 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking
May 02, 2020

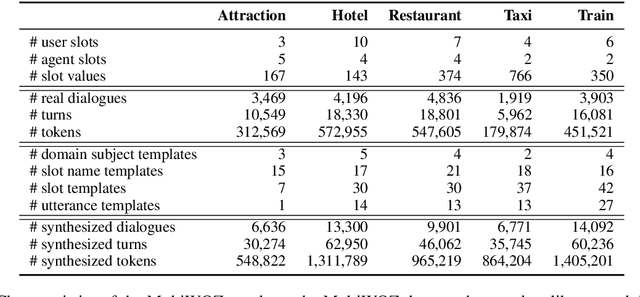
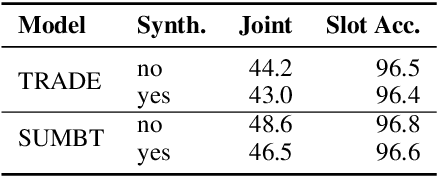
Zero-shot transfer learning for multi-domain dialogue state tracking can allow us to handle new domains without incurring the high cost of data acquisition. This paper proposes new zero-short transfer learning technique for dialogue state tracking where the in-domain training data are all synthesized from an abstract dialogue model and the ontology of the domain. We show that data augmentation through synthesized data can improve the accuracy of zero-shot learning for both the TRADE model and the BERT-based SUMBT model on the MultiWOZ 2.1 dataset. We show training with only synthesized in-domain data on the SUMBT model can reach about 2/3 of the accuracy obtained with the full training dataset. We improve the zero-shot learning state of the art on average across domains by 21%.
Schema2QA: Answering Complex Queries on the Structured Web with a Neural Model
Jan 27, 2020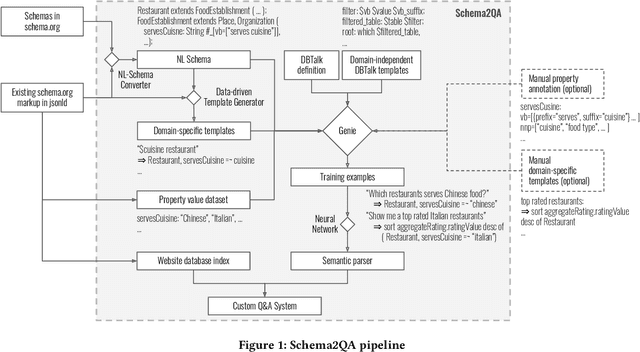


Virtual assistants have proprietary third-party skill platforms; they train and own the voice interface to websites based on their submitted skill information. This paper proposes Schema2QA, an open-source toolkit that leverages the Schema.org markup found in many websites to automatically build skills. Schema2QA has several advantages: (1) Schema2QA is more accurate than commercial assistants in answering compositional queries involving multiple properties; (2) it has a low-cost training data acquisition methodology that requires only writing a small number of annotations per domain and paraphrasing a small number of sentences. Schema2QA uses a novel neural model that combines the BERT pretrained model with an LSTM; the model can generalize a training set containing only synthesized and paraphrase data to understand real-world crowdsourced questions. We apply Schema2QA to two different domains, showing that the skills we built can answer useful queries with little manual effort. Our skills achieve an overall accuracy between 73% and 81%. With transfer learning, we show that a new domain can achieve a 59% accuracy without manual effort. The open-source Schema2QA lets each website create and own its linguistic interface.
Genie: A Generator of Natural Language Semantic Parsers for Virtual Assistant Commands
Apr 18, 2019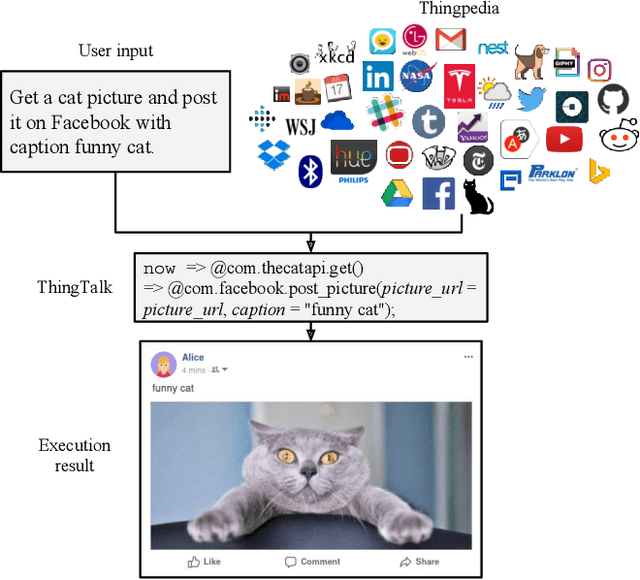
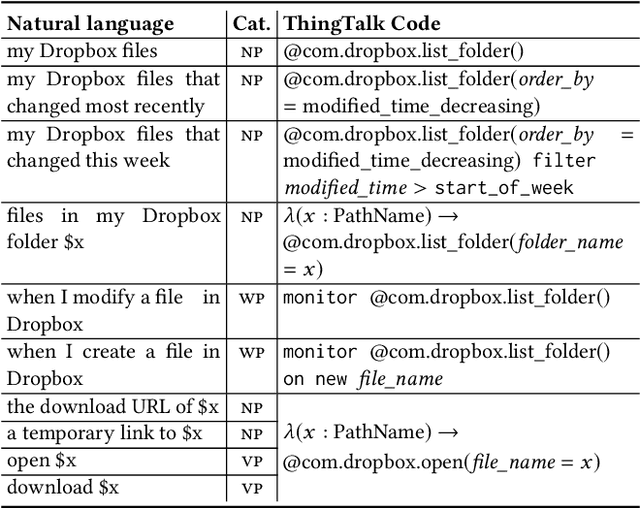
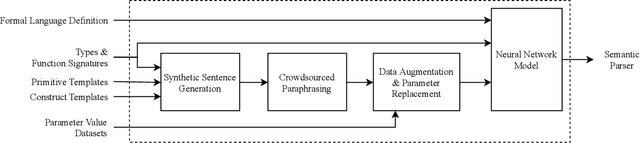

To understand diverse natural language commands, virtual assistants today are trained with numerous labor-intensive, manually annotated sentences. This paper presents a methodology and the Genie toolkit that can handle new compound commands with significantly less manual effort. We advocate formalizing the capability of virtual assistants with a Virtual Assistant Programming Language (VAPL) and using a neural semantic parser to translate natural language into VAPL code. Genie needs only a small realistic set of input sentences for validating the neural model. Developers write templates to synthesize data; Genie uses crowdsourced paraphrases and data augmentation, along with the synthesized data, to train a semantic parser. We also propose design principles that make VAPL languages amenable to natural language translation. We apply these principles to revise ThingTalk, the language used by the Almond virtual assistant. We use Genie to build the first semantic parser that can support compound virtual assistants commands with unquoted free-form parameters. Genie achieves a 62% accuracy on realistic user inputs. We demonstrate Genie's generality by showing a 19% and 31% improvement over the previous state of the art on a music skill, aggregate functions, and access control.