 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Noise-Robust Loss for Unlabeled Entity Problem in Named Entity Recognition
Aug 05, 2022Named Entity Recognition (NER) is an important task in natural language processing. However, traditional supervised NER requires large-scale annotated datasets. Distantly supervision is proposed to alleviate the massive demand for datasets, but datasets constructed in this way are extremely noisy and have a serious unlabeled entity problem. The cross entropy (CE) loss function is highly sensitive to unlabeled data, leading to severe performance degradation. As an alternative, we propose a new loss function called NRCES to cope with this problem. A sigmoid term is used to mitigate the negative impact of noise. In addition, we balance the convergence and noise tolerance of the model according to samples and the training process. Experiments on synthetic and real-world datasets demonstrate that our approach shows strong robustness in the case of severe unlabeled entity problem, achieving new state-of-the-art on real-world datasets.
A More Efficient Chinese Named Entity Recognition base on BERT and Syntactic Analysis
Jan 11, 2021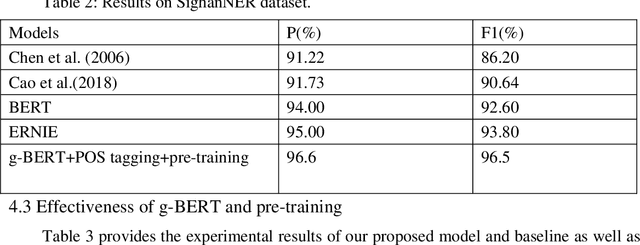
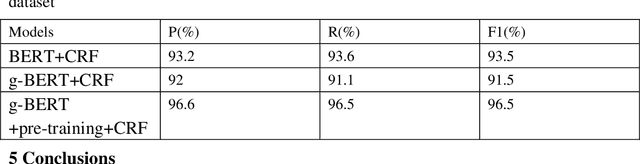
We propose a new Named entity recognition (NER) method to effectively make use of the results of Part-of-speech (POS) tagging, Chinese word segmentation (CWS) and parsing while avoiding NER error caused by POS tagging error. This paper first uses Stanford natural language process (NLP) tool to annotate large-scale untagged data so as to reduce the dependence on the tagged data; then a new NLP model, g-BERT model, is designed to compress Bidirectional Encoder Representations from Transformers (BERT) model in order to reduce calculation quantity; finally, the model is evaluated based on Chinese NER dataset. The experimental results show that the calculation quantity in g-BERT model is reduced by 60% and performance improves by 2% with Test F1 to 96.5 compared with that in BERT model.