 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Earnings Call and Stock Price Movement
Aug 23, 2020



Earnings calls are hosted by management of public companies to discuss the company's financial performance with analysts and investors. Information disclosed during an earnings call is an essential source of data for analysts and investors to make investment decisions. Thus, we leverage earnings call transcripts to predict future stock price dynamics. We propose to model the language in transcripts using a deep learning framework, where an attention mechanism is applied to encode the text data into vectors for the discriminative network classifier to predict stock price movements. Our empirical experiments show that the proposed model is superior to the traditional machine learning baselines and earnings call information can boost the stock price prediction performance.
Empirical Study on Detecting Controversy in Social Media
Aug 25, 2019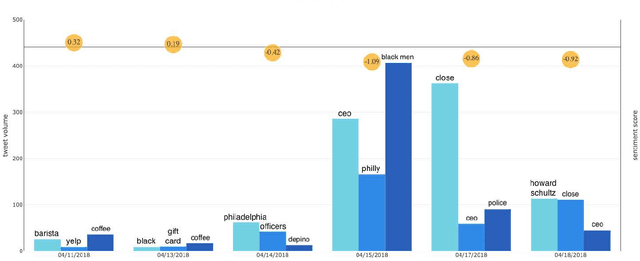
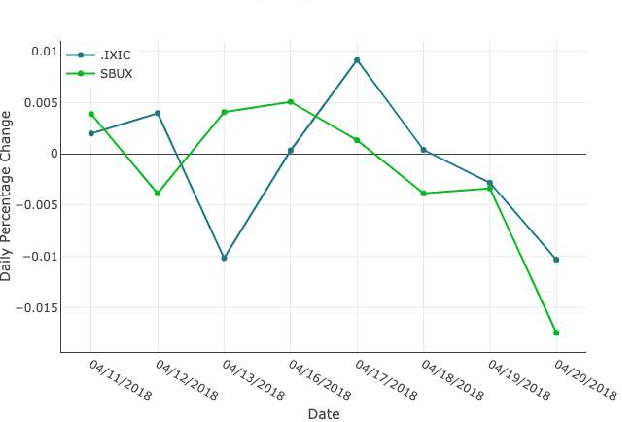
Companies and financial investors are paying increasing attention to social consciousness in developing their corporate strategies and making investment decisions to support a sustainable economy for the future. Public discussion on incidents and events--controversies --of companies can provide valuable insights on how well the company operates with regards to social consciousness and indicate the company's overall operational capability. However, there are challenges in evaluating the degree of a company's social consciousness and environmental sustainability due to the lack of systematic data. We introduce a system that utilizes Twitter data to detect and monitor controversial events and show their impact on market volatility. In our study, controversial events are identified from clustered tweets that share the same 5W terms and sentiment polarities of these clusters. Credible news links inside the event tweets are used to validate the truth of the event. A case study on the Starbucks Philadelphia arrests shows that this method can provide the desired functionality.
A framework for anomaly detection using language modeling, and its applications to finance
Aug 24, 2019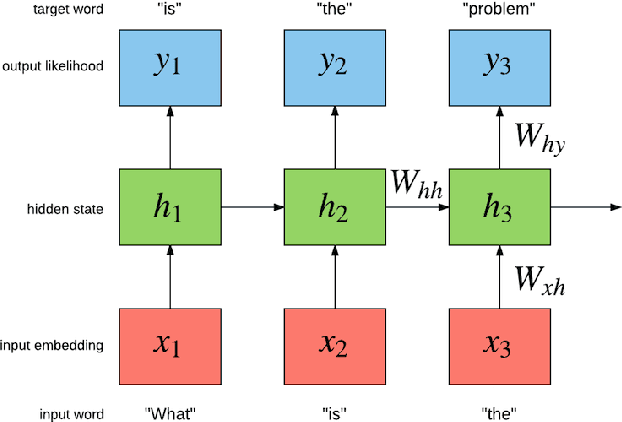
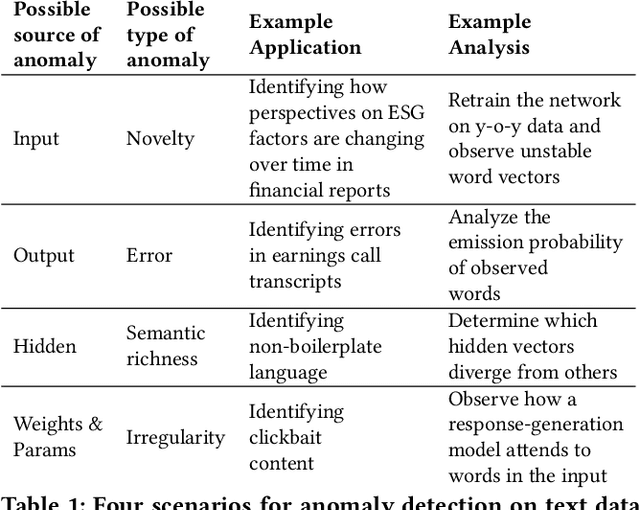
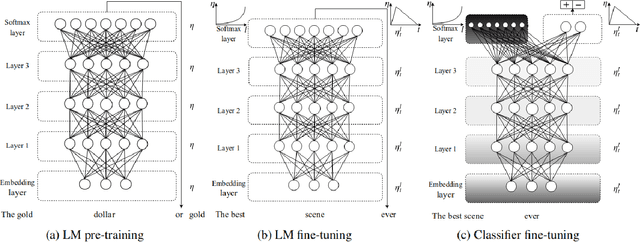
In the finance sector, studies focused on anomaly detection are often associated with time-series and transactional data analytics. In this paper, we lay out the opportunities for applying anomaly and deviation detection methods to text corpora and challenges associated with them. We argue that language models that use distributional semantics can play a significant role in advancing these studies in novel directions, with new applications in risk identification, predictive modeling, and trend analysis.