 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwap-guided Preference Learning for Personalized Reinforcement Learning from Human Feedback
Mar 13, 2026Reinforcement Learning from Human Feedback (RLHF) is a widely used approach to align large-scale AI systems with human values. However, RLHF typically assumes a single, universal reward, which overlooks diverse preferences and limits personalization. Variational Preference Learning (VPL) seeks to address this by introducing user-specific latent variables. Despite its promise, we found that VPL suffers from posterior collapse. While this phenomenon is well known in VAEs, it has not previously been identified in preference learning frameworks. Under sparse preference data and with overly expressive decoders, VPL may cause latent variables to be ignored, reverting to a single-reward model. To overcome this limitation, we propose Swap-guided Preference Learning (SPL). The key idea is to construct fictitious swap annotators and use the mirroring property of their preferences to guide the encoder. SPL introduces three components: (1) swap-guided base regularization, (2) Preferential Inverse Autoregressive Flow (P-IAF), and (3) adaptive latent conditioning. Experiments show that SPL mitigates collapse, enriches user-specific latents, and improves preference prediction. Our code and data are available at https://github.com/cobang0111/SPL
Regularized Personalization of Text-to-Image Diffusion Models without Distributional Drift
May 26, 2025



Personalization using text-to-image diffusion models involves adapting a pretrained model to novel subjects with only a few image examples. This task presents a fundamental challenge, as the model must not only learn the new subject effectively but also preserve its ability to generate diverse and coherent outputs across a wide range of prompts. In other words, successful personalization requires integrating new concepts without forgetting previously learned generative capabilities. Forgetting denotes unintended distributional drift, where the model's output distribution deviates from that of the original pretrained model. In this paper, we provide an analysis of this issue and identify a mismatch between standard training objectives and the goals of personalization. To address this, we propose a new training objective based on a Lipschitz-bounded formulation that explicitly constrains deviation from the pretrained distribution. Our method provides improved control over distributional drift and performs well even in data-scarce scenarios. Experimental results demonstrate that our approach consistently outperforms existing personalization methods, achieving higher CLIP-T, CLIP-I, and DINO scores.
NeRFFaceSpeech: One-shot Audio-driven 3D Talking Head Synthesis via Generative Prior
May 10, 2024



Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
Multi-Head Attention based Probabilistic Vehicle Trajectory Prediction
Apr 20, 2020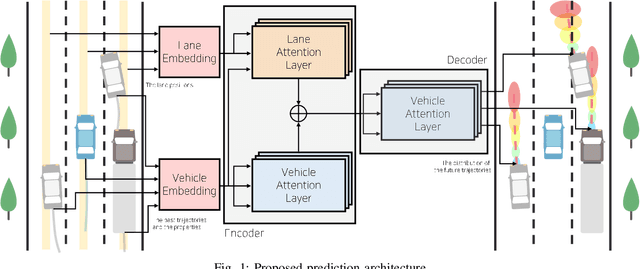
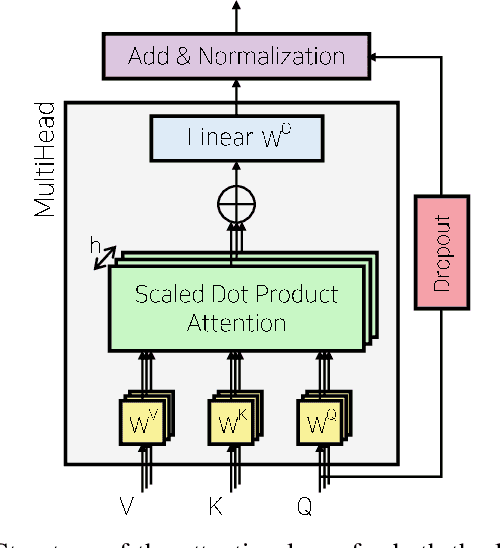

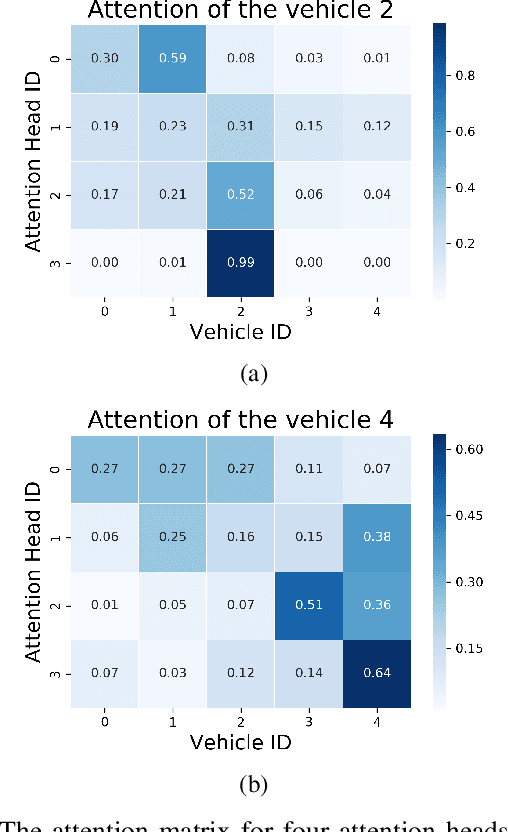
This paper presents online-capable deep learning model for probabilistic vehicle trajectory prediction. We propose a simple encoder-decoder architecture based on multi-head attention. The proposed model generates the distribution of the predicted trajectories for multiple vehicles in parallel. Our approach to model the interactions can learn to attend to a few influential vehicles in an unsupervised manner, which can improve the interpretability of the network. The experiments using naturalistic trajectories at highway show the clear improvement in terms of positional error on both longitudinal and lateral direction.