 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraMARS: A Domain-Adapted Small-Language-Model Pipeline for Mars Terraforming Literature
Jun 18, 2026Researchers are interested in learning about Mars so that it may eventually become habitable for humans. To achieve this, there is a need for comprehensive knowledge of the planet's atmosphere, hydrology, surface chemistry, radiation environment, and spatial features through the scientific literature. These contain valuable information and meaningful quantitative constraints that can be used in other models and studies, such as habitability assessment and future terraforming studies. We present TerraMARS, an end-to-end information extraction pipeline that combines a domain-adapted Small Language Model to answer Mars terraforming-related questions and convert unstructured Mars science text into machine-readable structured outputs in JavaScript Object Notation (JSON) format. A corpus of open-access papers is collected and processed using a multistage retrieval and chunking framework. Google Gemma 3 1B was adapted to the domain using Quantized Low-Rank Adaptation (QLoRA) fine-tuning on Mars-specific question-answering and information extraction datasets. The resulting pipeline generates both types of output and provides a foundation for integrating knowledge from scientific literature into downstream applications like digital twins and habitability modeling for Mars. The output from this pipeline looks promising, but further improvements are needed to increase extraction accuracy and factual consistency.
SOAR: Advancements in Small Body Object Detection for Aerial Imagery Using State Space Models and Programmable Gradients
May 06, 2024



Small object detection in aerial imagery presents significant challenges in computer vision due to the minimal data inherent in small-sized objects and their propensity to be obscured by larger objects and background noise. Traditional methods using transformer-based models often face limitations stemming from the lack of specialized databases, which adversely affect their performance with objects of varying orientations and scales. This underscores the need for more adaptable, lightweight models. In response, this paper introduces two innovative approaches that significantly enhance detection and segmentation capabilities for small aerial objects. Firstly, we explore the use of the SAHI framework on the newly introduced lightweight YOLO v9 architecture, which utilizes Programmable Gradient Information (PGI) to reduce the substantial information loss typically encountered in sequential feature extraction processes. The paper employs the Vision Mamba model, which incorporates position embeddings to facilitate precise location-aware visual understanding, combined with a novel bidirectional State Space Model (SSM) for effective visual context modeling. This State Space Model adeptly harnesses the linear complexity of CNNs and the global receptive field of Transformers, making it particularly effective in remote sensing image classification. Our experimental results demonstrate substantial improvements in detection accuracy and processing efficiency, validating the applicability of these approaches for real-time small object detection across diverse aerial scenarios. This paper also discusses how these methodologies could serve as foundational models for future advancements in aerial object recognition technologies. The source code will be made accessible here.
Simplify Your Law: Using Information Theory to Deduplicate Legal Documents
Oct 02, 2021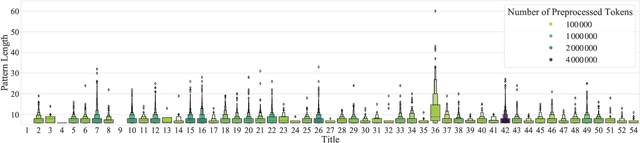
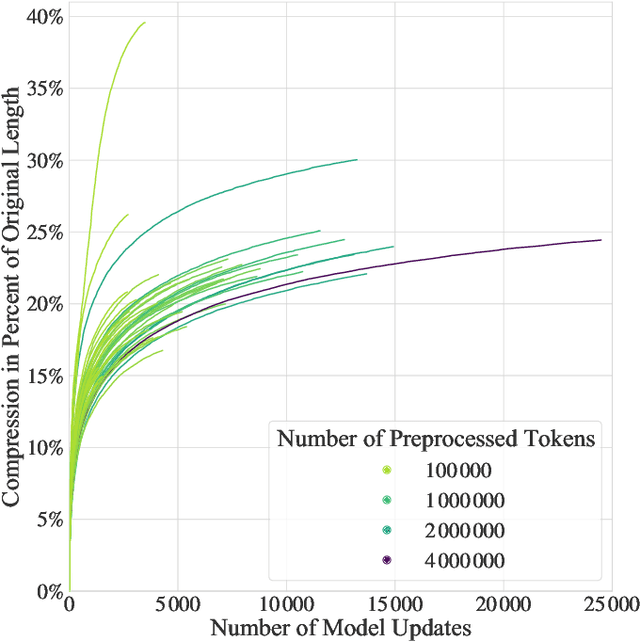
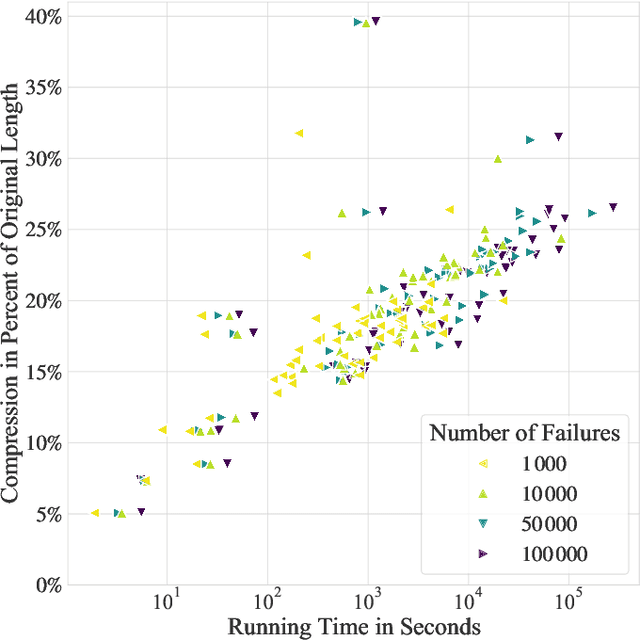
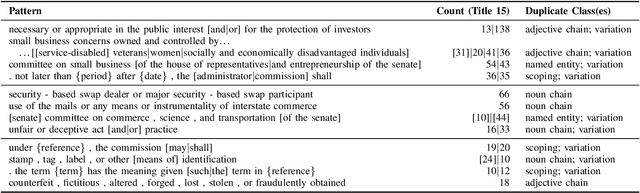
Textual redundancy is one of the main challenges to ensuring that legal texts remain comprehensible and maintainable. Drawing inspiration from the refactoring literature in software engineering, which has developed methods to expose and eliminate duplicated code, we introduce the duplicated phrase detection problem for legal texts and propose the Dupex algorithm to solve it. Leveraging the Minimum Description Length principle from information theory, Dupex identifies a set of duplicated phrases, called patterns, that together best compress a given input text. Through an extensive set of experiments on the Titles of the United States Code, we confirm that our algorithm works well in practice: Dupex will help you simplify your law.
Look before you Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion
Nov 05, 2019
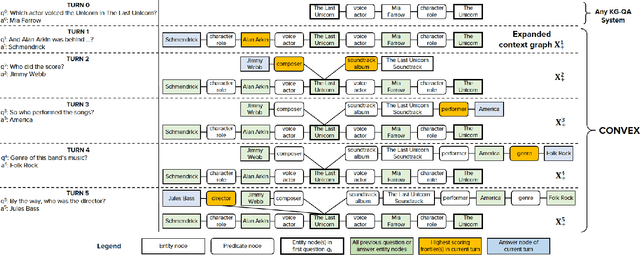
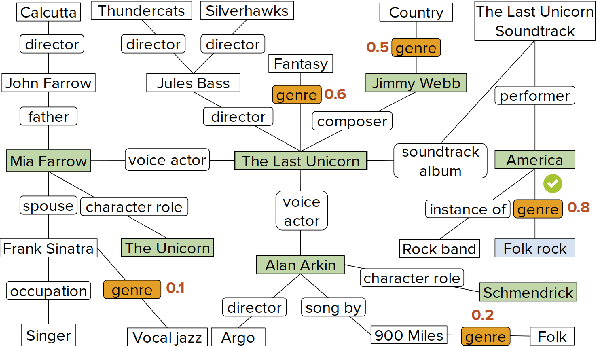

Fact-centric information needs are rarely one-shot; users typically ask follow-up questions to explore a topic. In such a conversational setting, the user's inputs are often incomplete, with entities or predicates left out, and ungrammatical phrases. This poses a huge challenge to question answering (QA) systems that typically rely on cues in full-fledged interrogative sentences. As a solution, we develop CONVEX: an unsupervised method that can answer incomplete questions over a knowledge graph (KG) by maintaining conversation context using entities and predicates seen so far and automatically inferring missing or ambiguous pieces for follow-up questions. The core of our method is a graph exploration algorithm that judiciously expands a frontier to find candidate answers for the current question. To evaluate CONVEX, we release ConvQuestions, a crowdsourced benchmark with 11,200 distinct conversations from five different domains. We show that CONVEX: (i) adds conversational support to any stand-alone QA system, and (ii) outperforms state-of-the-art baselines and question completion strategies.
* CIKM 2019 Long Paper, 10 pages