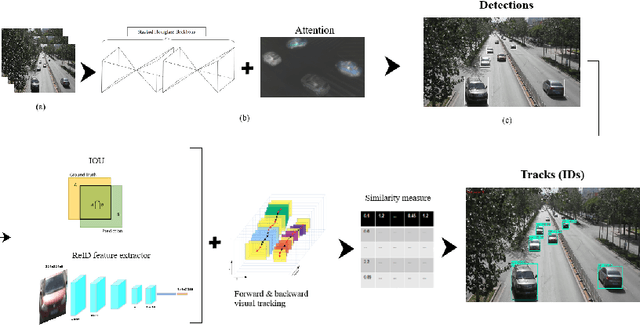
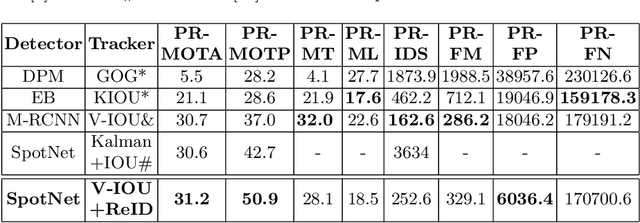
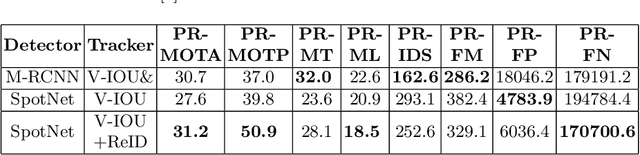
Detecting and tracking vehicles in urban scenes is a crucial step in many traffic-related applications as it helps to improve road user safety among other benefits. Various challenges remain unresolved in multi-object tracking (MOT) including target information description, long-term occlusions and fast motion. We propose a multi-vehicle detection and tracking system following the tracking-by-detection paradigm that tackles the previously mentioned challenges. Our MOT method extends an Intersection-over-Union (IOU)-based tracker with vehicle re-identification features. This allows us to utilize appearance information to better match objects after long occlusion phases and/or when object location is significantly shifted due to fast motion. We outperform our baseline MOT method on the UA-DETRAC benchmark while maintaining a total processing speed suitable for online use cases.
FFAVOD: Feature Fusion Architecture for Video Object Detection
Sep 15, 2021
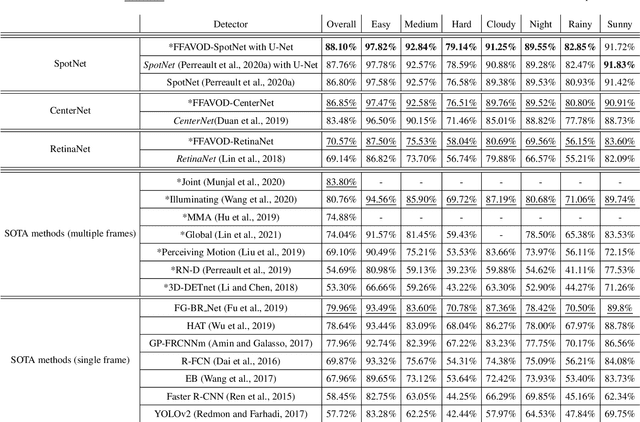
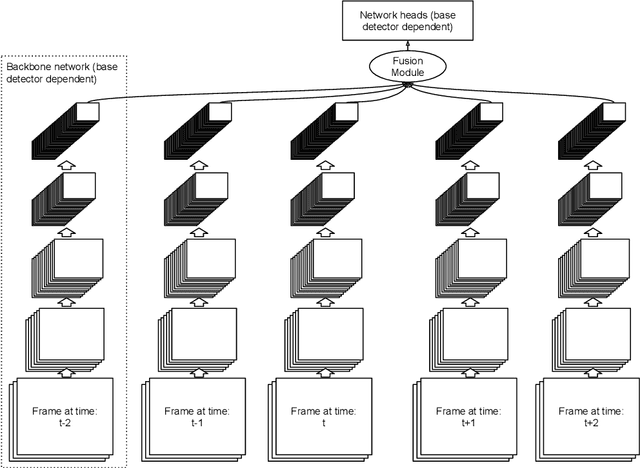
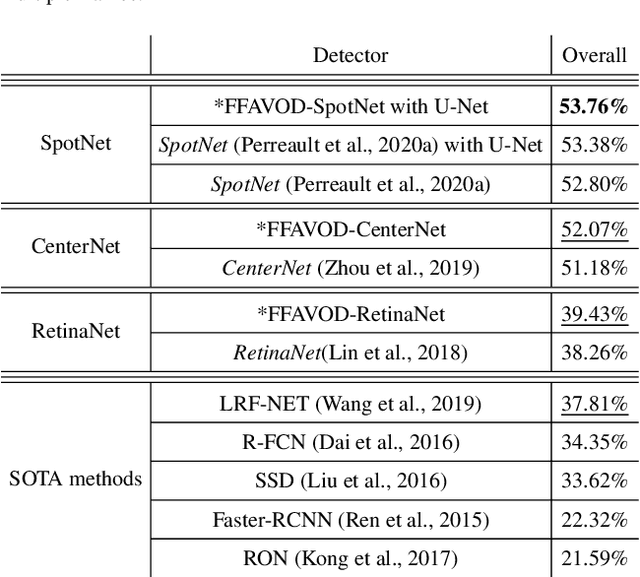
A significant amount of redundancy exists between consecutive frames of a video. Object detectors typically produce detections for one image at a time, without any capabilities for taking advantage of this redundancy. Meanwhile, many applications for object detection work with videos, including intelligent transportation systems, advanced driver assistance systems and video surveillance. Our work aims at taking advantage of the similarity between video frames to produce better detections. We propose FFAVOD, standing for feature fusion architecture for video object detection. We first introduce a novel video object detection architecture that allows a network to share feature maps between nearby frames. Second, we propose a feature fusion module that learns to merge feature maps to enhance them. We show that using the proposed architecture and the fusion module can improve the performance of three base object detectors on two object detection benchmarks containing sequences of moving road users. Additionally, to further increase performance, we propose an improvement to the SpotNet attention module. Using our architecture on the improved SpotNet detector, we obtain the state-of-the-art performance on the UA-DETRAC public benchmark as well as on the UAVDT dataset. Code is available at https://github.com/hu64/FFAVOD.
CenterPoly: real-time instance segmentation using bounding polygons
Aug 19, 2021
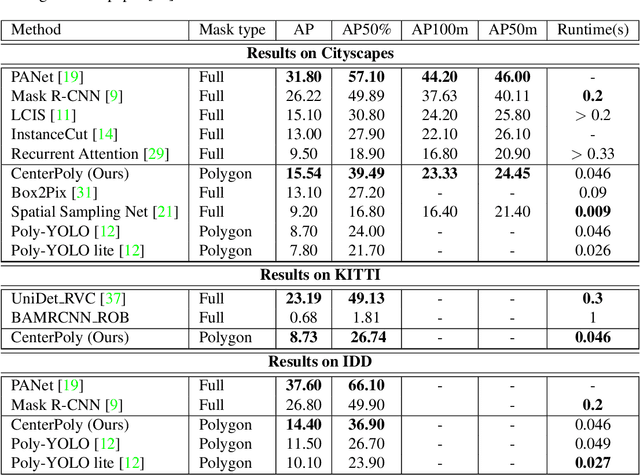
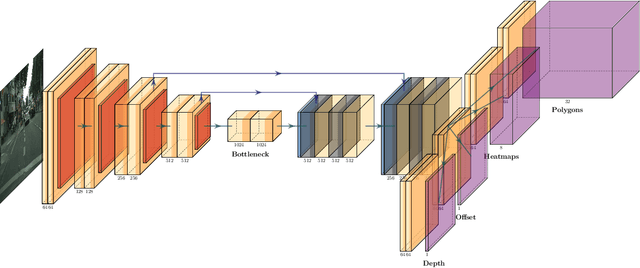
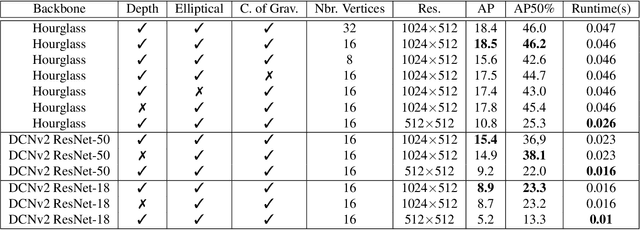
We present a novel method, called CenterPoly, for real-time instance segmentation using bounding polygons. We apply it to detect road users in dense urban environments, making it suitable for applications in intelligent transportation systems like automated vehicles. CenterPoly detects objects by their center keypoint while predicting a fixed number of polygon vertices for each object, thus performing detection and segmentation in parallel. Most of the network parameters are shared by the network heads, making it fast and lightweight enough to run at real-time speed. To properly convert mask ground-truth to polygon ground-truth, we designed a vertex selection strategy to facilitate the learning of the polygons. Additionally, to better segment overlapping objects in dense urban scenes, we also train a relative depth branch to determine which instances are closer and which are further, using available weak annotations. We propose several models with different backbones to show the possible speed / accuracy trade-offs. The models were trained and evaluated on Cityscapes, KITTI and IDD and the results are reported on their public benchmark, which are state-of-the-art at real-time speeds. Code is available at https://github.com/hu64/CenterPoly