 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical term normalization of EHRs with UMLS
May 24, 2018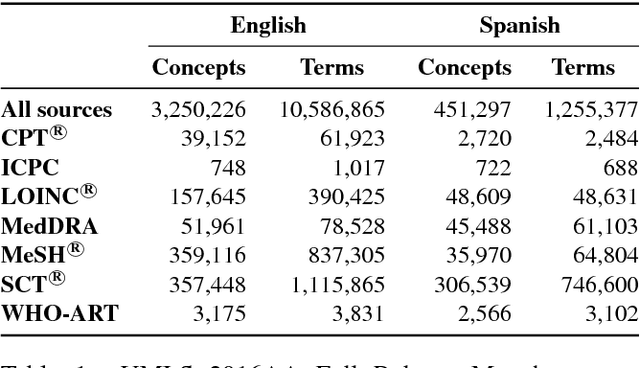
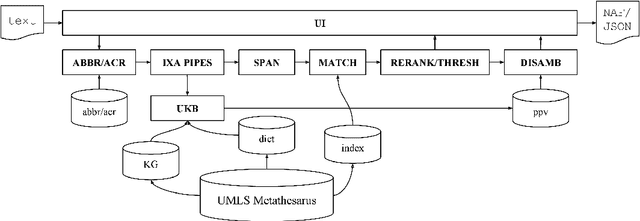
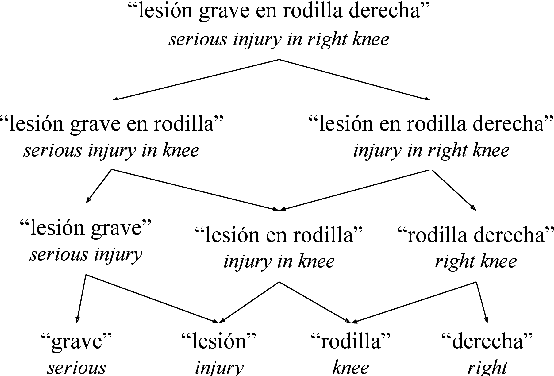
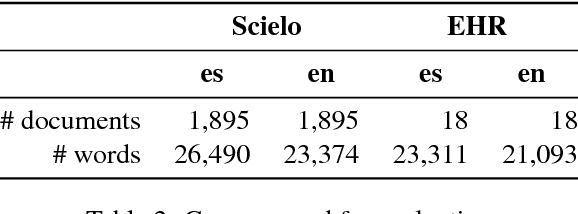
This paper presents a novel prototype for biomedical term normalization of electronic health record excerpts with the Unified Medical Language System (UMLS) Metathesaurus. Despite being multilingual and cross-lingual by design, we first focus on processing clinical text in Spanish because there is no existing tool for this language and for this specific purpose. The tool is based on Apache Lucene to index the Metathesaurus and generate mapping candidates from input text. It uses the IXA pipeline for basic language processing and resolves ambiguities with the UKB toolkit. It has been evaluated by measuring its agreement with MetaMap in two English-Spanish parallel corpora. In addition, we present a web-based interface for the tool.
Validating WordNet Meronymy Relations using Adimen-SUMO
May 20, 2018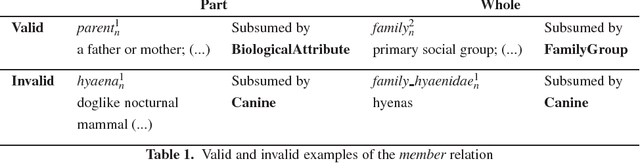



In this paper, we report on the practical application of a novel approach for validating the knowledge of WordNet using Adimen-SUMO. In particular, this paper focuses on cross-checking the WordNet meronymy relations against the knowledge encoded in Adimen-SUMO. Our validation approach tests a large set of competency questions (CQs), which are derived (semi)-automatically from the knowledge encoded in WordNet, SUMO and their mapping, by applying efficient first-order logic automated theorem provers. Unfortunately, despite of being created manually, these knowledge resources are not free of errors and discrepancies. In consequence, some of the resulting CQs are not plausible according to the knowledge included in Adimen-SUMO. Thus, first we focus on (semi)-automatically improving the alignment between these knowledge resources, and second, we perform a minimal set of corrections in the ontology. Our aim is to minimize the manual effort required for an extensive validation process. We report on the strategies followed, the changes made, the effort needed and its impact when validating the WordNet meronymy relations using improved versions of the mapping and the ontology. Based on the new results, we discuss the implications of the appropriate corrections and the need of future enhancements.
Black-box Testing of First-Order Logic Ontologies Using WordNet
Mar 23, 2018

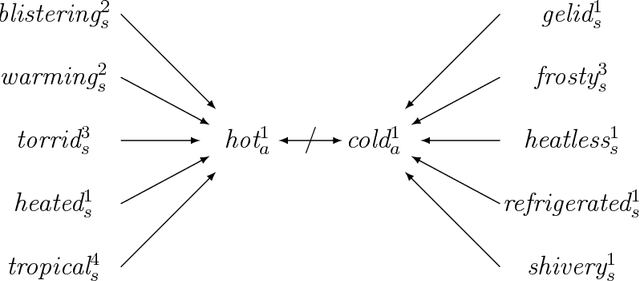
Artificial Intelligence aims to provide computer programs with commonsense knowledge to reason about our world. This paper offers a new practical approach towards automated commonsense reasoning with first-order logic (FOL) ontologies. We propose a new black-box testing methodology of FOL SUMO-based ontologies by exploiting WordNet and its mapping into SUMO. Our proposal includes a method for the (semi-)automatic creation of a very large benchmark of competency questions and a procedure for its automated evaluation by using automated theorem provers (ATPs). Applying different quality criteria, our testing proposal enables a successful evaluation of a) the competency of several translations of SUMO into FOL and b) the performance of various automated ATPs. Finally, we also provide a fine-grained and complete analysis of the commonsense reasoning competency of current FOL SUMO-based ontologies.
W2VLDA: Almost Unsupervised System for Aspect Based Sentiment Analysis
Jul 18, 2017
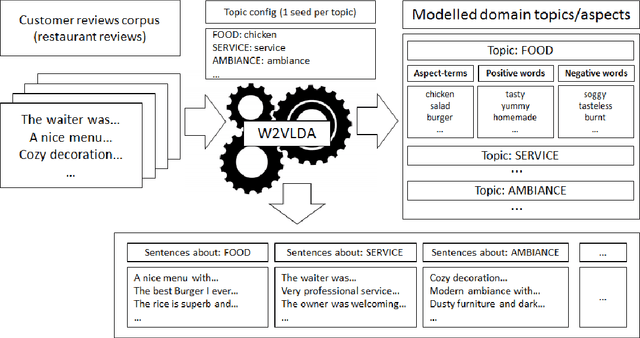
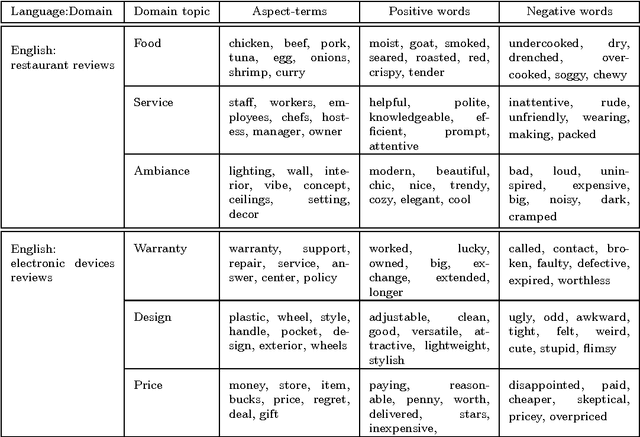
With the increase of online customer opinions in specialised websites and social networks, the necessity of automatic systems to help to organise and classify customer reviews by domain-specific aspect/categories and sentiment polarity is more important than ever. Supervised approaches to Aspect Based Sentiment Analysis obtain good results for the domain/language their are trained on, but having manually labelled data for training supervised systems for all domains and languages are usually very costly and time consuming. In this work we describe W2VLDA, an almost unsupervised system based on topic modelling, that combined with some other unsupervised methods and a minimal configuration, performs aspect/category classifiation, aspect-terms/opinion-words separation and sentiment polarity classification for any given domain and language. We evaluate the performance of the aspect and sentiment classification in the multilingual SemEval 2016 task 5 (ABSA) dataset. We show competitive results for several languages (English, Spanish, French and Dutch) and domains (hotels, restaurants, electronic-devices).
Q-WordNet PPV: Simple, Robust and Unsupervised Generation of Polarity Lexicons for Multiple Languages
Feb 06, 2017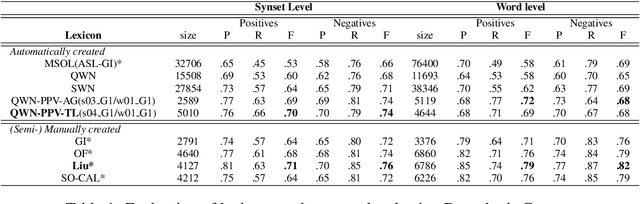
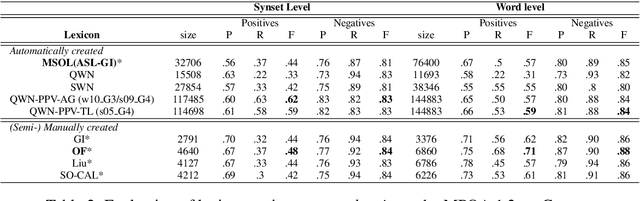
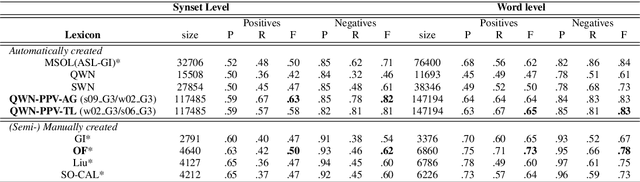
This paper presents a simple, robust and (almost) unsupervised dictionary-based method, qwn-ppv (Q-WordNet as Personalized PageRanking Vector) to automatically generate polarity lexicons. We show that qwn-ppv outperforms other automatically generated lexicons for the four extrinsic evaluations presented here. It also shows very competitive and robust results with respect to manually annotated ones. Results suggest that no single lexicon is best for every task and dataset and that the intrinsic evaluation of polarity lexicons is not a good performance indicator on a Sentiment Analysis task. The qwn-ppv method allows to easily create quality polarity lexicons whenever no domain-based annotated corpora are available for a given language.
* 8 pages plus 2 pages of references
Multilingual and Cross-lingual Timeline Extraction
Feb 02, 2017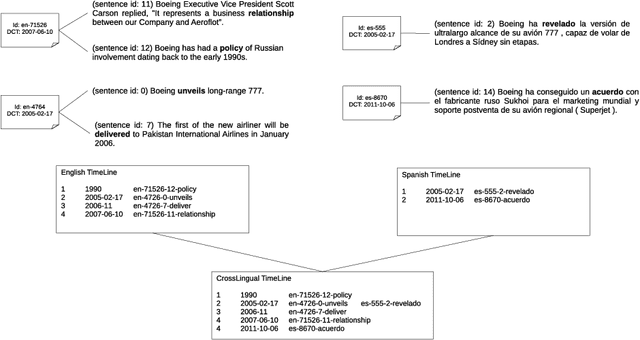
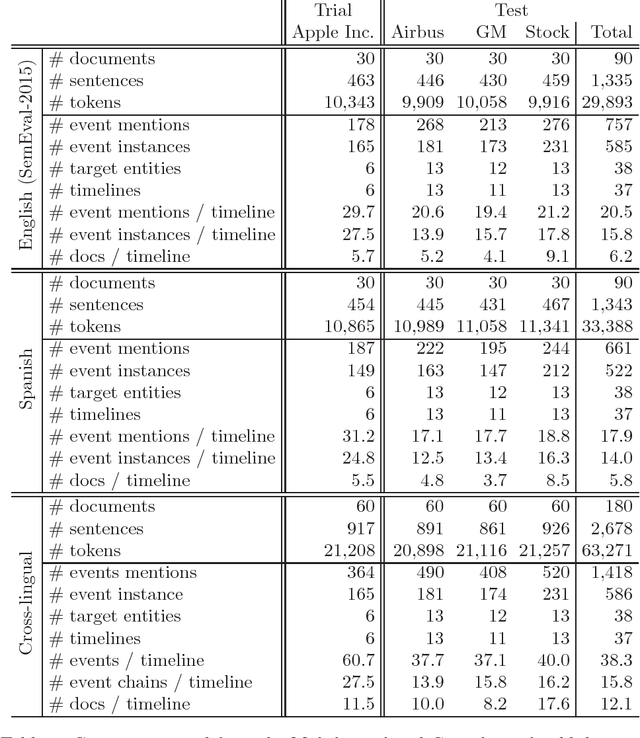
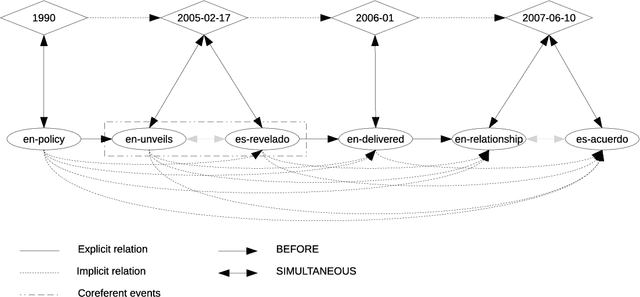
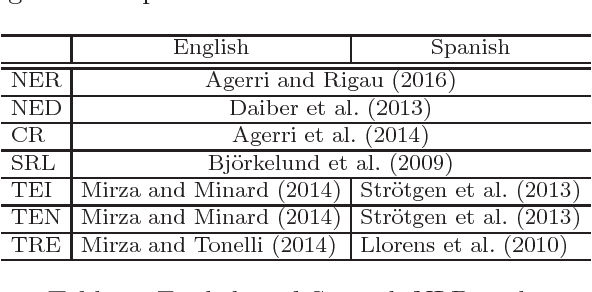
In this paper we present an approach to extract ordered timelines of events, their participants, locations and times from a set of multilingual and cross-lingual data sources. Based on the assumption that event-related information can be recovered from different documents written in different languages, we extend the Cross-document Event Ordering task presented at SemEval 2015 by specifying two new tasks for, respectively, Multilingual and Cross-lingual Timeline Extraction. We then develop three deterministic algorithms for timeline extraction based on two main ideas. First, we address implicit temporal relations at document level since explicit time-anchors are too scarce to build a wide coverage timeline extraction system. Second, we leverage several multilingual resources to obtain a single, inter-operable, semantic representation of events across documents and across languages. The result is a highly competitive system that strongly outperforms the current state-of-the-art. Nonetheless, further analysis of the results reveals that linking the event mentions with their target entities and time-anchors remains a difficult challenge. The systems, resources and scorers are freely available to facilitate its use and guarantee the reproducibility of results.
Robust Multilingual Named Entity Recognition with Shallow Semi-Supervised Features
Jan 31, 2017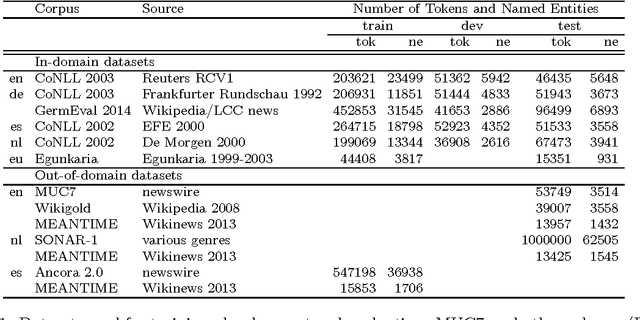
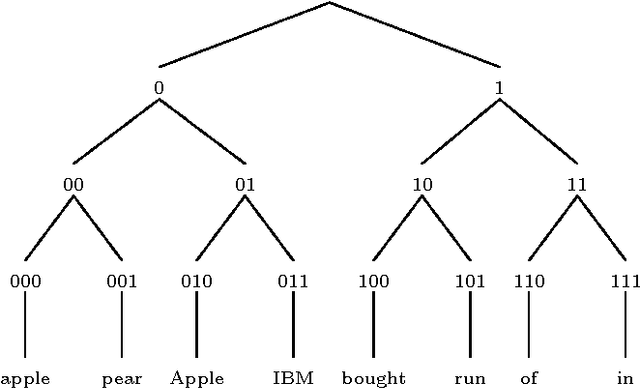

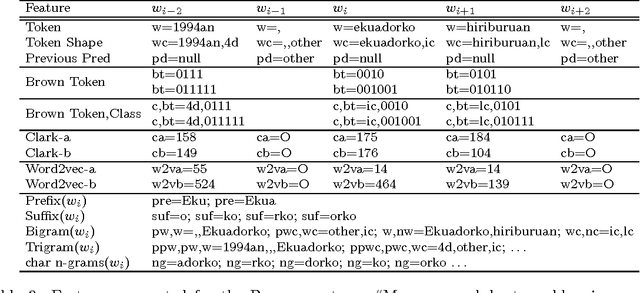
We present a multilingual Named Entity Recognition approach based on a robust and general set of features across languages and datasets. Our system combines shallow local information with clustering semi-supervised features induced on large amounts of unlabeled text. Understanding via empirical experimentation how to effectively combine various types of clustering features allows us to seamlessly export our system to other datasets and languages. The result is a simple but highly competitive system which obtains state of the art results across five languages and twelve datasets. The results are reported on standard shared task evaluation data such as CoNLL for English, Spanish and Dutch. Furthermore, and despite the lack of linguistically motivated features, we also report best results for languages such as Basque and German. In addition, we demonstrate that our method also obtains very competitive results even when the amount of supervised data is cut by half, alleviating the dependency on manually annotated data. Finally, the results show that our emphasis on clustering features is crucial to develop robust out-of-domain models. The system and models are freely available to facilitate its use and guarantee the reproducibility of results.
* 26 pages, 19 tables (submitted for publication on September 2015), Artificial Intelligence (2016)
Evaluating the Competency of a First-Order Ontology
Oct 16, 2015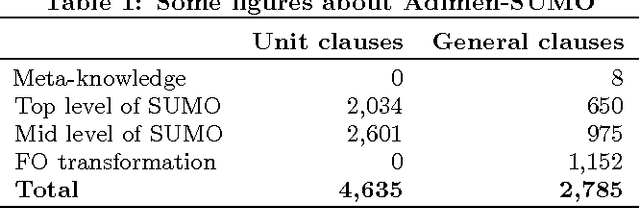
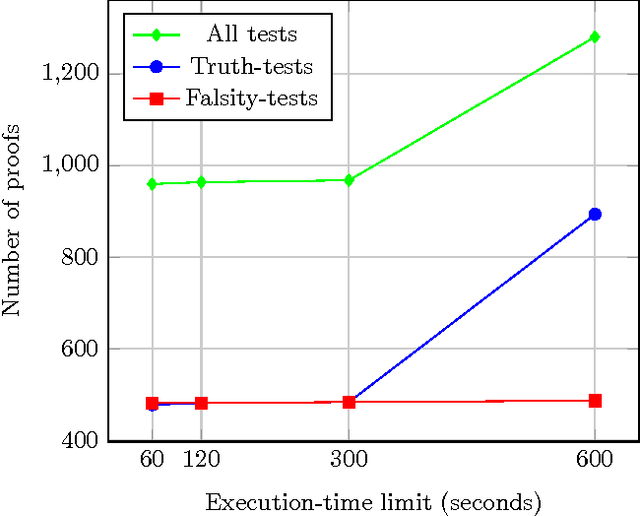
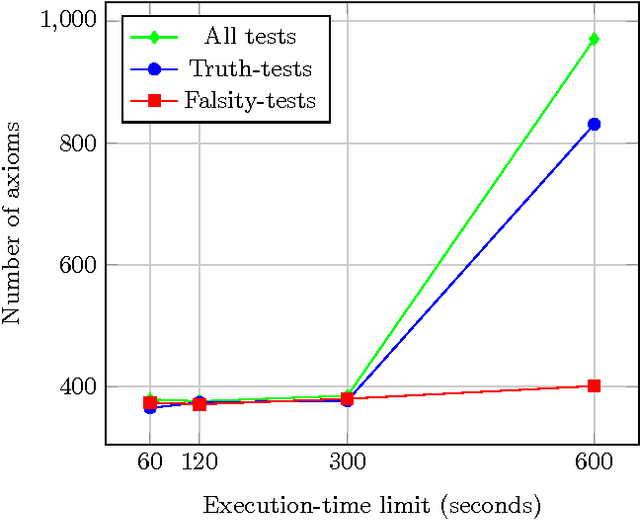
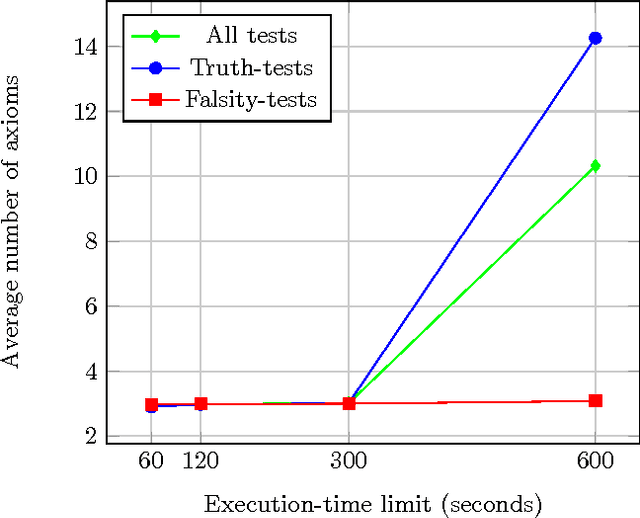
We report on the results of evaluating the competency of a first-order ontology for its use with automated theorem provers (ATPs). The evaluation follows the adaptation of the methodology based on competency questions (CQs) [Gr\"uninger&Fox,1995] to the framework of first-order logic, which is presented in [\'Alvez&Lucio&Rigau,2015], and is applied to Adimen-SUMO [\'Alvez&Lucio&Rigau,2015]. The set of CQs used for this evaluation has been automatically generated from a small set of semantic patterns and the mapping of WordNet to SUMO. Analysing the results, we can conclude that it is feasible to use ATPs for working with Adimen-SUMO v2.4, enabling the resolution of goals by means of performing non-trivial inferences.
* 4 pages, 4 figures
Improving the Competency of First-Order Ontologies
Oct 16, 2015
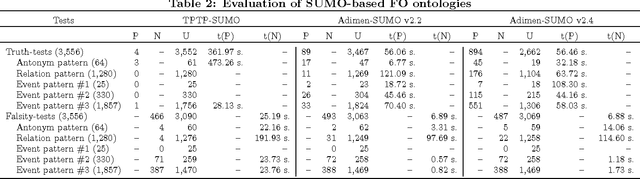
We introduce a new framework to evaluate and improve first-order (FO) ontologies using automated theorem provers (ATPs) on the basis of competency questions (CQs). Our framework includes both the adaptation of a methodology for evaluating ontologies to the framework of first-order logic and a new set of non-trivial CQs designed to evaluate FO versions of SUMO, which significantly extends the very small set of CQs proposed in the literature. Most of these new CQs have been automatically generated from a small set of patterns and the mapping of WordNet to SUMO. Applying our framework, we demonstrate that Adimen-SUMO v2.2 outperforms TPTP-SUMO. In addition, using the feedback provided by ATPs we have set an improved version of Adimen-SUMO (v2.4). This new version outperforms the previous ones in terms of competency. For instance, "Humans can reason" is automatically inferred from Adimen-SUMO v2.4, while it is neither deducible from TPTP-SUMO nor Adimen-SUMO v2.2.
* 8 pages, 2 tables
Integrating Multiple Knowledge Sources for Robust Semantic Parsing
Sep 17, 2001


This work explores a new robust approach for Semantic Parsing of unrestricted texts. Our approach considers Semantic Parsing as a Consistent Labelling Problem (CLP), allowing the integration of several knowledge types (syntactic and semantic) obtained from different sources (linguistic and statistic). The current implementation obtains 95% accuracy in model identification and 72% in case-role filling.