 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding representative sets of optimizations for adaptive multiversioning applications
Jul 14, 2014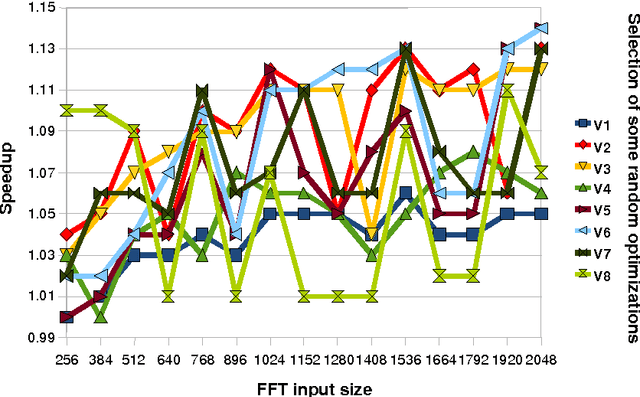

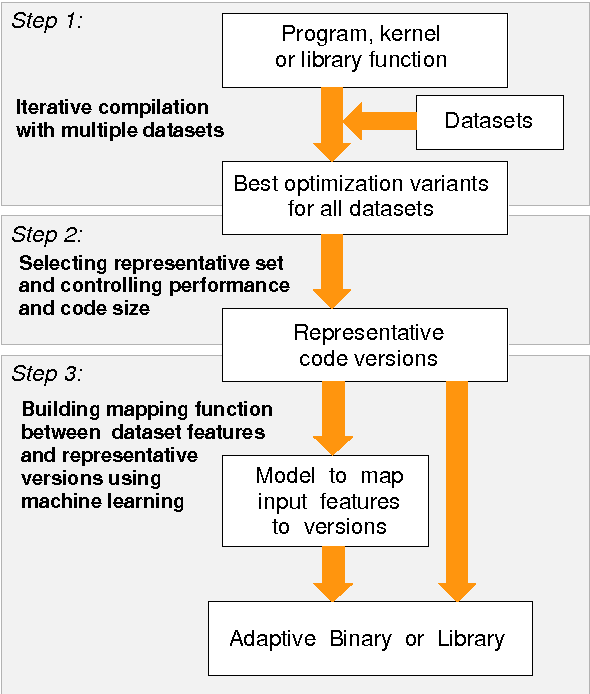
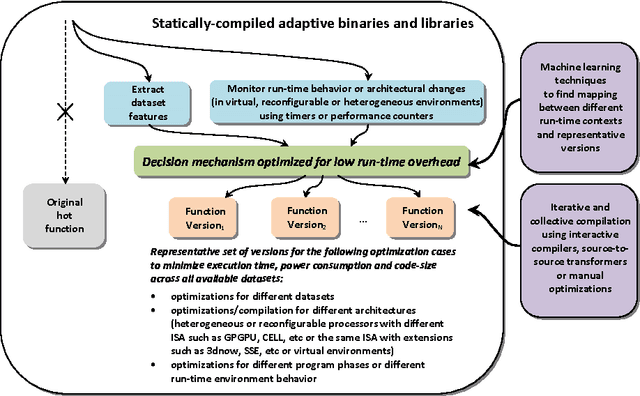
Iterative compilation is a widely adopted technique to optimize programs for different constraints such as performance, code size and power consumption in rapidly evolving hardware and software environments. However, in case of statically compiled programs, it is often restricted to optimizations for a specific dataset and may not be applicable to applications that exhibit different run-time behavior across program phases, multiple datasets or when executed in heterogeneous, reconfigurable and virtual environments. Several frameworks have been recently introduced to tackle these problems and enable run-time optimization and adaptation for statically compiled programs based on static function multiversioning and monitoring of online program behavior. In this article, we present a novel technique to select a minimal set of representative optimization variants (function versions) for such frameworks while avoiding performance loss across available datasets and code-size explosion. We developed a novel mapping mechanism using popular decision tree or rule induction based machine learning techniques to rapidly select best code versions at run-time based on dataset features and minimize selection overhead. These techniques enable creation of self-tuning static binaries or libraries adaptable to changing behavior and environments at run-time using staged compilation that do not require complex recompilation frameworks while effectively outperforming traditional single-version non-adaptable code.
Collective Mind: cleaning up the research and experimentation mess in computer engineering using crowdsourcing, big data and machine learning
Aug 11, 2013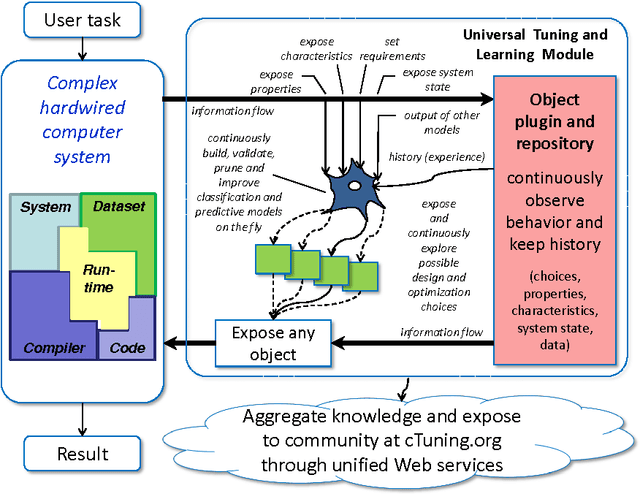
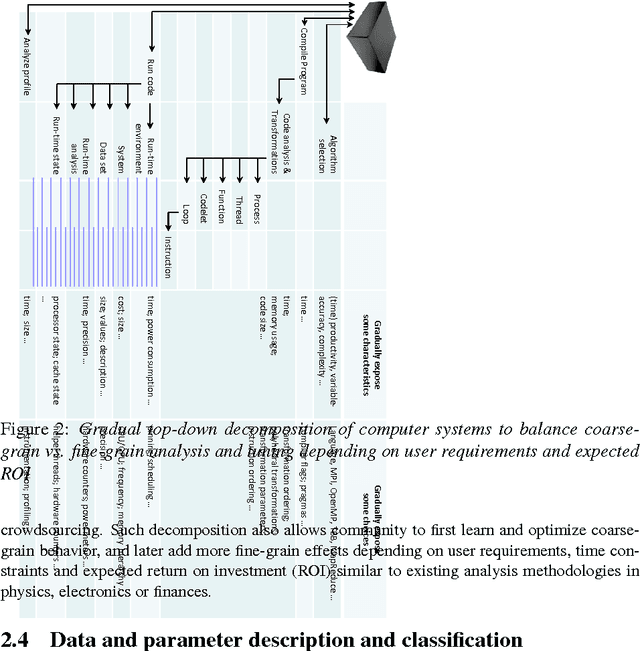
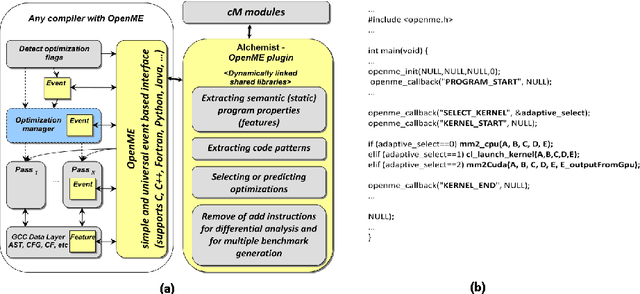
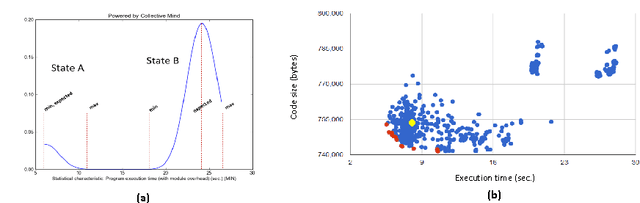
Software and hardware co-design and optimization of HPC systems has become intolerably complex, ad-hoc, time consuming and error prone due to enormous number of available design and optimization choices, complex interactions between all software and hardware components, and multiple strict requirements placed on performance, power consumption, size, reliability and cost. We present our novel long-term holistic and practical solution to this problem based on customizable, plugin-based, schema-free, heterogeneous, open-source Collective Mind repository and infrastructure with unified web interfaces and on-line advise system. This collaborative framework distributes analysis and multi-objective off-line and on-line auto-tuning of computer systems among many participants while utilizing any available smart phone, tablet, laptop, cluster or data center, and continuously observing, classifying and modeling their realistic behavior. Any unexpected behavior is analyzed using shared data mining and predictive modeling plugins or exposed to the community at cTuning.org for collaborative explanation, top-down complexity reduction, incremental problem decomposition and detection of correlating program, architecture or run-time properties (features). Gradually increasing optimization knowledge helps to continuously improve optimization heuristics of any compiler, predict optimizations for new programs or suggest efficient run-time (online) tuning and adaptation strategies depending on end-user requirements. We decided to share all our past research artifacts including hundreds of codelets, numerical applications, data sets, models, universal experimental analysis and auto-tuning pipelines, self-tuning machine learning based meta compiler, and unified statistical analysis and machine learning plugins in a public repository to initiate systematic, reproducible and collaborative research, development and experimentation with a new publication model where experiments and techniques are validated, ranked and improved by the community.