 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Concept Representation for Text-to-image Person Re-identification
Jan 15, 2026Text-to-image person re-identification (TIReID) aims to retrieve person images from a large gallery given free-form textual descriptions. TIReID is challenging due to the substantial modality gap between visual appearances and textual expressions, as well as the need to model fine-grained correspondences that distinguish individuals with similar attributes such as clothing color, texture, or outfit style. To address these issues, we propose DiCo (Disentangled Concept Representation), a novel framework that achieves hierarchical and disentangled cross-modal alignment. DiCo introduces a shared slot-based representation, where each slot acts as a part-level anchor across modalities and is further decomposed into multiple concept blocks. This design enables the disentanglement of complementary attributes (\textit{e.g.}, color, texture, shape) while maintaining consistent part-level correspondence between image and text. Extensive experiments on CUHK-PEDES, ICFG-PEDES, and RSTPReid demonstrate that our framework achieves competitive performance with state-of-the-art methods, while also enhancing interpretability through explicit slot- and block-level representations for more fine-grained retrieval results.
Leveraging Prior Knowledge of Diffusion Model for Person Search
Oct 02, 2025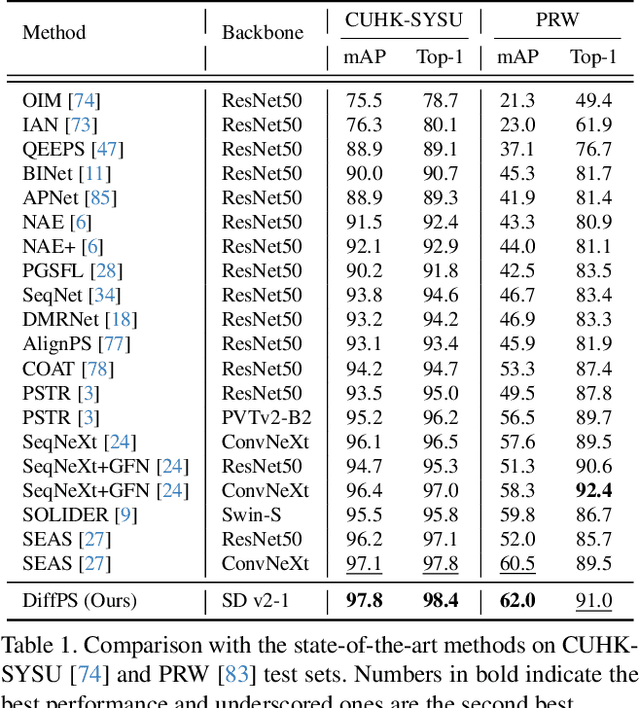
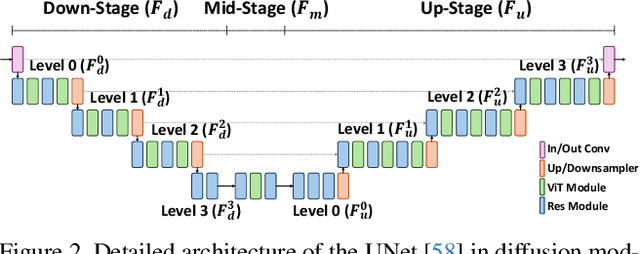
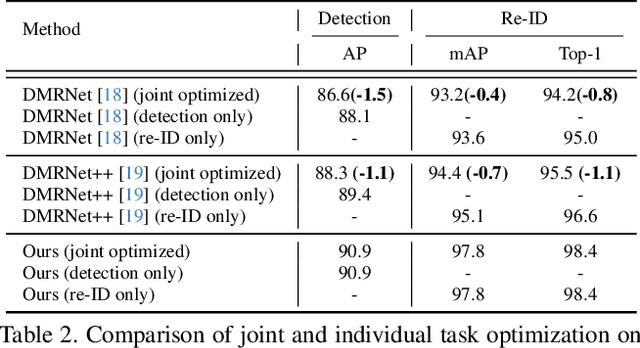

Person search aims to jointly perform person detection and re-identification by localizing and identifying a query person within a gallery of uncropped scene images. Existing methods predominantly utilize ImageNet pre-trained backbones, which may be suboptimal for capturing the complex spatial context and fine-grained identity cues necessary for person search. Moreover, they rely on a shared backbone feature for both person detection and re-identification, leading to suboptimal features due to conflicting optimization objectives. In this paper, we propose DiffPS (Diffusion Prior Knowledge for Person Search), a novel framework that leverages a pre-trained diffusion model while eliminating the optimization conflict between two sub-tasks. We analyze key properties of diffusion priors and propose three specialized modules: (i) Diffusion-Guided Region Proposal Network (DGRPN) for enhanced person localization, (ii) Multi-Scale Frequency Refinement Network (MSFRN) to mitigate shape bias, and (iii) Semantic-Adaptive Feature Aggregation Network (SFAN) to leverage text-aligned diffusion features. DiffPS sets a new state-of-the-art on CUHK-SYSU and PRW.