 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Reinforcement Learning Benchmarks with Random Weight Guessing
Apr 16, 2020
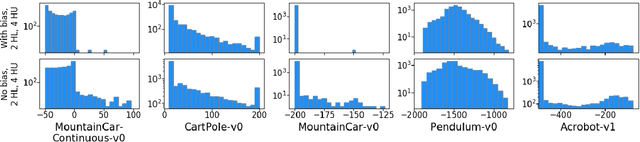
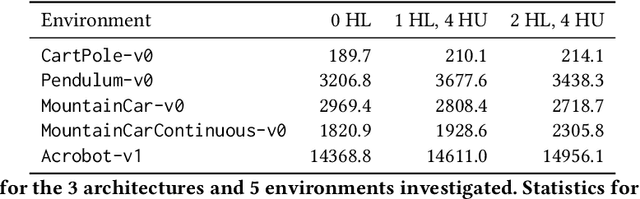
We propose a novel method for analyzing and visualizing the complexity of standard reinforcement learning (RL) benchmarks based on score distributions. A large number of policy networks are generated by randomly guessing their parameters, and then evaluated on the benchmark task; the study of their aggregated results provide insights into the benchmark complexity. Our method guarantees objectivity of evaluation by sidestepping learning altogether: the policy network parameters are generated using Random Weight Guessing (RWG), making our method agnostic to (i) the classic RL setup, (ii) any learning algorithm, and (iii) hyperparameter tuning. We show that this approach isolates the environment complexity, highlights specific types of challenges, and provides a proper foundation for the statistical analysis of the task's difficulty. We test our approach on a variety of classic control benchmarks from the OpenAI Gym, where we show that small untrained networks can provide a robust baseline for a variety of tasks. The networks generated often show good performance even without gradual learning, incidentally highlighting the triviality of a few popular benchmarks.
Playing Atari with Six Neurons
Jun 04, 2018
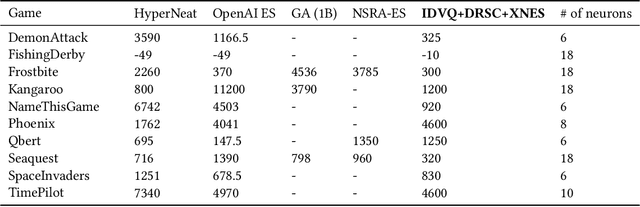

Deep reinforcement learning on Atari games maps pixel directly to actions; internally, the deep neural network bears the responsibility of both extracting useful information and making decisions based on it. Aiming at devoting entire deep networks to decision making alone, we propose a new method for learning policies and compact state representations separately but simultaneously for policy approximation in reinforcement learning. State representations are generated by a novel algorithm based on Vector Quantization and Sparse Coding, trained online along with the network, and capable of growing its dictionary size over time. We also introduce new techniques allowing both the neural network and the evolution strategy to cope with varying dimensions. This enables networks of only 6 to 18 neurons to learn to play a selection of Atari games with performance comparable---and occasionally superior---to state-of-the-art techniques using evolution strategies on deep networks two orders of magnitude larger.