 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOLD-TR: A Scalable and Efficient Inductive Learning Algorithm for Learning To Rank
Jun 15, 2022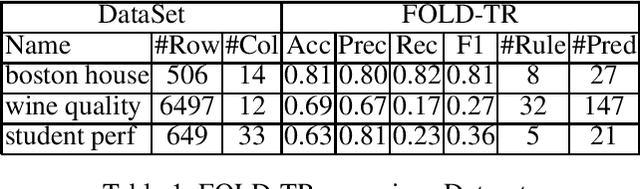
FOLD-R++ is a new inductive learning algorithm for binary classification tasks. It generates an (explainable) normal logic program for mixed type (numerical and categorical) data. We present a customized FOLD-R++ algorithm with the ranking framework, called FOLD-TR, that aims to rank new items following the ranking pattern in the training data. Like FOLD-R++, the FOLD-TR algorithm is able to handle mixed-type data directly and provide native justification to explain the comparison between a pair of items.
FOLD-RM: A Scalable and Efficient Inductive Learning Algorithm for Multi-Category Classification of Mixed Data
Feb 25, 2022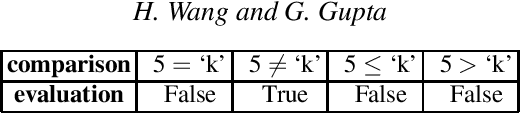

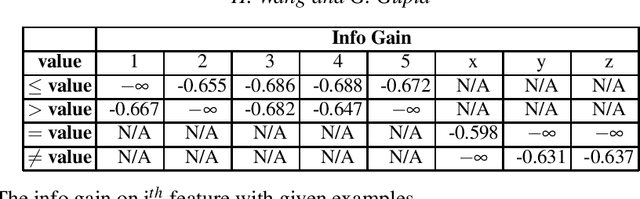
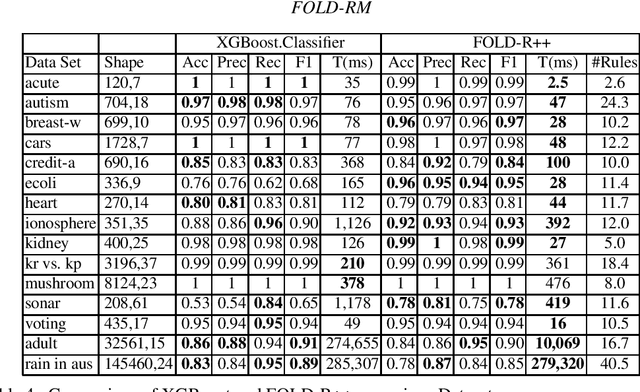
FOLD-RM is an automated inductive learning algorithm for learning default rules for mixed (numerical and categorical) data. It generates an (explainable) answer set programming (ASP) rule set for multi-category classification tasks while maintaining efficiency and scalability. The FOLD-RM algorithm is competitive in performance with the widely-used XGBoost algorithm, however, unlike XGBoost, the FOLD-RM algorithm produces an explainable model. FOLD-RM outperforms XGBoost on some datasets, particularly large ones. FOLD-RM also provides human-friendly explanations for predictions.
An ASP-based Approach to Answering Natural Language Questions for Texts
Dec 21, 2021
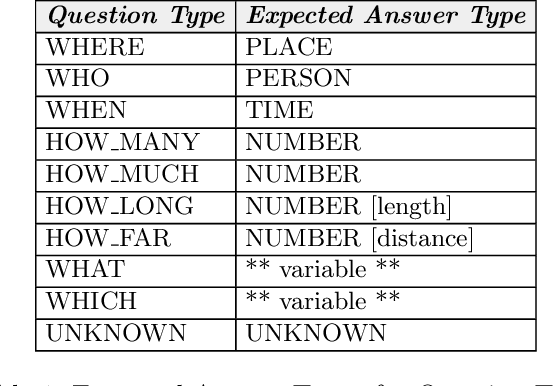
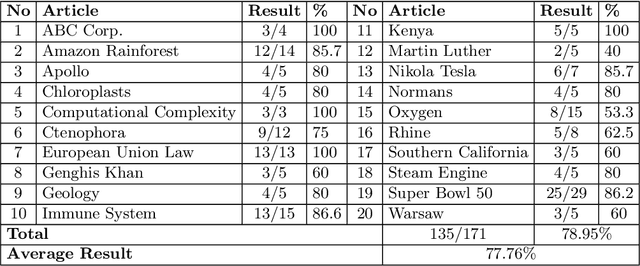
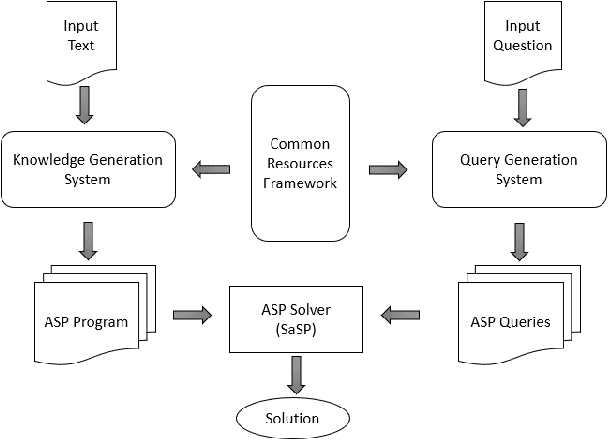
An approach based on answer set programming (ASP) is proposed in this paper for representing knowledge generated from natural language texts. Knowledge in a text is modeled using a Neo Davidsonian-like formalism, which is then represented as an answer set program. Relevant commonsense knowledge is additionally imported from resources such as WordNet and represented in ASP. The resulting knowledge-base can then be used to perform reasoning with the help of an ASP system. This approach can facilitate many natural language tasks such as automated question answering, text summarization, and automated question generation. ASP-based representation of techniques such as default reasoning, hierarchical knowledge organization, preferences over defaults, etc., are used to model commonsense reasoning methods required to accomplish these tasks. In this paper, we describe the CASPR system that we have developed to automate the task of answering natural language questions given English text. CASPR can be regarded as a system that answers questions by "understanding" the text and has been tested on the SQuAD data set, with promising results.
Parallel Logic Programming: A Sequel
Nov 22, 2021
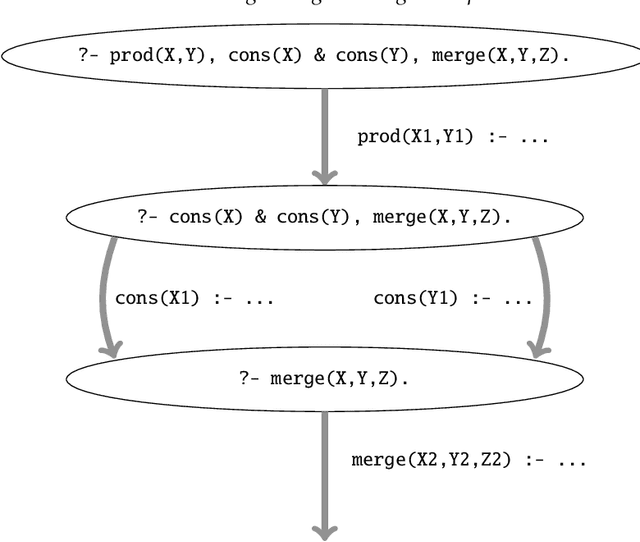
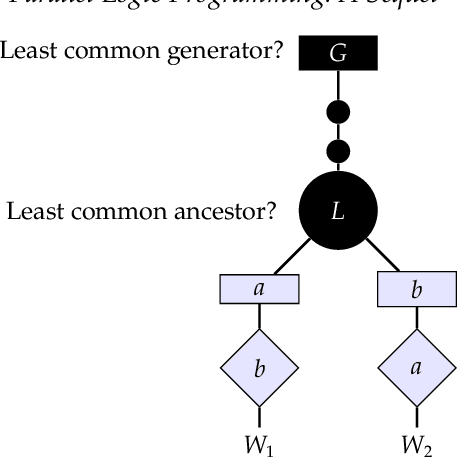
Multi-core and highly-connected architectures have become ubiquitous, and this has brought renewed interest in language-based approaches to the exploitation of parallelism. Since its inception, logic programming has been recognized as a programming paradigm with great potential for automated exploitation of parallelism. The comprehensive survey of the first twenty years of research in parallel logic programming, published in 2001, has served since as a fundamental reference to researchers and developers. The contents are quite valid today, but at the same time the field has continued evolving at a fast pace in the years that have followed. Many of these achievements and ongoing research have been driven by the rapid pace of technological innovation, that has led to advances such as very large clusters, the wide diffusion of multi-core processors, the game-changing role of general-purpose graphic processing units, and the ubiquitous adoption of cloud computing. This has been paralleled by significant advances within logic programming, such as tabling, more powerful static analysis and verification, the rapid growth of Answer Set Programming, and in general, more mature implementations and systems. This survey provides a review of the research in parallel logic programming covering the period since 2001, thus providing a natural continuation of the previous survey. The goal of the survey is to serve not only as a reference for researchers and developers of logic programming systems, but also as engaging reading for anyone interested in logic and as a useful source for researchers in parallel systems outside logic programming. Under consideration in Theory and Practice of Logic Programming (TPLP).
Towards Dynamic Consistency Checking in Goal-directed Predicate Answer Set Programming
Oct 22, 2021
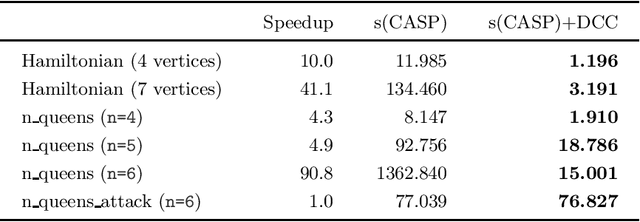

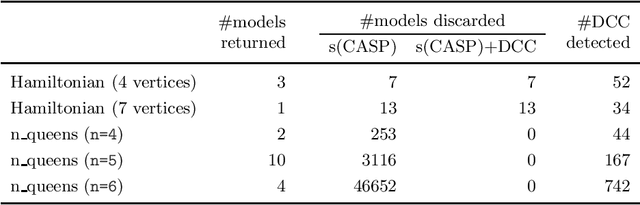
Goal-directed evaluation of Answer Set Programs is gaining traction thanks to its amenability to create AI systems that can, due to the evaluation mechanism used, generate explanations and justifications. s(CASP) is one of these systems and has been already used to write reasoning systems in several fields. It provides enhanced expressiveness w.r.t. other ASP systems due to its ability to use constraints, data structures, and unbound variables natively. However, the performance of existing s(CASP) implementations is not on par with other ASP systems: model consistency is checked once models have been generated, in keeping with the generate-and-test paradigm. In this work, we present a variation of the top-down evaluation strategy, termed Dynamic Consistency Checking, which interleaves model generation and consistency checking. This makes it possible to determine when a literal is not compatible with the denials associated to the global constraints in the program, prune the current execution branch, and choose a different alternative. This strategy is specially (but not exclusively) relevant in problems with a high combinatorial component. We have experimentally observed speedups of up to 90x w.r.t. the standard versions of s(CASP).
AUTO-DISCERN: Autonomous Driving Using Common Sense Reasoning
Oct 17, 2021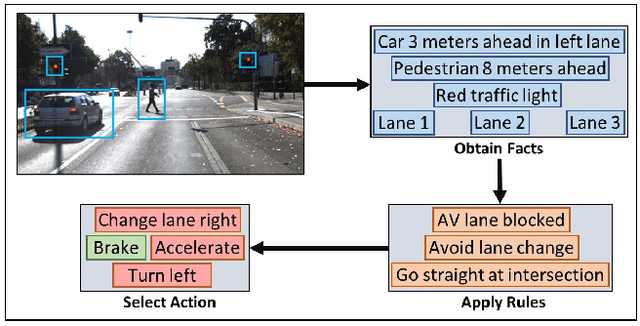
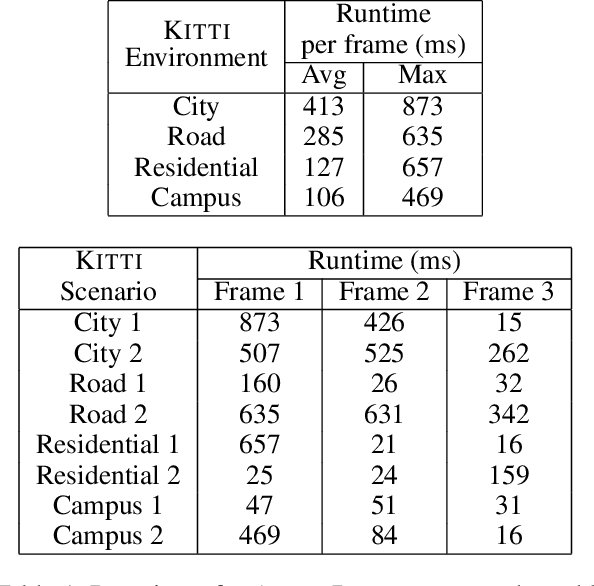


Driving an automobile involves the tasks of observing surroundings, then making a driving decision based on these observations (steer, brake, coast, etc.). In autonomous driving, all these tasks have to be automated. Autonomous driving technology thus far has relied primarily on machine learning techniques. We argue that appropriate technology should be used for the appropriate task. That is, while machine learning technology is good for observing and automatically understanding the surroundings of an automobile, driving decisions are better automated via commonsense reasoning rather than machine learning. In this paper, we discuss (i) how commonsense reasoning can be automated using answer set programming (ASP) and the goal-directed s(CASP) ASP system, and (ii) develop the AUTO-DISCERN system using this technology for automating decision-making in driving. The goal of our research, described in this paper, is to develop an autonomous driving system that works by simulating the mind of a human driver. Since driving decisions are based on human-style reasoning, they are explainable, their ethics can be ensured, and they will always be correct, provided the system modeling and system inputs are correct.
FOLD-R++: A Toolset for Automated Inductive Learning of Default Theories from Mixed Data
Oct 15, 2021
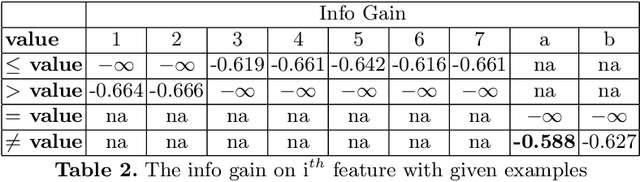
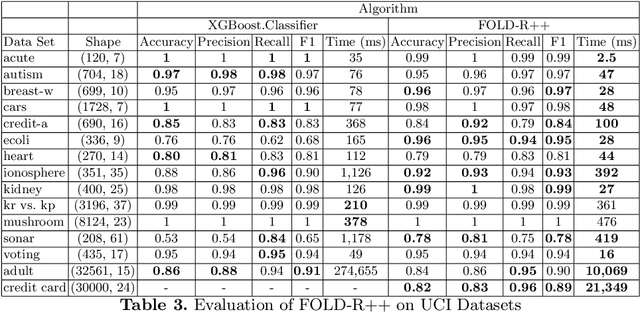
FOLD-R is an automated inductive learning algorithm for learning default rules with exceptions for mixed (numerical and categorical) data. It generates an (explainable) answer set programming (ASP) rule set for classification tasks. We present an improved FOLD-R algorithm, called FOLD-R++, that significantly increases the efficiency and scalability of FOLD-R. FOLD-R++ improves upon FOLD-R without compromising or losing information in the input training data during the encoding or feature selection phase. The FOLD-R++ algorithm is competitive in performance with the widely-used XGBoost algorithm, however, unlike XGBoost, the FOLD-R++ algorithm produces an explainable model. Next, we create a powerful tool-set by combining FOLD-R++ with s(CASP)-a goal-directed ASP execution engine-to make predictions on new data samples using the answer set program generated by FOLD-R++. The s(CASP) system also produces a justification for the prediction. Experiments presented in this paper show that our improved FOLD-R++ algorithm is a significant improvement over the original design and that the s(CASP) system can make predictions in an efficient manner as well.
CASPR: A Commonsense Reasoning-based Conversational Socialbot
Oct 11, 2021
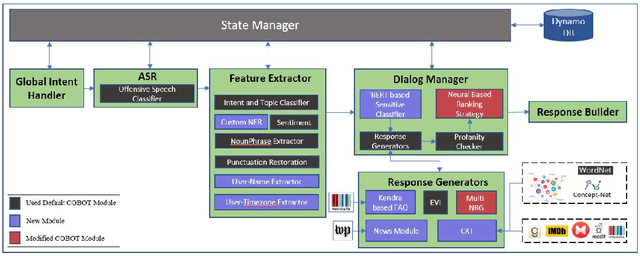
We report on the design and development of the CASPR system, a socialbot designed to compete in the Amazon Alexa Socialbot Challenge 4. CASPR's distinguishing characteristic is that it will use automated commonsense reasoning to truly "understand" dialogs, allowing it to converse like a human. Three main requirements of a socialbot are that it should be able to "understand" users' utterances, possess a strategy for holding a conversation, and be able to learn new knowledge. We developed techniques such as conversational knowledge template (CKT) to approximate commonsense reasoning needed to hold a conversation on specific topics. We present the philosophy behind CASPR's design as well as details of its implementation. We also report on CASPR's performance as well as discuss lessons learned.
A Clustering and Demotion Based Algorithm for Inductive Learning of Default Theories
Sep 26, 2021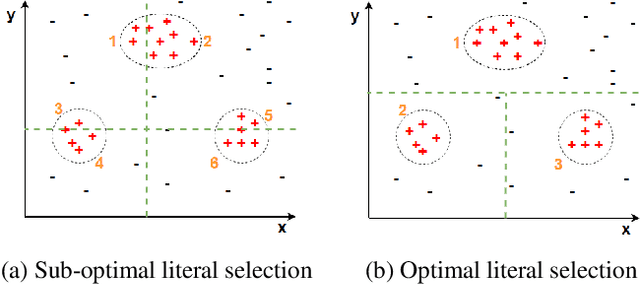
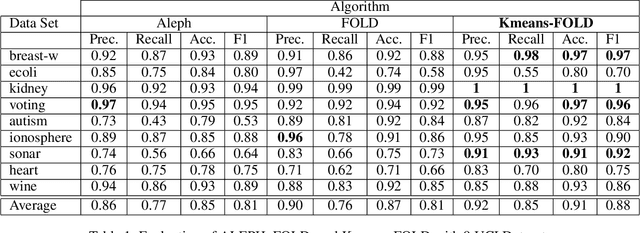
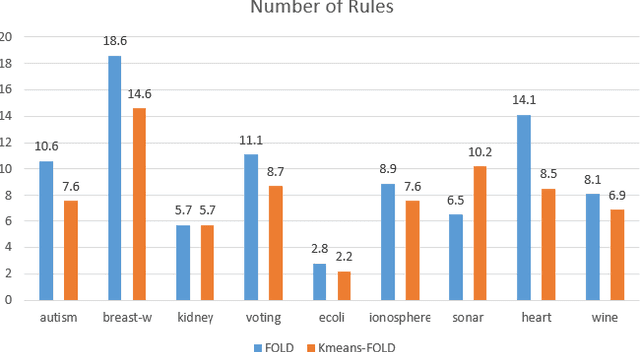
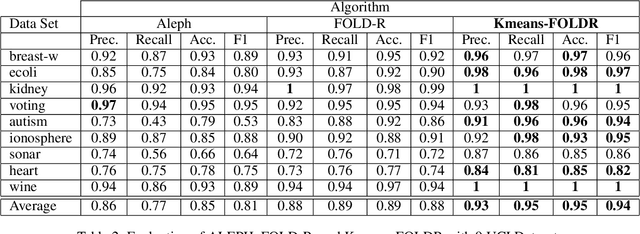
We present a clustering- and demotion-based algorithm called Kmeans-FOLD to induce nonmonotonic logic programs from positive and negative examples. Our algorithm improves upon-and is inspired by-the FOLD algorithm. The FOLD algorithm itself is an improvement over the FOIL algorithm. Our algorithm generates a more concise logic program compared to the FOLD algorithm. Our algorithm uses the K-means based clustering method to cluster the input positive samples before applying the FOLD algorithm. Positive examples that are covered by the partially learned program in intermediate steps are not discarded as in the FOLD algorithm, rather they are demoted, i.e., their weights are reduced in subsequent iterations of the algorithm. Our experiments on the UCI dataset show that a combination of K-Means clustering and our demotion strategy produces significant improvement for datasets with more than one cluster of positive examples. The resulting induced program is also more concise and therefore easier to understand compared to the FOLD and ALEPH systems, two state of the art inductive logic programming (ILP) systems.
Generating Concurrent Programs From Sequential Data Structure Knowledge Using Answer Set Programming
Sep 17, 2021


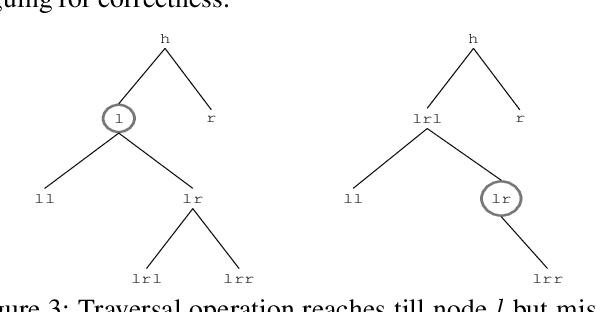
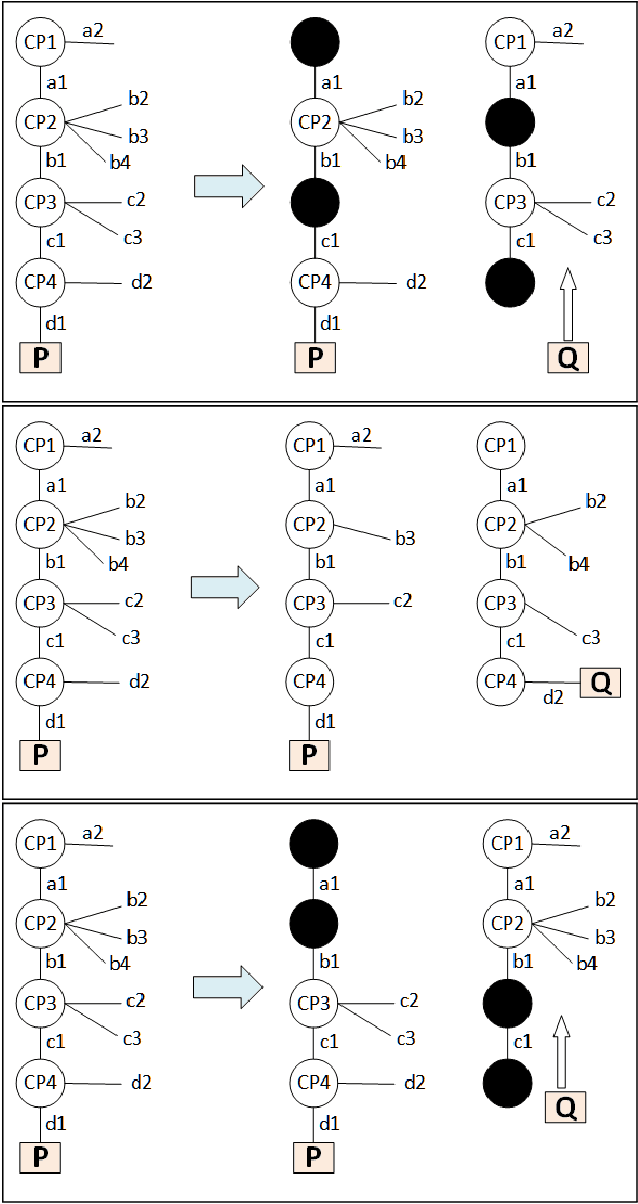
We tackle the problem of automatically designing concurrent data structure operations given a sequential data structure specification and knowledge about concurrent behavior. Designing concurrent code is a non-trivial task even in simplest of cases. Humans often design concurrent data structure operations by transforming sequential versions into their respective concurrent versions. This requires an understanding of the data structure, its sequential behavior, thread interactions during concurrent execution and shared memory synchronization primitives. We mechanize this design process using automated commonsense reasoning. We assume that the data structure description is provided as axioms alongside the sequential code of its algebraic operations. This information is used to automatically derive concurrent code for that data structure, such as dictionary operations for linked lists and binary search trees. Knowledge in our case is expressed using Answer Set Programming (ASP), and we employ deduction and abduction -- just as humans do -- in the reasoning involved. ASP allows for succinct modeling of first order theories of pointer data structures, run-time thread interactions and shared memory synchronization. Our reasoner can systematically make the same judgments as a human reasoner, while constructing provably safe concurrent code. We present several reasoning challenges involved in transforming the sequential data structure into its equivalent concurrent version. All the reasoning tasks are encoded in ASP and our reasoner can make sound judgments to transform sequential code into concurrent code. To the best of our knowledge, our work is the first one to use commonsense reasoning to automatically transform sequential programs into concurrent code. We also have developed a tool that we describe that relies on state-of-the-art ASP solvers and performs the reasoning tasks involved to generate concurrent code.
* In Proceedings ICLP 2021, arXiv:2109.07914. arXiv admin note: substantial text overlap with arXiv:2011.04045