 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Ocean Subgrid-Scale Parameterizations Using Fourier Neural Operators
Oct 04, 2023

In climate simulations, small-scale processes shape ocean dynamics but remain computationally expensive to resolve directly. For this reason, their contributions are commonly approximated using empirical parameterizations, which lead to significant errors in long-term projections. In this work, we develop parameterizations based on Fourier Neural Operators, showcasing their accuracy and generalizability in comparison to other approaches. Finally, we discuss the potential and limitations of neural networks operating in the frequency domain, paving the way for future investigation.
Score-based Data Assimilation for a Two-Layer Quasi-Geostrophic Model
Oct 03, 2023



Data assimilation addresses the problem of identifying plausible state trajectories of dynamical systems given noisy or incomplete observations. In geosciences, it presents challenges due to the high-dimensionality of geophysical dynamical systems, often exceeding millions of dimensions. This work assesses the scalability of score-based data assimilation (SDA), a novel data assimilation method, in the context of such systems. We propose modifications to the score network architecture aimed at significantly reducing memory consumption and execution time. We demonstrate promising results for a two-layer quasi-geostrophic model.
Dynamic NeRFs for Soccer Scenes
Sep 13, 2023The long-standing problem of novel view synthesis has many applications, notably in sports broadcasting. Photorealistic novel view synthesis of soccer actions, in particular, is of enormous interest to the broadcast industry. Yet only a few industrial solutions have been proposed, and even fewer that achieve near-broadcast quality of the synthetic replays. Except for their setup of multiple static cameras around the playfield, the best proprietary systems disclose close to no information about their inner workings. Leveraging multiple static cameras for such a task indeed presents a challenge rarely tackled in the literature, for a lack of public datasets: the reconstruction of a large-scale, mostly static environment, with small, fast-moving elements. Recently, the emergence of neural radiance fields has induced stunning progress in many novel view synthesis applications, leveraging deep learning principles to produce photorealistic results in the most challenging settings. In this work, we investigate the feasibility of basing a solution to the task on dynamic NeRFs, i.e., neural models purposed to reconstruct general dynamic content. We compose synthetic soccer environments and conduct multiple experiments using them, identifying key components that help reconstruct soccer scenes with dynamic NeRFs. We show that, although this approach cannot fully meet the quality requirements for the target application, it suggests promising avenues toward a cost-efficient, automatic solution. We also make our work dataset and code publicly available, with the goal to encourage further efforts from the research community on the task of novel view synthesis for dynamic soccer scenes. For code, data, and video results, please see https://soccernerfs.isach.be.
Score-based Data Assimilation
Jun 18, 2023



Data assimilation, in its most comprehensive form, addresses the Bayesian inverse problem of identifying plausible state trajectories that explain noisy or incomplete observations of stochastic dynamical systems. Various approaches have been proposed to solve this problem, including particle-based and variational methods. However, most algorithms depend on the transition dynamics for inference, which becomes intractable for long time horizons or for high-dimensional systems with complex dynamics, such as oceans or atmospheres. In this work, we introduce score-based data assimilation for trajectory inference. We learn a score-based generative model of state trajectories based on the key insight that the score of an arbitrarily long trajectory can be decomposed into a series of scores over short segments. After training, inference is carried out using the score model, in a non-autoregressive manner by generating all states simultaneously. Quite distinctively, we decouple the observation model from the training procedure and use it only at inference to guide the generative process, which enables a wide range of zero-shot observation scenarios. We present theoretical and empirical evidence supporting the effectiveness of our method.
Policy Gradient Algorithms Implicitly Optimize by Continuation
May 11, 2023Direct policy optimization in reinforcement learning is usually solved with policy-gradient algorithms, which optimize policy parameters via stochastic gradient ascent. This paper provides a new theoretical interpretation and justification of these algorithms. First, we formulate direct policy optimization in the optimization by continuation framework. The latter is a framework for optimizing nonconvex functions where a sequence of surrogate objective functions, called continuations, are locally optimized. Second, we show that optimizing affine Gaussian policies and performing entropy regularization can be interpreted as implicitly optimizing deterministic policies by continuation. Based on these theoretical results, we argue that exploration in policy-gradient algorithms consists in computing a continuation of the return of the policy at hand, and that the variance of policies should be history-dependent functions adapted to avoid local extrema rather than to maximize the return of the policy.
Balancing Simulation-based Inference for Conservative Posteriors
Apr 21, 2023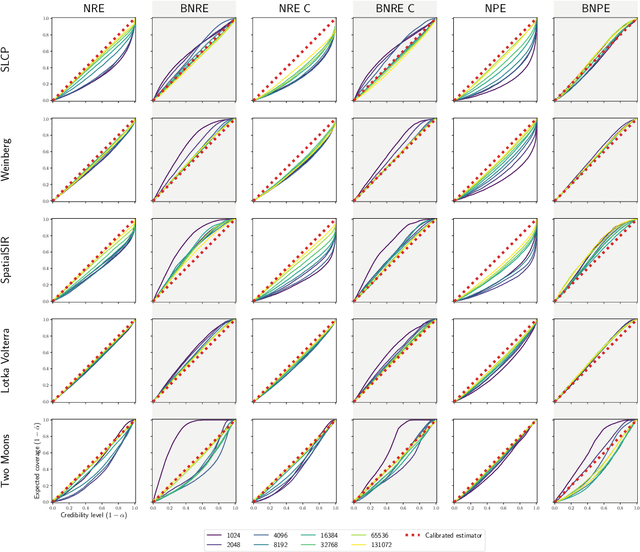
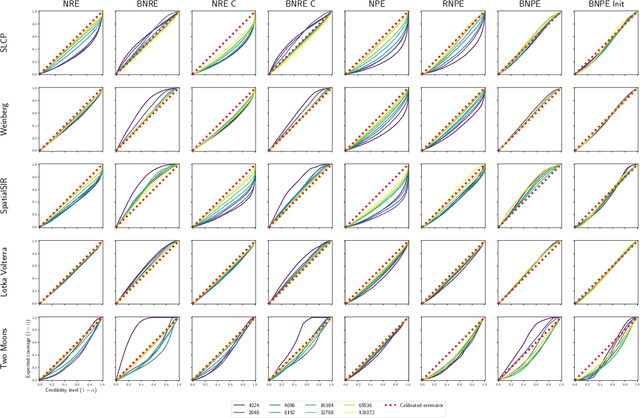
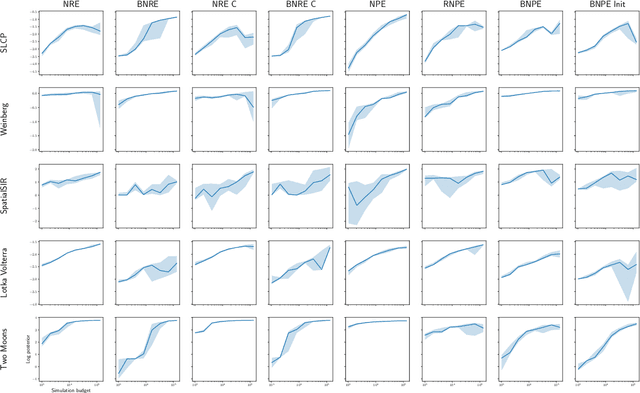
Conservative inference is a major concern in simulation-based inference. It has been shown that commonly used algorithms can produce overconfident posterior approximations. Balancing has empirically proven to be an effective way to mitigate this issue. However, its application remains limited to neural ratio estimation. In this work, we extend balancing to any algorithm that provides a posterior density. In particular, we introduce a balanced version of both neural posterior estimation and contrastive neural ratio estimation. We show empirically that the balanced versions tend to produce conservative posterior approximations on a wide variety of benchmarks. In addition, we provide an alternative interpretation of the balancing condition in terms of the $\chi^2$ divergence.
Implicit representation priors meet Riemannian geometry for Bayesian robotic grasping
Apr 19, 2023Robotic grasping in highly noisy environments presents complex challenges, especially with limited prior knowledge about the scene. In particular, identifying good grasping poses with Bayesian inference becomes difficult due to two reasons: i) generating data from uninformative priors proves to be inefficient, and ii) the posterior often entails a complex distribution defined on a Riemannian manifold. In this study, we explore the use of implicit representations to construct scene-dependent priors, thereby enabling the application of efficient simulation-based Bayesian inference algorithms for determining successful grasp poses in unstructured environments. Results from both simulation and physical benchmarks showcase the high success rate and promising potential of this approach.
Graph-informed simulation-based inference for models of active matter
Apr 05, 2023



Many collective systems exist in nature far from equilibrium, ranging from cellular sheets up to flocks of birds. These systems reflect a form of active matter, whereby individual material components have internal energy. Under specific parameter regimes, these active systems undergo phase transitions whereby small fluctuations of single components can lead to global changes to the rheology of the system. Simulations and methods from statistical physics are typically used to understand and predict these phase transitions for real-world observations. In this work, we demonstrate that simulation-based inference can be used to robustly infer active matter parameters from system observations. Moreover, we demonstrate that a small number (from one to three) snapshots of the system can be used for parameter inference and that this graph-informed approach outperforms typical metrics such as the average velocity or mean square displacement of the system. Our work highlights that high-level system information is contained within the relational structure of a collective system and that this can be exploited to better couple models to data.
Simulation-based Bayesian inference for robotic grasping
Mar 10, 2023



General robotic grippers are challenging to control because of their rich nonsmooth contact dynamics and the many sources of uncertainties due to the environment or sensor noise. In this work, we demonstrate how to compute 6-DoF grasp poses using simulation-based Bayesian inference through the full stochastic forward simulation of the robot in its environment while robustly accounting for many of the uncertainties in the system. A Riemannian manifold optimization procedure preserving the nonlinearity of the rotation space is used to compute the maximum a posteriori grasp pose. Simulation and physical benchmarks show the promising high success rate of the approach.
Adaptive Self-Training for Object Detection
Dec 07, 2022



Deep learning has emerged as an effective solution for solving the task of object detection in images but at the cost of requiring large labeled datasets. To mitigate this cost, semi-supervised object detection methods, which consist in leveraging abundant unlabeled data, have been proposed and have already shown impressive results. However, most of these methods require linking a pseudo-label to a ground-truth object by thresholding. In previous works, this threshold value is usually determined empirically, which is time consuming, and only done for a single data distribution. When the domain, and thus the data distribution, changes, a new and costly parameter search is necessary. In this work, we introduce our method Adaptive Self-Training for Object Detection (ASTOD), which is a simple yet effective teacher-student method. ASTOD determines without cost a threshold value based directly on the ground value of the score histogram. To improve the quality of the teacher predictions, we also propose a novel pseudo-labeling procedure. We use different views of the unlabeled images during the pseudo-labeling step to reduce the number of missed predictions and thus obtain better candidate labels. Our teacher and our student are trained separately, and our method can be used in an iterative fashion by replacing the teacher by the student. On the MS-COCO dataset, our method consistently performs favorably against state-of-the-art methods that do not require a threshold parameter, and shows competitive results with methods that require a parameter sweep search. Additional experiments with respect to a supervised baseline on the DIOR dataset containing satellite images lead to similar conclusions, and prove that it is possible to adapt the score threshold automatically in self-training, regardless of the data distribution.