 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Reasoning for Multi-Faceted Commonsense Knowledge
Jan 13, 2020
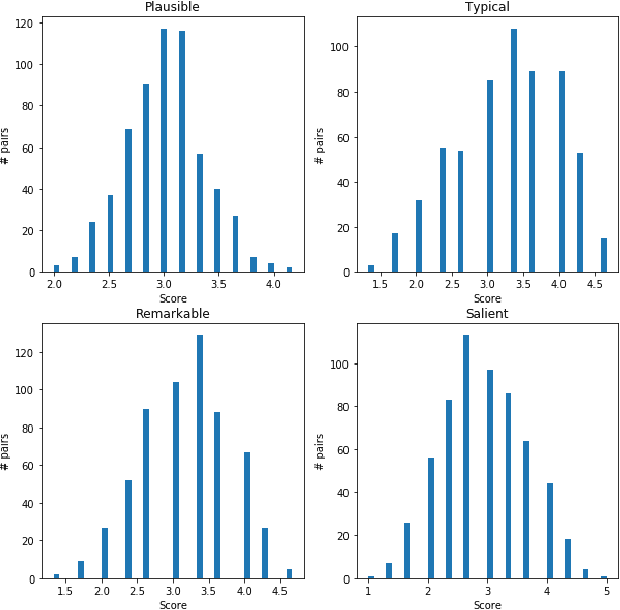

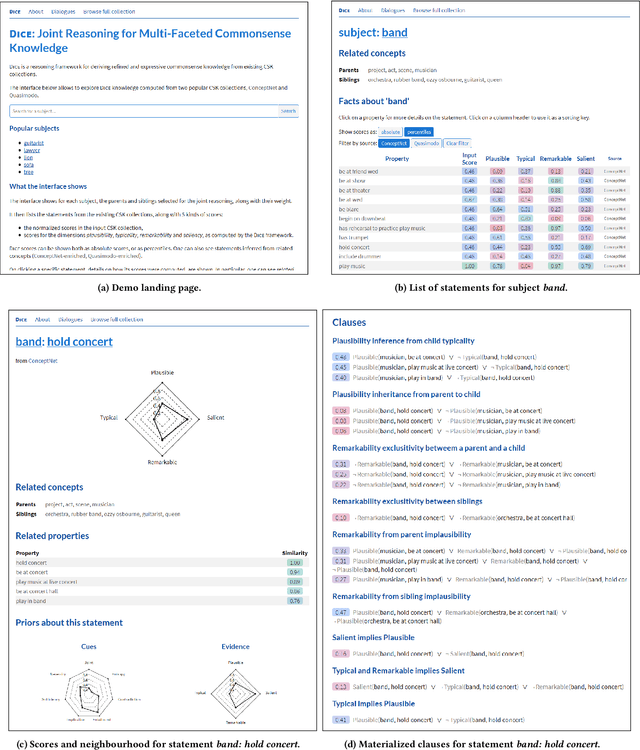
Commonsense knowledge (CSK) supports a variety of AI applications, from visual understanding to chatbots. Prior works on acquiring CSK, such as ConceptNet, have compiled statements that associate concepts, like everyday objects or activities, with properties that hold for most or some instances of the concept. Each concept is treated in isolation from other concepts, and the only quantitative measure (or ranking) of properties is a confidence score that the statement is valid. This paper aims to overcome these limitations by introducing a multi-faceted model of CSK statements and methods for joint reasoning over sets of inter-related statements. Our model captures four different dimensions of CSK statements: plausibility, typicality, remarkability and salience, with scoring and ranking along each dimension. For example, hyenas drinking water is typical but not salient, whereas hyenas eating carcasses is salient. For reasoning and ranking, we develop a method with soft constraints, to couple the inference over concepts that are related in in a taxonomic hierarchy. The reasoning is cast into an integer linear programming (ILP), and we leverage the theory of reduction costs of a relaxed LP to compute informative rankings. This methodology is applied to several large CSK collections. Our evaluation shows that we can consolidate these inputs into much cleaner and more expressive knowledge. Results are available at https://dice.mpi-inf.mpg.de.
PRINCE: Provider-side Interpretability with Counterfactual Explanations in Recommender Systems
Dec 24, 2019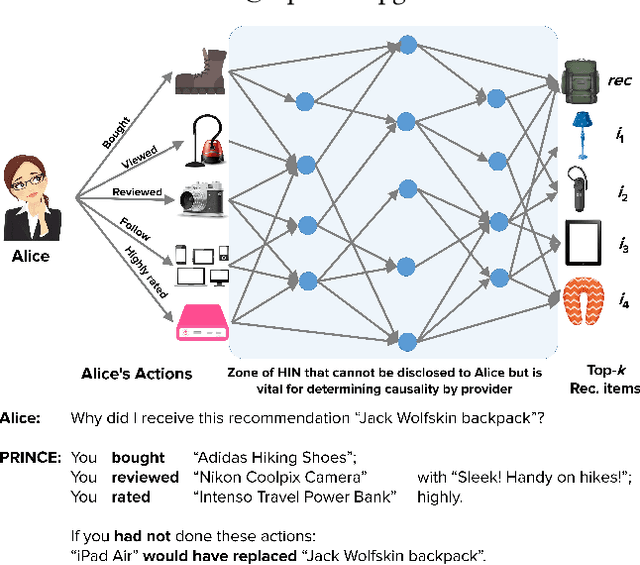

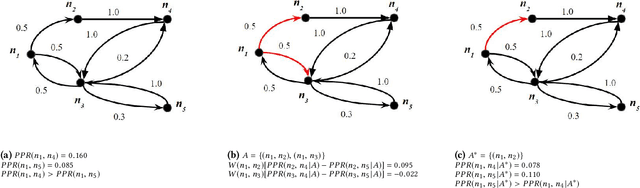
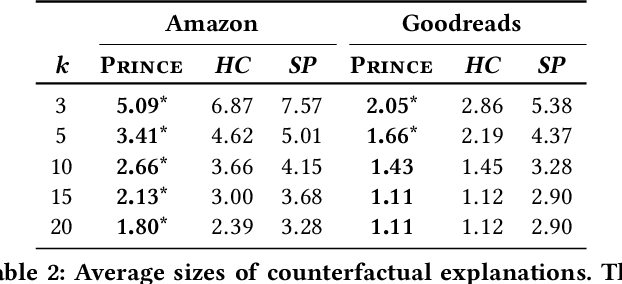
Interpretable explanations for recommender systems and other machine learning models are crucial to gain user trust. Prior works that have focused on paths connecting users and items in a heterogeneous network have several limitations, such as discovering relationships rather than true explanations, or disregarding other users' privacy. In this work, we take a fresh perspective, and present PRINCE: a provider-side mechanism to produce tangible explanations for end-users, where an explanation is defined to be a set of minimal actions performed by the user that, if removed, changes the recommendation to a different item. Given a recommendation, PRINCE uses a polynomial-time optimal algorithm for finding this minimal set of a user's actions from an exponential search space, based on random walks over dynamic graphs. Experiments on two real-world datasets show that PRINCE provides more compact explanations than intuitive baselines, and insights from a crowdsourced user-study demonstrate the viability of such action-based explanations. We thus posit that PRINCE produces scrutable, actionable, and concise explanations, owing to its use of counterfactual evidence, a user's own actions, and minimal sets, respectively.
CROWN: Conversational Passage Ranking by Reasoning over Word Networks
Nov 11, 2019
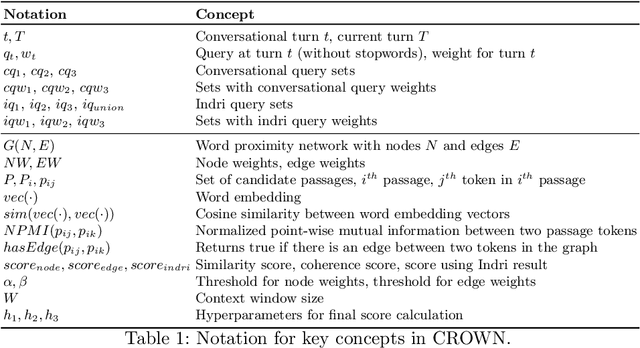
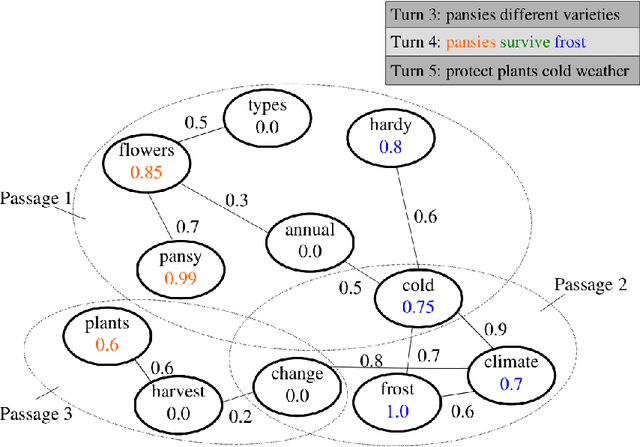
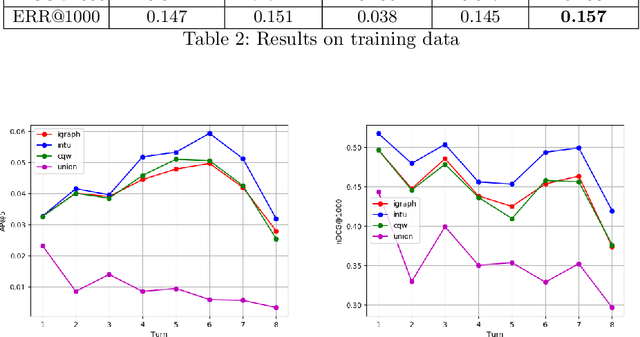
Information needs around a topic cannot be satisfied in a single turn; users typically ask follow-up questions referring to the same theme and a system must be capable of understanding the conversational context of a request to retrieve correct answers. In this paper, we present our submission to the TREC Conversational Assistance Track 2019, in which such a conversational setting is explored. We propose a simple unsupervised method for conversational passage ranking by formulating the passage score for a query as a combination of similarity and coherence. To be specific, passages are preferred that contain words semantically similar to the words used in the question, and where such words appear close by. We built a word-proximity network (WPN) from a large corpus, where words are nodes and there is an edge between two nodes if they co-occur in the same passages in a statistically significant way, within a context window. Our approach, named CROWN, improved nDCG scores over a provided Indri baseline on the CAsT training data. On the evaluation data for CAsT, our best run submission achieved above-average performance with respect to AP@5 and nDCG@1000.
* TREC 2019, 13 pages
Look before you Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion
Nov 05, 2019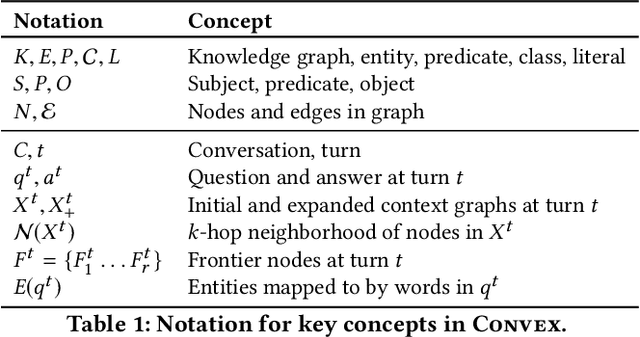
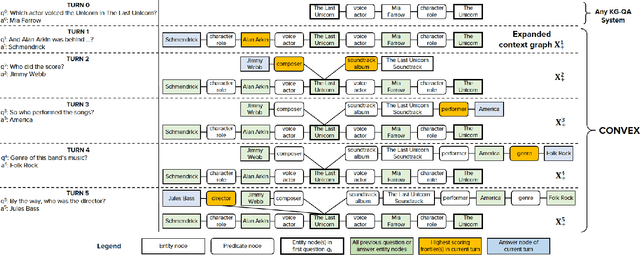
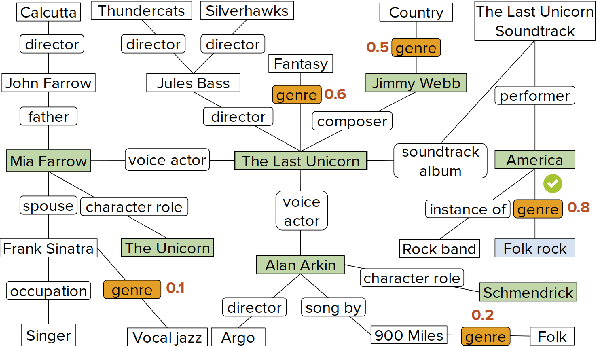

Fact-centric information needs are rarely one-shot; users typically ask follow-up questions to explore a topic. In such a conversational setting, the user's inputs are often incomplete, with entities or predicates left out, and ungrammatical phrases. This poses a huge challenge to question answering (QA) systems that typically rely on cues in full-fledged interrogative sentences. As a solution, we develop CONVEX: an unsupervised method that can answer incomplete questions over a knowledge graph (KG) by maintaining conversation context using entities and predicates seen so far and automatically inferring missing or ambiguous pieces for follow-up questions. The core of our method is a graph exploration algorithm that judiciously expands a frontier to find candidate answers for the current question. To evaluate CONVEX, we release ConvQuestions, a crowdsourced benchmark with 11,200 distinct conversations from five different domains. We show that CONVEX: (i) adds conversational support to any stand-alone QA system, and (ii) outperforms state-of-the-art baselines and question completion strategies.
* CIKM 2019 Long Paper, 10 pages
STANCY: Stance Classification Based on Consistency Cues
Oct 14, 2019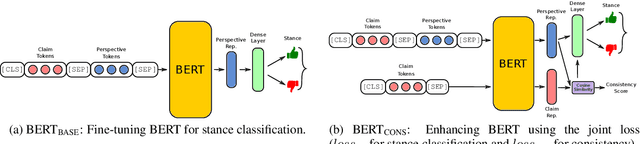
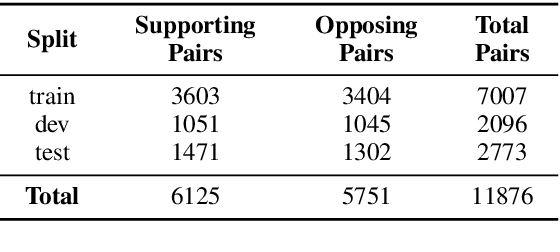
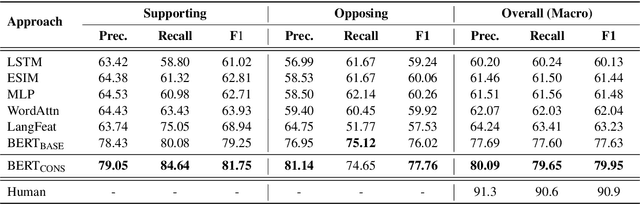
Controversial claims are abundant in online media and discussion forums. A better understanding of such claims requires analyzing them from different perspectives. Stance classification is a necessary step for inferring these perspectives in terms of supporting or opposing the claim. In this work, we present a neural network model for stance classification leveraging BERT representations and augmenting them with a novel consistency constraint. Experiments on the Perspectrum dataset, consisting of claims and users' perspectives from various debate websites, demonstrate the effectiveness of our approach over state-of-the-art baselines.
VISIR: Visual and Semantic Image Label Refinement
Sep 02, 2019

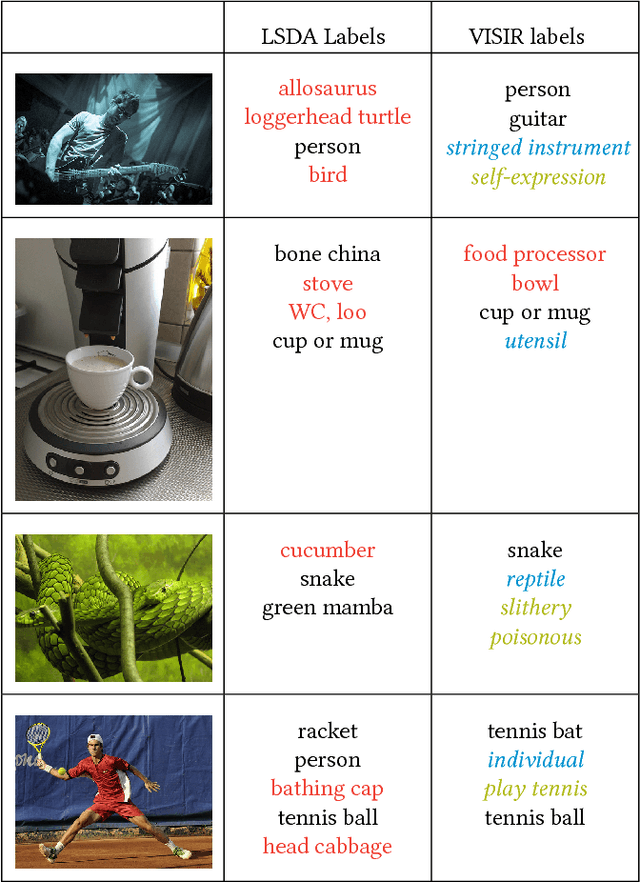
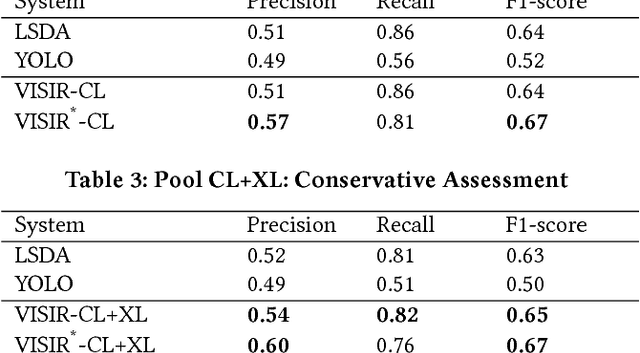
The social media explosion has populated the Internet with a wealth of images. There are two existing paradigms for image retrieval: 1) content-based image retrieval (CBIR), which has traditionally used visual features for similarity search (e.g., SIFT features), and 2) tag-based image retrieval (TBIR), which has relied on user tagging (e.g., Flickr tags). CBIR now gains semantic expressiveness by advances in deep-learning-based detection of visual labels. TBIR benefits from query-and-click logs to automatically infer more informative labels. However, learning-based tagging still yields noisy labels and is restricted to concrete objects, missing out on generalizations and abstractions. Click-based tagging is limited to terms that appear in the textual context of an image or in queries that lead to a click. This paper addresses the above limitations by semantically refining and expanding the labels suggested by learning-based object detection. We consider the semantic coherence between the labels for different objects, leverage lexical and commonsense knowledge, and cast the label assignment into a constrained optimization problem solved by an integer linear program. Experiments show that our method, called VISIR, improves the quality of the state-of-the-art visual labeling tools like LSDA and YOLO.
* Published in WSDM 2018
Story-oriented Image Selection and Placement
Sep 02, 2019
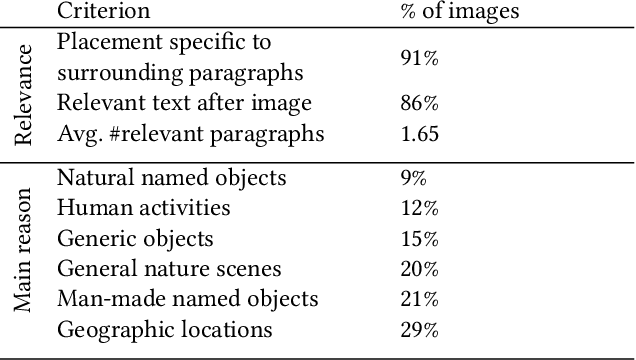

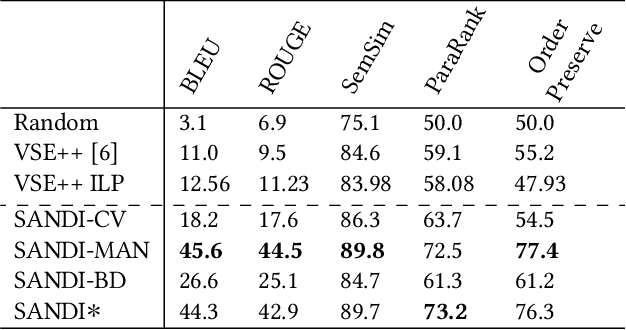
Multimodal contents have become commonplace on the Internet today, manifested as news articles, social media posts, and personal or business blog posts. Among the various kinds of media (images, videos, graphics, icons, audio) used in such multimodal stories, images are the most popular. The selection of images from a collection - either author's personal photo album, or web repositories - and their meticulous placement within a text, builds a succinct multimodal commentary for digital consumption. In this paper we present a system that automates the process of selecting relevant images for a story and placing them at contextual paragraphs within the story for a multimodal narration. We leverage automatic object recognition, user-provided tags, and commonsense knowledge, and use an unsupervised combinatorial optimization to solve the selection and placement problems seamlessly as a single unit.
TEQUILA: Temporal Question Answering over Knowledge Bases
Aug 15, 2019

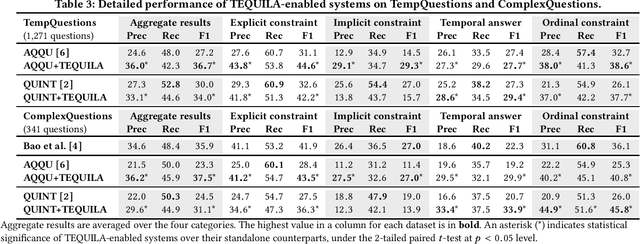
Question answering over knowledge bases (KB-QA) poses challenges in handling complex questions that need to be decomposed into sub-questions. An important case, addressed here, is that of temporal questions, where cues for temporal relations need to be discovered and handled. We present TEQUILA, an enabler method for temporal QA that can run on top of any KB-QA engine. TEQUILA has four stages. It detects if a question has temporal intent. It decomposes and rewrites the question into non-temporal sub-questions and temporal constraints. Answers to sub-questions are then retrieved from the underlying KB-QA engine. Finally, TEQUILA uses constraint reasoning on temporal intervals to compute final answers to the full question. Comparisons against state-of-the-art baselines show the viability of our method.
FAIRY: A Framework for Understanding Relationships between Users' Actions and their Social Feeds
Aug 08, 2019
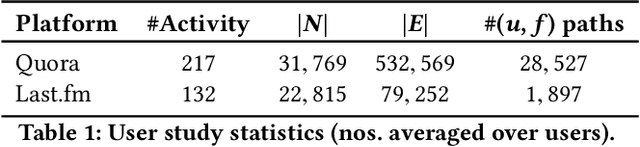
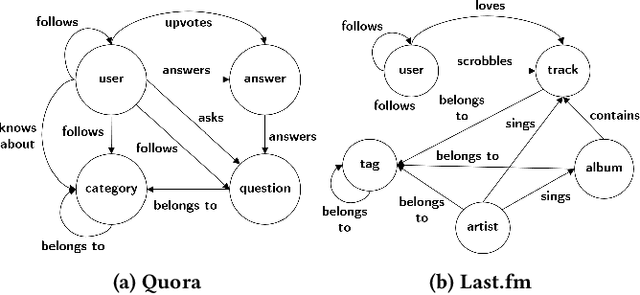
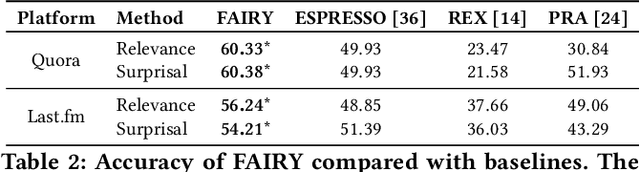
Users increasingly rely on social media feeds for consuming daily information. The items in a feed, such as news, questions, songs, etc., usually result from the complex interplay of a user's social contacts, her interests and her actions on the platform. The relationship of the user's own behavior and the received feed is often puzzling, and many users would like to have a clear explanation on why certain items were shown to them. Transparency and explainability are key concerns in the modern world of cognitive overload, filter bubbles, user tracking, and privacy risks. This paper presents FAIRY, a framework that systematically discovers, ranks, and explains relationships between users' actions and items in their social media feeds. We model the user's local neighborhood on the platform as an interaction graph, a form of heterogeneous information network constructed solely from information that is easily accessible to the concerned user. We posit that paths in this interaction graph connecting the user and her feed items can act as pertinent explanations for the user. These paths are scored with a learning-to-rank model that captures relevance and surprisal. User studies on two social platforms demonstrate the practical viability and user benefits of the FAIRY method.
Operationalizing Individual Fairness with Pairwise Fair Representations
Jul 02, 2019
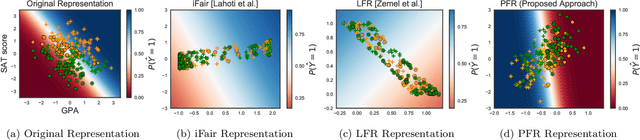
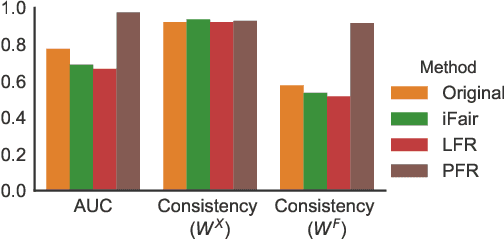
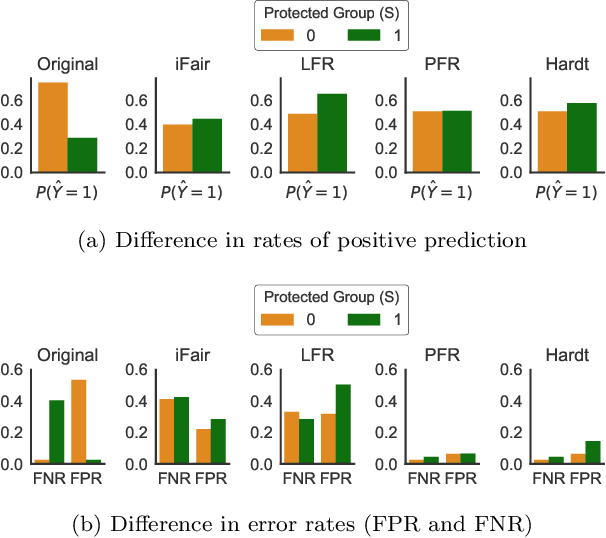
We revisit the notion of individual fairness proposed by Dwork et al. A central challenge in operationalizing their approach is the difficulty in eliciting a human specification of a similarity metric. In this paper, we propose an operationalization of individual fairness that does not rely on a human specification of a distance metric. Instead, we propose novel approaches to elicit and leverage side-information on equally deserving individuals to counter subordination between social groups. We model this knowledge as a fairness graph, and learn a unified Pairwise Fair Representation(PFR) of the data that captures both data-driven similarity between individuals and the pairwise side-information in fairness graph. We elicit fairness judgments from a variety of sources, including humans judgments for two real-world datasets on recidivism prediction (COMPAS) and violent neighborhood prediction (Crime & Communities). Our experiments show that the PFR model for operationalizing individual fairness is practically viable.