 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubpixel Heatmap Regression for Facial Landmark Localization
Nov 03, 2021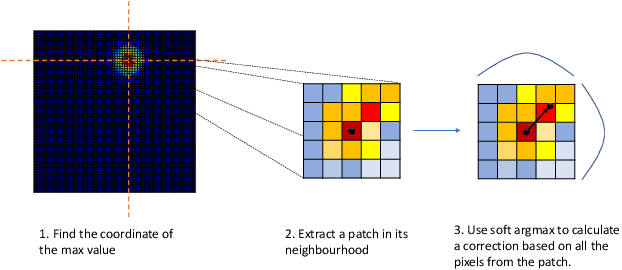
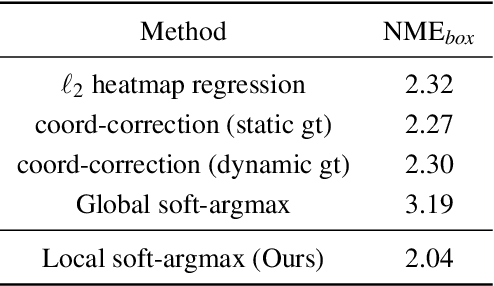
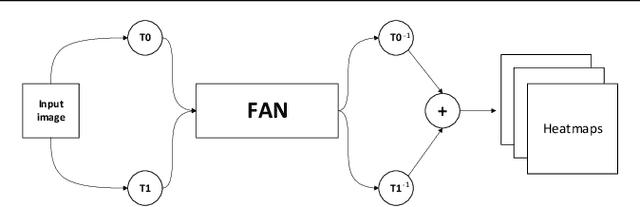

Deep Learning models based on heatmap regression have revolutionized the task of facial landmark localization with existing models working robustly under large poses, non-uniform illumination and shadows, occlusions and self-occlusions, low resolution and blur. However, despite their wide adoption, heatmap regression approaches suffer from discretization-induced errors related to both the heatmap encoding and decoding process. In this work we show that these errors have a surprisingly large negative impact on facial alignment accuracy. To alleviate this problem, we propose a new approach for the heatmap encoding and decoding process by leveraging the underlying continuous distribution. To take full advantage of the newly proposed encoding-decoding mechanism, we also introduce a Siamese-based training that enforces heatmap consistency across various geometric image transformations. Our approach offers noticeable gains across multiple datasets setting a new state-of-the-art result in facial landmark localization. Code alongside the pretrained models will be made available at https://www.adrianbulat.com/face-alignment
Defensive Tensorization
Oct 26, 2021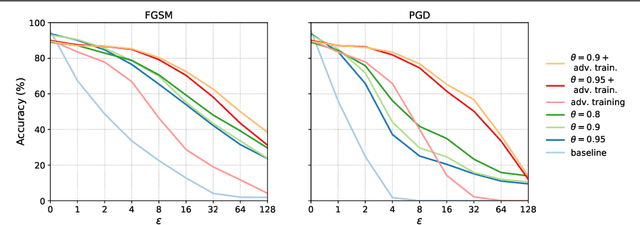
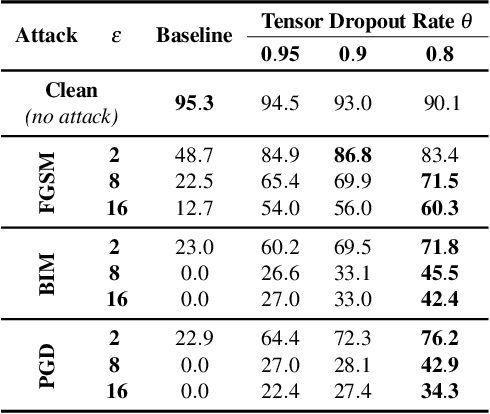
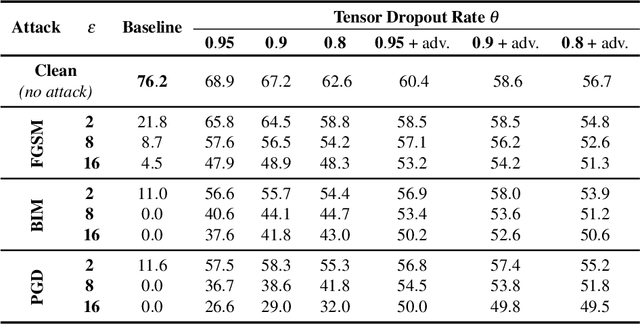
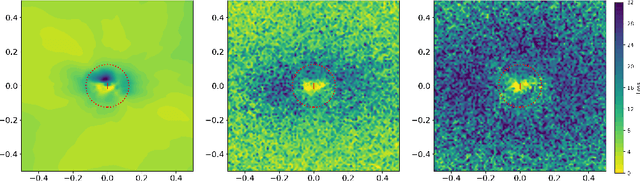
We propose defensive tensorization, an adversarial defence technique that leverages a latent high-order factorization of the network. The layers of a network are first expressed as factorized tensor layers. Tensor dropout is then applied in the latent subspace, therefore resulting in dense reconstructed weights, without the sparsity or perturbations typically induced by the randomization.Our approach can be readily integrated with any arbitrary neural architecture and combined with techniques like adversarial training. We empirically demonstrate the effectiveness of our approach on standard image classification benchmarks. We validate the versatility of our approach across domains and low-precision architectures by considering an audio classification task and binary networks. In all cases, we demonstrate improved performance compared to prior works.
SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021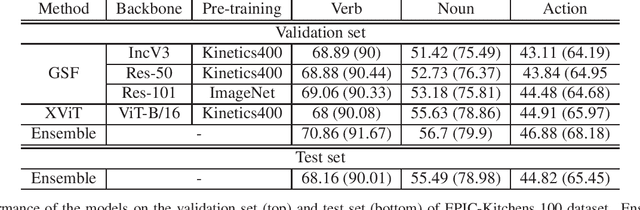
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
WarpedGANSpace: Finding non-linear RBF paths in GAN latent space
Sep 27, 2021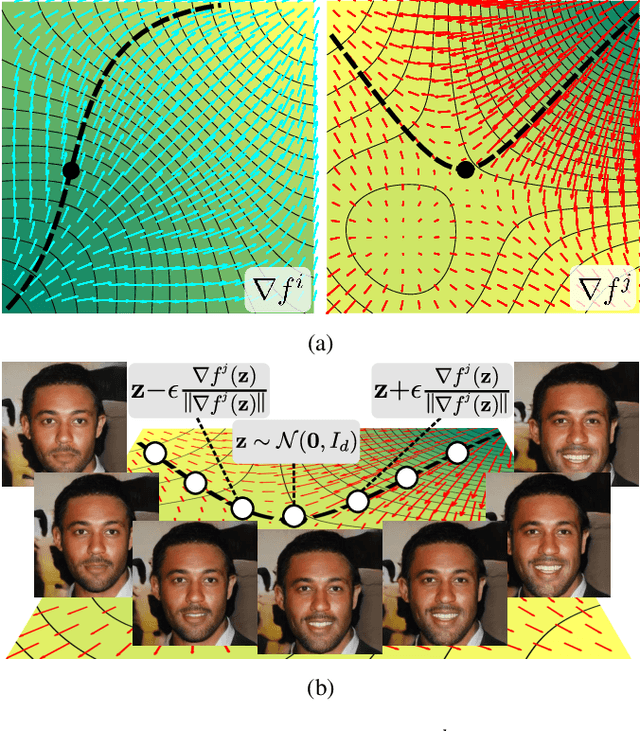
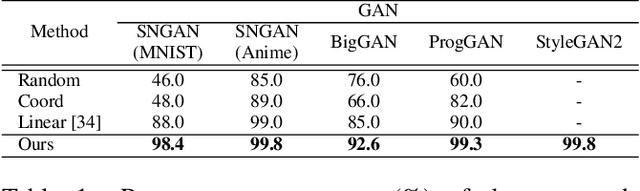
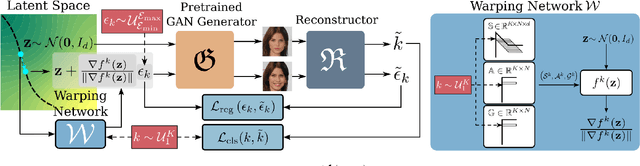
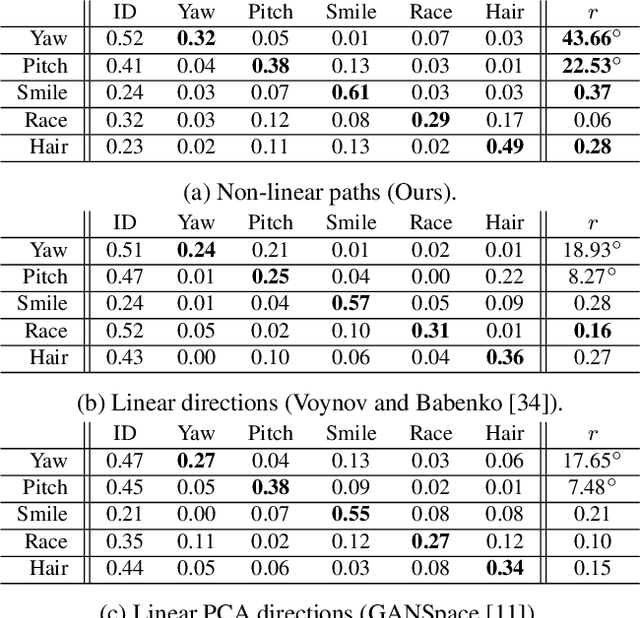
This work addresses the problem of discovering, in an unsupervised manner, interpretable paths in the latent space of pretrained GANs, so as to provide an intuitive and easy way of controlling the underlying generative factors. In doing so, it addresses some of the limitations of the state-of-the-art works, namely, a) that they discover directions that are independent of the latent code, i.e., paths that are linear, and b) that their evaluation relies either on visual inspection or on laborious human labeling. More specifically, we propose to learn non-linear warpings on the latent space, each one parametrized by a set of RBF-based latent space warping functions, and where each warping gives rise to a family of non-linear paths via the gradient of the function. Building on the work of Voynov and Babenko, that discovers linear paths, we optimize the trainable parameters of the set of RBFs, so as that images that are generated by codes along different paths, are easily distinguishable by a discriminator network. This leads to easily distinguishable image transformations, such as pose and facial expressions in facial images. We show that linear paths can be derived as a special case of our method, and show experimentally that non-linear paths in the latent space lead to steeper, more disentangled and interpretable changes in the image space than in state-of-the art methods, both qualitatively and quantitatively. We make the code and the pretrained models publicly available at: https://github.com/chi0tzp/WarpedGANSpace.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021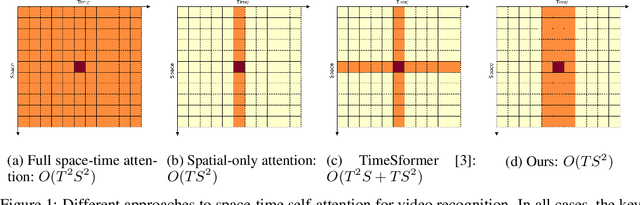
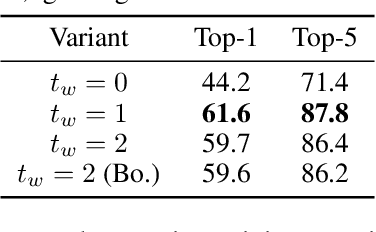
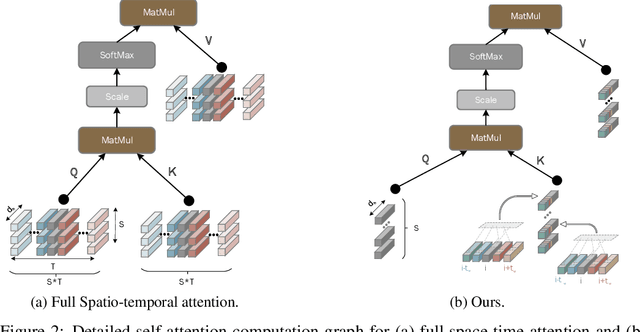
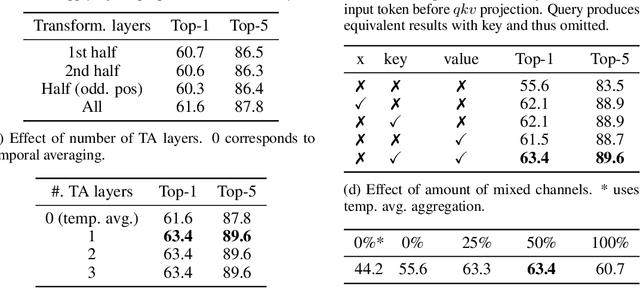
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Bit-Mixer: Mixed-precision networks with runtime bit-width selection
Mar 31, 2021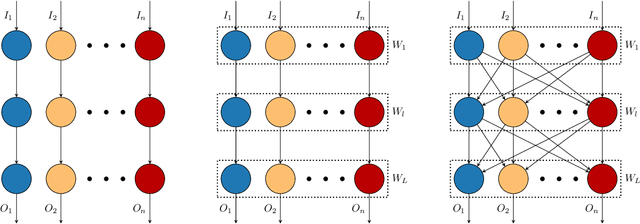

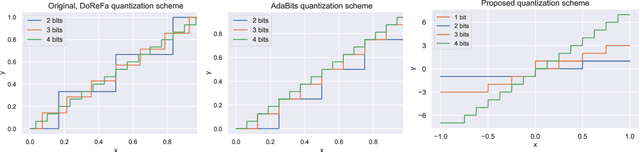
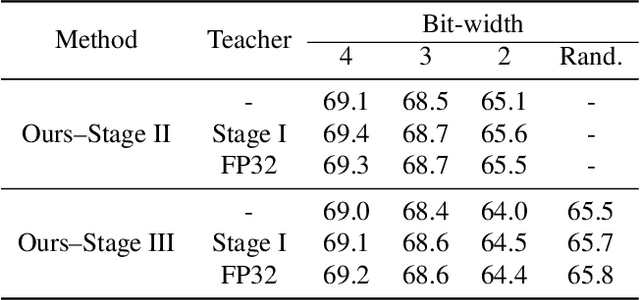
Mixed-precision networks allow for a variable bit-width quantization for every layer in the network. A major limitation of existing work is that the bit-width for each layer must be predefined during training time. This allows little flexibility if the characteristics of the device on which the network is deployed change during runtime. In this work, we propose Bit-Mixer, the very first method to train a meta-quantized network where during test time any layer can change its bid-width without affecting at all the overall network's ability for highly accurate inference. To this end, we make 2 key contributions: (a) Transitional Batch-Norms, and (b) a 3-stage optimization process which is shown capable of training such a network. We show that our method can result in mixed precision networks that exhibit the desirable flexibility properties for on-device deployment without compromising accuracy. Code will be made available.
Pre-training strategies and datasets for facial representation learning
Mar 30, 2021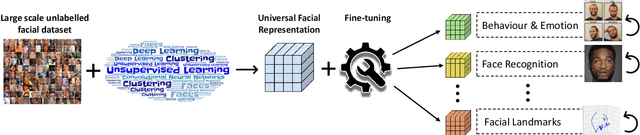
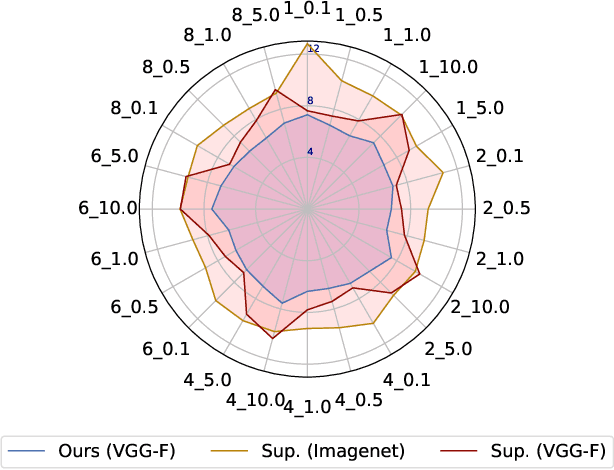
What is the best way to learn a universal face representation? Recent work on Deep Learning in the area of face analysis has focused on supervised learning for specific tasks of interest (e.g. face recognition, facial landmark localization etc.) but has overlooked the overarching question of how to find a facial representation that can be readily adapted to several facial analysis tasks and datasets. To this end, we make the following 4 contributions: (a) we introduce, for the first time, a comprehensive evaluation benchmark for facial representation learning consisting of 5 important face analysis tasks. (b) We systematically investigate two ways of large-scale representation learning applied to faces: supervised and unsupervised pre-training. Importantly, we focus our evaluations on the case of few-shot facial learning. (c) We investigate important properties of the training datasets including their size and quality (labelled, unlabelled or even uncurated). (d) To draw our conclusions, we conducted a very large number of experiments. Our main two findings are: (1) Unsupervised pre-training on completely in-the-wild, uncurated data provides consistent and, in some cases, significant accuracy improvements for all facial tasks considered. (2) Many existing facial video datasets seem to have a large amount of redundancy. We will release code, pre-trained models and data to facilitate future research.
Affective Processes: stochastic modelling of temporal context for emotion and facial expression recognition
Mar 24, 2021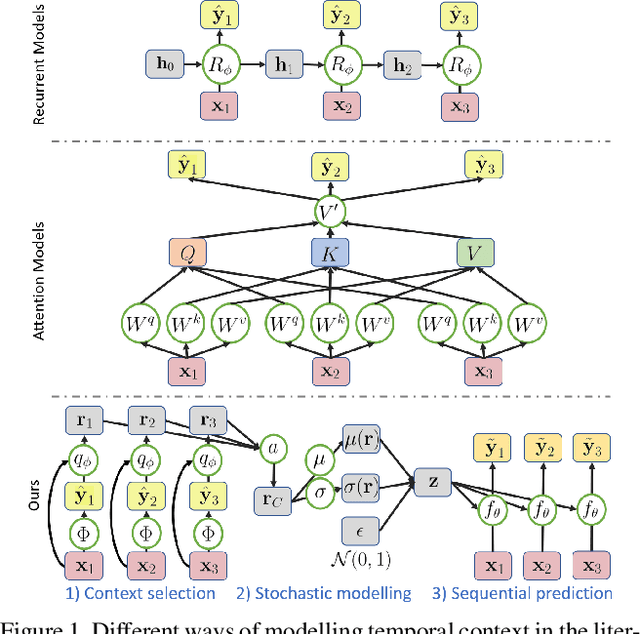
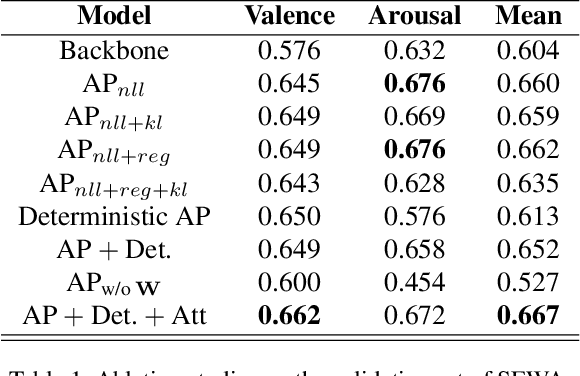
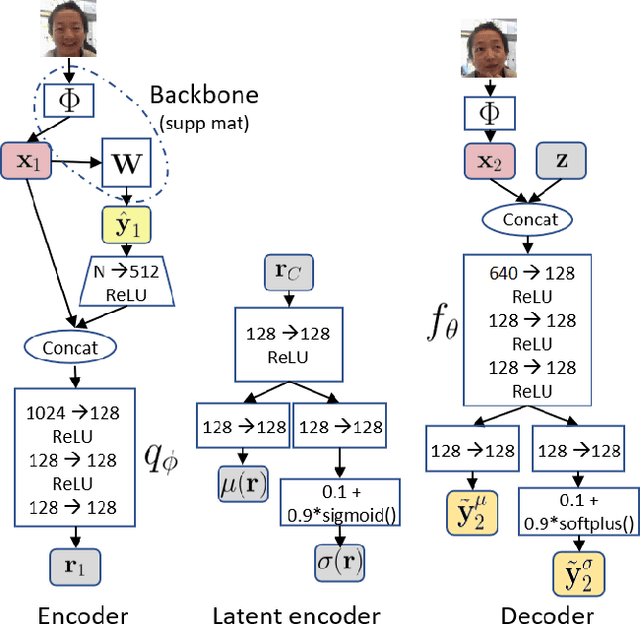
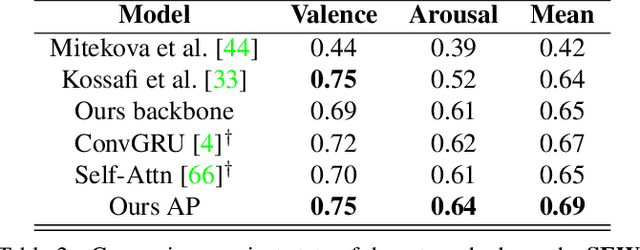
Temporal context is key to the recognition of expressions of emotion. Existing methods, that rely on recurrent or self-attention models to enforce temporal consistency, work on the feature level, ignoring the task-specific temporal dependencies, and fail to model context uncertainty. To alleviate these issues, we build upon the framework of Neural Processes to propose a method for apparent emotion recognition with three key novel components: (a) probabilistic contextual representation with a global latent variable model; (b) temporal context modelling using task-specific predictions in addition to features; and (c) smart temporal context selection. We validate our approach on four databases, two for Valence and Arousal estimation (SEWA and AffWild2), and two for Action Unit intensity estimation (DISFA and BP4D). Results show a consistent improvement over a series of strong baselines as well as over state-of-the-art methods.
Improving memory banks for unsupervised learning with large mini-batch, consistency and hard negative mining
Feb 08, 2021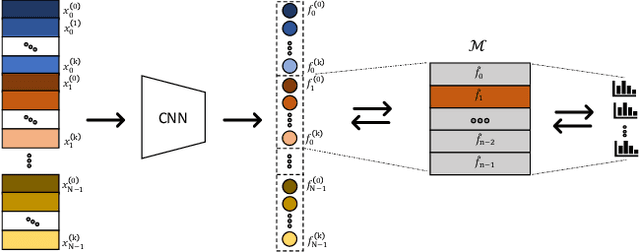
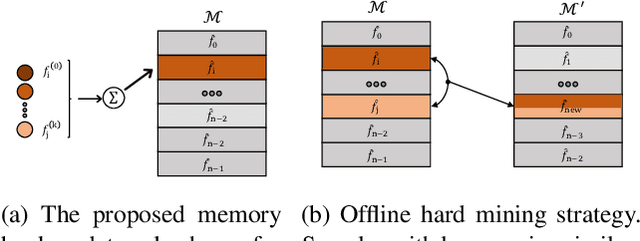


An important component of unsupervised learning by instance-based discrimination is a memory bank for storing a feature representation for each training sample in the dataset. In this paper, we introduce 3 improvements to the vanilla memory bank-based formulation which brings massive accuracy gains: (a) Large mini-batch: we pull multiple augmentations for each sample within the same batch and show that this leads to better models and enhanced memory bank updates. (b) Consistency: we enforce the logits obtained by different augmentations of the same sample to be close without trying to enforce discrimination with respect to negative samples as proposed by previous approaches. (c) Hard negative mining: since instance discrimination is not meaningful for samples that are too visually similar, we devise a novel nearest neighbour approach for improving the memory bank that gradually merges extremely similar data samples that were previously forced to be apart by the instance level classification loss. Overall, our approach greatly improves the vanilla memory-bank based instance discrimination and outperforms all existing methods for both seen and unseen testing categories with cosine similarity.
Semi-supervised Facial Action Unit Intensity Estimation with Contrastive Learning
Nov 04, 2020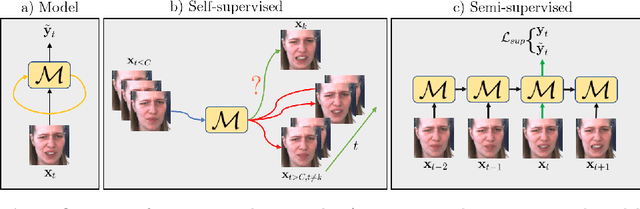
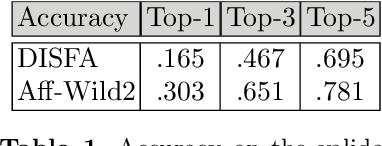
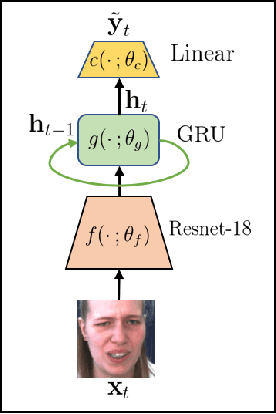
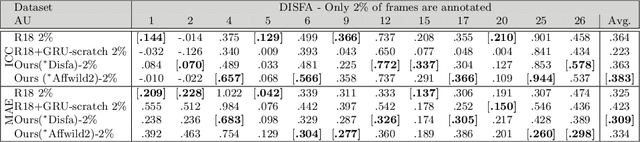
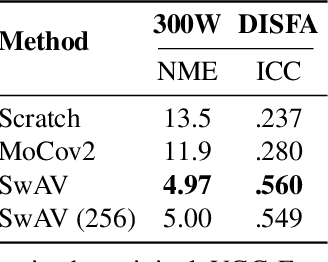
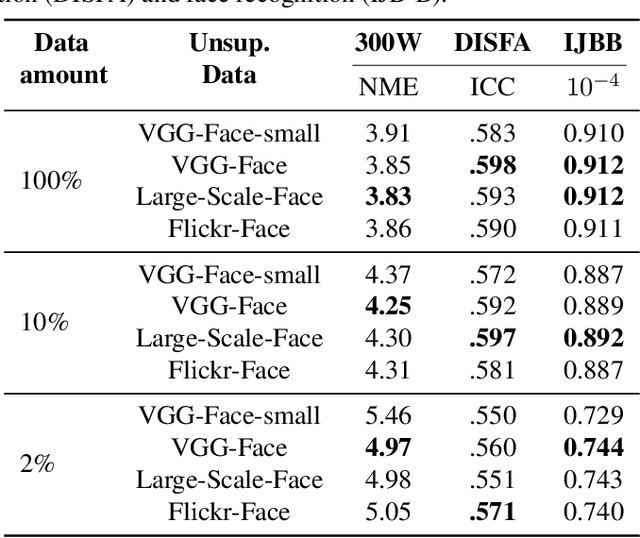
This paper tackles the challenging problem of estimating the intensity of Facial Action Units with few labeled images. Contrary to previous works, our method does not require to manually select key frames, and produces state-of-the-art results with as little as $2\%$ of annotated frames, which are \textit{randomly chosen}. To this end, we propose a semi-supervised learning approach where a spatio-temporal model combining a feature extractor and a temporal module are learned in two stages. The first stage uses datasets of unlabeled videos to learn a strong spatio-temporal representation of facial behavior dynamics based on contrastive learning. To our knowledge we are the first to build upon this framework for modeling facial behavior in an unsupervised manner. The second stage uses another dataset of randomly chosen labeled frames to train a regressor on top of our spatio-temporal model for estimating the AU intensity. We show that although backpropagation through time is applied only with respect to the output of the network for extremely sparse and randomly chosen labeled frames, our model can be effectively trained to estimate AU intensity accurately, thanks to the unsupervised pre-training of the first stage. We experimentally validate that our method outperforms existing methods when working with as little as $2\%$ of randomly chosen data for both DISFA and BP4D datasets, without a careful choice of labeled frames, a time-consuming task still required in previous approaches.