 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDEN: A Large-Scale Corpus of Clinical Notes for Italian
Jun 10, 2026We present EDEN (Emergency Department Electronic Notes), a new and unique large-scale corpus of clinical notes produced in Emergency Departments of Italian hospitals. The corpus, in its current version, is composed of approximately 4 million clinical notes fully anonymized, covering diverse phases of patient care during the stay in the emergency department. In addition, a subset of about six thousand notes has been manually annotated by clinical experts through a structured Case Report Form (CRF) containing 132 items relevant for two patient situations in emergency departments, dyspnea and loss of consciousness. Items may assume numerical values (e.g., for blood saturation), categorical (e.g., for level of consciousness ), binary (e.g., for presence of traumas), and mixed value types. The annotation process involved multiple clinicians and underwent iterative revision to resolve ambiguities in item formulation, resulting in a richly structured (although high imbalanced) resource. The dataset aims to fill a relevant gap of data able to support both the development and the use of Large Language Models in concrete medical applications. We describe the data collection protocol, the on-site anonymisation pipeline, corpus statistics, and the annotation scheme. Finally, we propose CRF-filling as a novel structured information extraction benchmark, and provide zero-shot baseline resulting from Gemma-27B and MedGemma-27B. To the best of our knowledge, the EDEN dataset is the largest freely available corpus of clinical notes existing for the Italian language.
Automatic lesion analysis for increased efficiency in outcome prediction of traumatic brain injury
Aug 08, 2022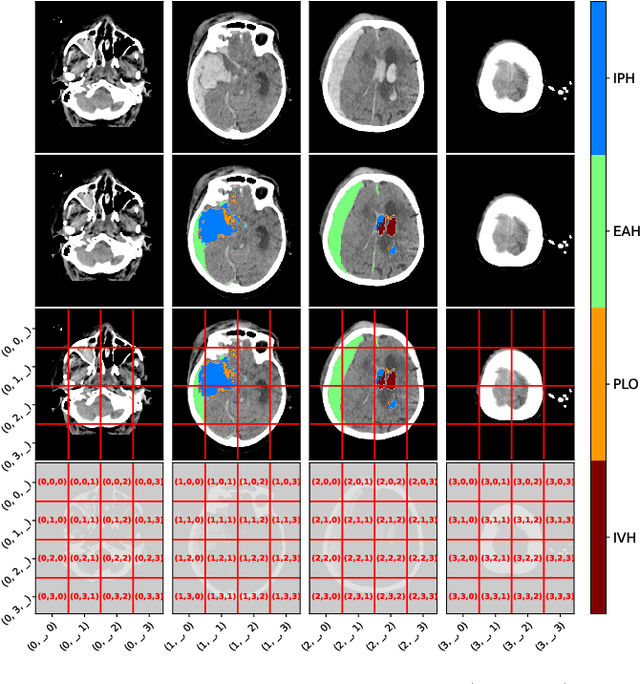
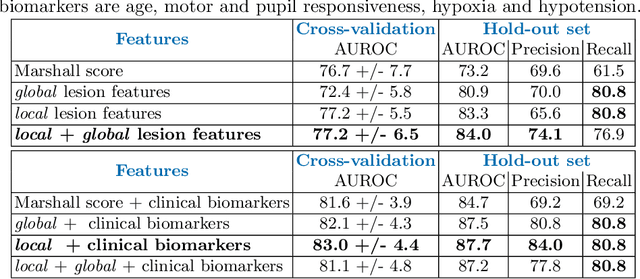
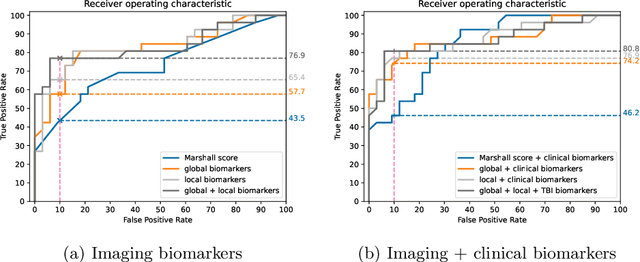
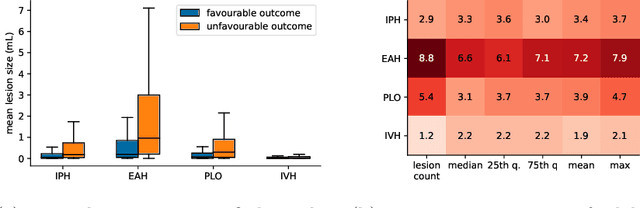
The accurate prognosis for traumatic brain injury (TBI) patients is difficult yet essential to inform therapy, patient management, and long-term after-care. Patient characteristics such as age, motor and pupil responsiveness, hypoxia and hypotension, and radiological findings on computed tomography (CT), have been identified as important variables for TBI outcome prediction. CT is the acute imaging modality of choice in clinical practice because of its acquisition speed and widespread availability. However, this modality is mainly used for qualitative and semi-quantitative assessment, such as the Marshall scoring system, which is prone to subjectivity and human errors. This work explores the predictive power of imaging biomarkers extracted from routinely-acquired hospital admission CT scans using a state-of-the-art, deep learning TBI lesion segmentation method. We use lesion volumes and corresponding lesion statistics as inputs for an extended TBI outcome prediction model. We compare the predictive power of our proposed features to the Marshall score, independently and when paired with classic TBI biomarkers. We find that automatically extracted quantitative CT features perform similarly or better than the Marshall score in predicting unfavourable TBI outcomes. Leveraging automatic atlas alignment, we also identify frontal extra-axial lesions as important indicators of poor outcome. Our work may contribute to a better understanding of TBI, and provides new insights into how automated neuroimaging analysis can be used to improve prognostication after TBI.