 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Field Langevin Dynamics for Signed Measures via a Bilevel Approach
Jun 26, 2024Mean-field Langevin dynamics (MLFD) is a class of interacting particle methods that tackle convex optimization over probability measures on a manifold, which are scalable, versatile, and enjoy computational guarantees. However, some important problems -- such as risk minimization for infinite width two-layer neural networks, or sparse deconvolution -- are originally defined over the set of signed, rather than probability, measures. In this paper, we investigate how to extend the MFLD framework to convex optimization problems over signed measures. Among two known reductions from signed to probability measures -- the lifting and the bilevel approaches -- we show that the bilevel reduction leads to stronger guarantees and faster rates (at the price of a higher per-iteration complexity). In particular, we investigate the convergence rate of MFLD applied to the bilevel reduction in the low-noise regime and obtain two results. First, this dynamics is amenable to an annealing schedule, adapted from Suzuki et al. (2023), that results in improved convergence rates to a fixed multiplicative accuracy. Second, we investigate the problem of learning a single neuron with the bilevel approach and obtain local exponential convergence rates that depend polynomially on the dimension and noise level (to compare with the exponential dependence that would result from prior analyses).
Local Convergence of Gradient Methods for Min-Max Games under Partial Curvature
May 26, 2023We study the convergence to local Nash equilibria of gradient methods for two-player zero-sum differentiable games. It is well-known that such dynamics converge locally when $S \succ 0$ and may diverge when $S=0$, where $S\succeq 0$ is the symmetric part of the Jacobian at equilibrium that accounts for the "potential" component of the game. We show that these dynamics also converge as soon as $S$ is nonzero (partial curvature) and the eigenvectors of the antisymmetric part $A$ are in general position with respect to the kernel of $S$. We then study the convergence rates when $S \ll A$ and prove that they typically depend on the average of the eigenvalues of $S$, instead of the minimum as an analogy with minimization problems would suggest. To illustrate our results, we consider the problem of computing mixed Nash equilibria of continuous games. We show that, thanks to partial curvature, conic particle methods -- which optimize over both weights and supports of the mixed strategies -- generically converge faster than fixed-support methods. For min-max games, it is thus beneficial to add degrees of freedom "with curvature": this can be interpreted as yet another benefit of over-parameterization.
An Exponentially Converging Particle Method for the Mixed Nash Equilibrium of Continuous Games
Nov 02, 2022



We consider the problem of computing mixed Nash equilibria of two-player zero-sum games with continuous sets of pure strategies and with first-order access to the payoff function. This problem arises for example in game-theory-inspired machine learning applications, such as distributionally-robust learning. In those applications, the strategy sets are high-dimensional and thus methods based on discretisation cannot tractably return high-accuracy solutions. In this paper, we introduce and analyze a particle-based method that enjoys guaranteed local convergence for this problem. This method consists in parametrizing the mixed strategies as atomic measures and applying proximal point updates to both the atoms' weights and positions. It can be interpreted as a time-implicit discretization of the "interacting" Wasserstein-Fisher-Rao gradient flow. We prove that, under non-degeneracy assumptions, this method converges at an exponential rate to the exact mixed Nash equilibrium from any initialization satisfying a natural notion of closeness to optimality. We illustrate our results with numerical experiments and discuss applications to max-margin and distributionally-robust classification using two-layer neural networks, where our method has a natural interpretation as a simultaneous training of the network's weights and of the adversarial distribution.
Tight bounds for minimum l1-norm interpolation of noisy data
Nov 10, 2021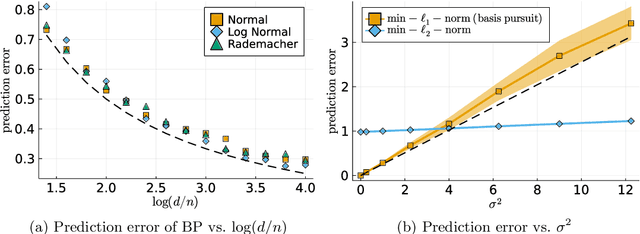
We provide matching upper and lower bounds of order $\sigma^2/\log(d/n)$ for the prediction error of the minimum $\ell_1$-norm interpolator, a.k.a. basis pursuit. Our result is tight up to negligible terms when $d \gg n$, and is the first to imply asymptotic consistency of noisy minimum-norm interpolation for isotropic features and sparse ground truths. Our work complements the literature on "benign overfitting" for minimum $\ell_2$-norm interpolation, where asymptotic consistency can be achieved only when the features are effectively low-dimensional.