 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: REtrieve & Self-Train for generative action recognition
Sep 29, 2022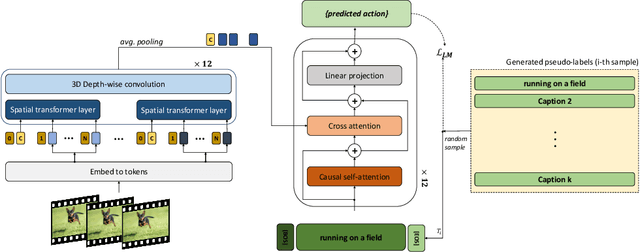
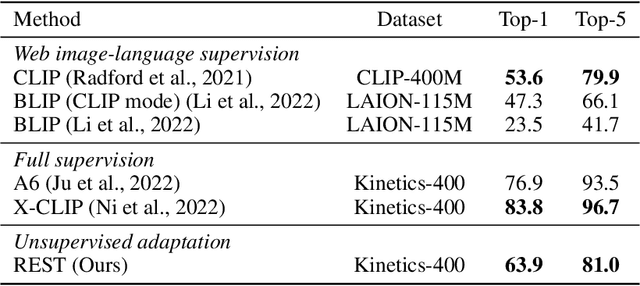
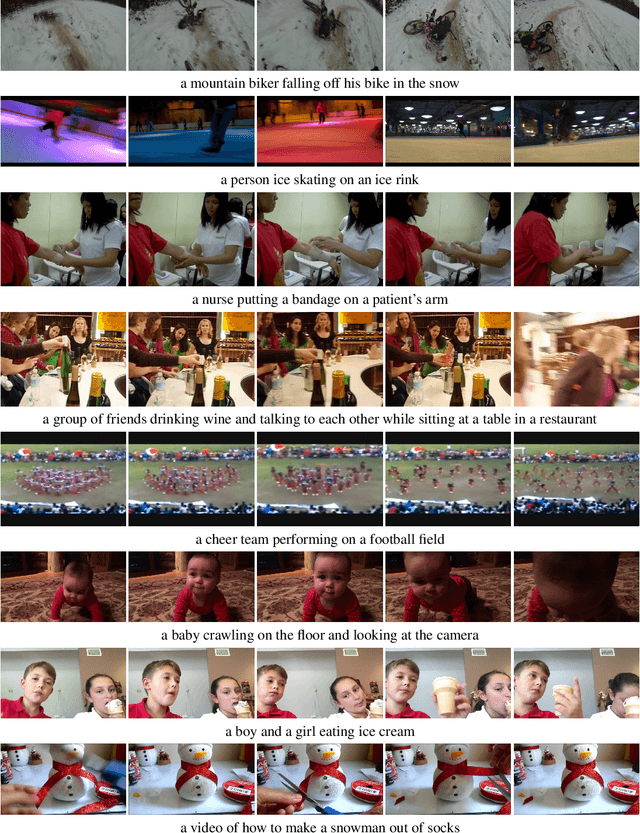
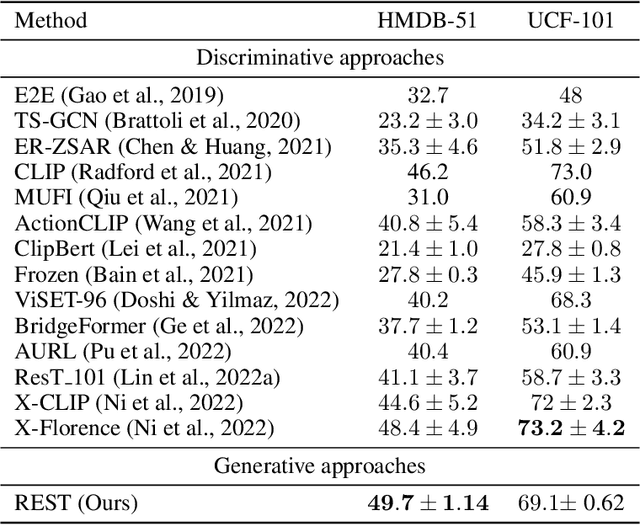
This work is on training a generative action/video recognition model whose output is a free-form action-specific caption describing the video (rather than an action class label). A generative approach has practical advantages like producing more fine-grained and human-readable output, and being naturally open-world. To this end, we propose to adapt a pre-trained generative Vision & Language (V&L) Foundation Model for video/action recognition. While recently there have been a few attempts to adapt V&L models trained with contrastive learning (e.g. CLIP) for video/action, to the best of our knowledge, we propose the very first method that sets outs to accomplish this goal for a generative model. We firstly show that direct fine-tuning of a generative model to produce action classes suffers from severe overfitting. To alleviate this, we introduce REST, a training framework consisting of two key components: an unsupervised method for adapting the generative model to action/video by means of pseudo-caption generation and Self-training, i.e. without using any action-specific labels; (b) a Retrieval approach based on CLIP for discovering a diverse set of pseudo-captions for each video to train the model. Importantly, we show that both components are necessary to obtain high accuracy. We evaluate REST on the problem of zero-shot action recognition where we show that our approach is very competitive when compared to contrastive learning-based methods. Code will be made available.
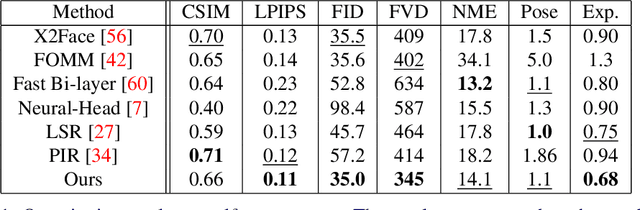
StyleMask: Disentangling the Style Space of StyleGAN2 for Neural Face Reenactment
Sep 27, 2022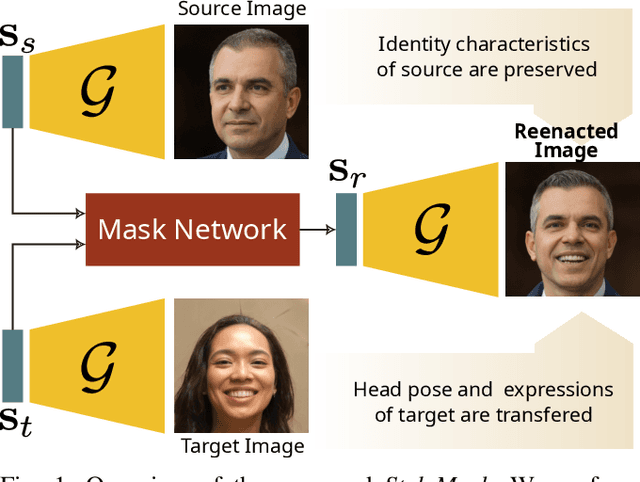



In this paper we address the problem of neural face reenactment, where, given a pair of a source and a target facial image, we need to transfer the target's pose (defined as the head pose and its facial expressions) to the source image, by preserving at the same time the source's identity characteristics (e.g., facial shape, hair style, etc), even in the challenging case where the source and the target faces belong to different identities. In doing so, we address some of the limitations of the state-of-the-art works, namely, a) that they depend on paired training data (i.e., source and target faces have the same identity), b) that they rely on labeled data during inference, and c) that they do not preserve identity in large head pose changes. More specifically, we propose a framework that, using unpaired randomly generated facial images, learns to disentangle the identity characteristics of the face from its pose by incorporating the recently introduced style space $\mathcal{S}$ of StyleGAN2, a latent representation space that exhibits remarkable disentanglement properties. By capitalizing on this, we learn to successfully mix a pair of source and target style codes using supervision from a 3D model. The resulting latent code, that is subsequently used for reenactment, consists of latent units corresponding to the facial pose of the target only and of units corresponding to the identity of the source only, leading to notable improvement in the reenactment performance compared to recent state-of-the-art methods. In comparison to state of the art, we quantitatively and qualitatively show that the proposed method produces higher quality results even on extreme pose variations. Finally, we report results on real images by first embedding them on the latent space of the pretrained generator. We make the code and pretrained models publicly available at: https://github.com/StelaBou/StyleMask
Efficient Attention-free Video Shift Transformers
Aug 23, 2022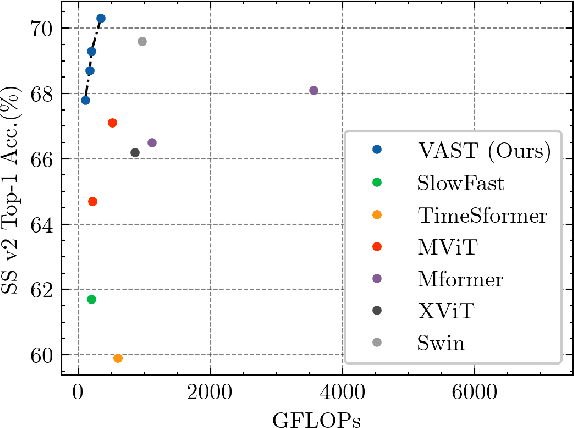

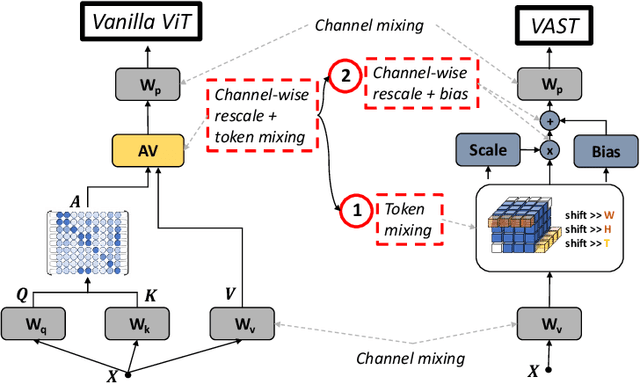
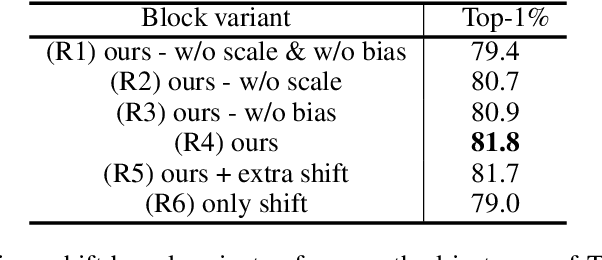
This paper tackles the problem of efficient video recognition. In this area, video transformers have recently dominated the efficiency (top-1 accuracy vs FLOPs) spectrum. At the same time, there have been some attempts in the image domain which challenge the necessity of the self-attention operation within the transformer architecture, advocating the use of simpler approaches for token mixing. However, there are no results yet for the case of video recognition, where the self-attention operator has a significantly higher impact (compared to the case of images) on efficiency. To address this gap, in this paper, we make the following contributions: (a) we construct a highly efficient \& accurate attention-free block based on the shift operator, coined Affine-Shift block, specifically designed to approximate as closely as possible the operations in the MHSA block of a Transformer layer. Based on our Affine-Shift block, we construct our Affine-Shift Transformer and show that it already outperforms all existing shift/MLP--based architectures for ImageNet classification. (b) We extend our formulation in the video domain to construct Video Affine-Shift Transformer (VAST), the very first purely attention-free shift-based video transformer. (c) We show that VAST significantly outperforms recent state-of-the-art transformers on the most popular action recognition benchmarks for the case of models with low computational and memory footprint. Code will be made available.
iBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Jun 16, 2022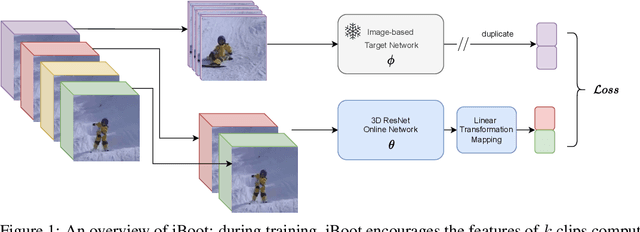



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.
ContraCLIP: Interpretable GAN generation driven by pairs of contrasting sentences
Jun 05, 2022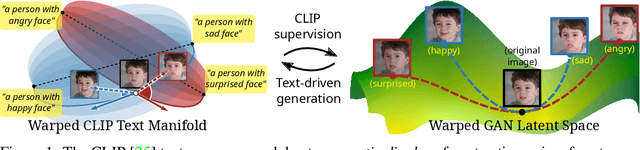
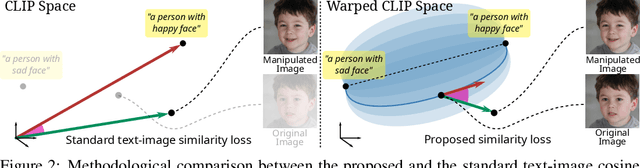

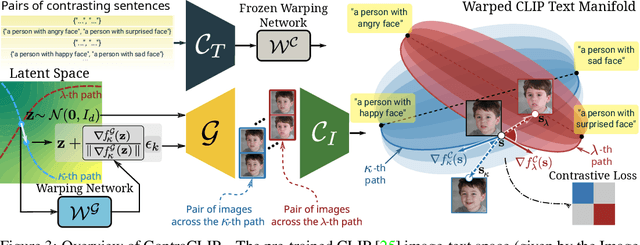
This work addresses the problem of discovering non-linear interpretable paths in the latent space of pre-trained GANs in a model-agnostic manner. In the proposed method, the discovery is driven by a set of pairs of natural language sentences with contrasting semantics, named semantic dipoles, that serve as the limits of the interpretation that we require by the trainable latent paths to encode. By using the pre-trained CLIP encoder, the sentences are projected into the vision-language space, where they serve as dipoles, and where RBF-based warping functions define a set of non-linear directional paths, one for each semantic dipole, allowing in this way traversals from one semantic pole to the other. By defining an objective that discovers paths in the latent space of GANs that generate changes along the desired paths in the vision-language embedding space, we provide an intuitive way of controlling the underlying generative factors and address some of the limitations of the state-of-the-art works, namely, that a) they are typically tailored to specific GAN architectures (i.e., StyleGAN), b) they disregard the relative position of the manipulated and the original image in the image embedding and the relative position of the image and the text embeddings, and c) they lead to abrupt image manipulations and quickly arrive at regions of low density and, thus, low image quality, providing limited control of the generative factors. We provide extensive qualitative and quantitative results that demonstrate our claims with two pre-trained GANs, and make the code and the pre-trained models publicly available at: https://github.com/chi0tzp/ContraCLIP
From Keypoints to Object Landmarks via Self-Training Correspondence: A novel approach to Unsupervised Landmark Discovery
May 31, 2022
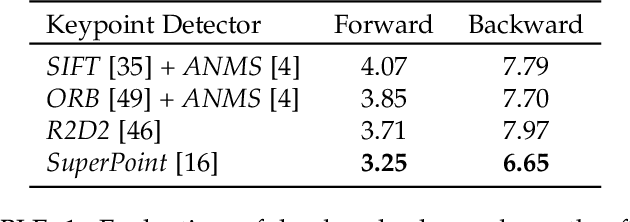
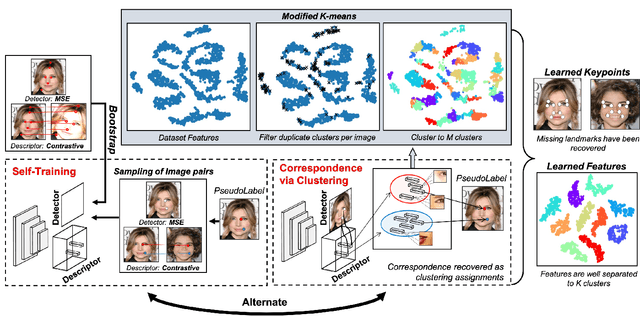
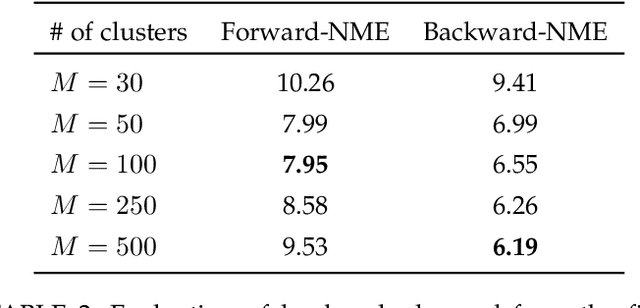
This paper proposes a novel paradigm for the unsupervised learning of object landmark detectors. Contrary to existing methods that build on auxiliary tasks such as image generation or equivariance, we propose a self-training approach where, departing from generic keypoints, a landmark detector and descriptor is trained to improve itself, tuning the keypoints into distinctive landmarks. To this end, we propose an iterative algorithm that alternates between producing new pseudo-labels through feature clustering and learning distinctive features for each pseudo-class through contrastive learning. With a shared backbone for the landmark detector and descriptor, the keypoint locations progressively converge to stable landmarks, filtering those less stable. Compared to previous works, our approach can learn points that are more flexible in terms of capturing large viewpoint changes. We validate our method on a variety of difficult datasets, including LS3D, BBCPose, Human3.6M and PennAction, achieving new state of the art results.
Knowledge Distillation Meets Open-Set Semi-Supervised Learning
May 13, 2022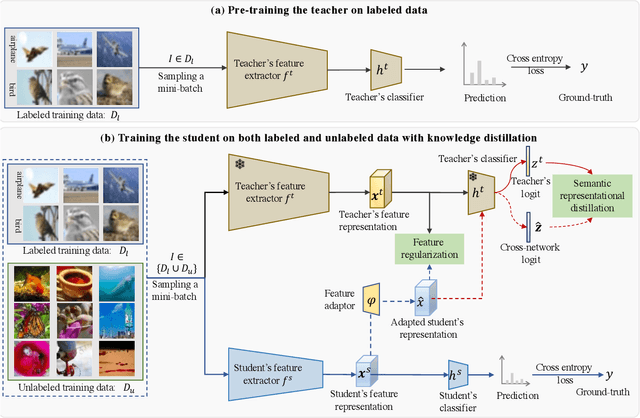
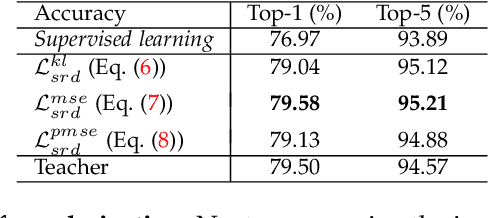
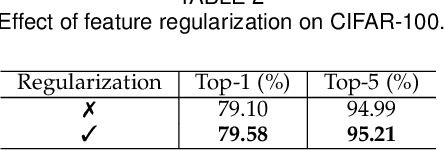

Existing knowledge distillation methods mostly focus on distillation of teacher's prediction and intermediate activation. However, the structured representation, which arguably is one of the most critical ingredients of deep models, is largely overlooked. In this work, we propose a novel {\em \modelname{}} ({\bf\em \shortname{})} method dedicated for distilling representational knowledge semantically from a pretrained teacher to a target student. The key idea is that we leverage the teacher's classifier as a semantic critic for evaluating the representations of both teacher and student and distilling the semantic knowledge with high-order structured information over all feature dimensions. This is accomplished by introducing a notion of cross-network logit computed through passing student's representation into teacher's classifier. Further, considering the set of seen classes as a basis for the semantic space in a combinatorial perspective, we scale \shortname{} to unseen classes for enabling effective exploitation of largely available, arbitrary unlabeled training data. At the problem level, this establishes an interesting connection between knowledge distillation with open-set semi-supervised learning (SSL). Extensive experiments show that our \shortname{} outperforms significantly previous state-of-the-art knowledge distillation methods on both coarse object classification and fine face recognition tasks, as well as less studied yet practically crucial binary network distillation. Under more realistic open-set SSL settings we introduce, we reveal that knowledge distillation is generally more effective than existing Out-Of-Distribution (OOD) sample detection, and our proposed \shortname{} is superior over both previous distillation and SSL competitors. The source code is available at \url{https://github.com/jingyang2017/SRD\_ossl}.
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022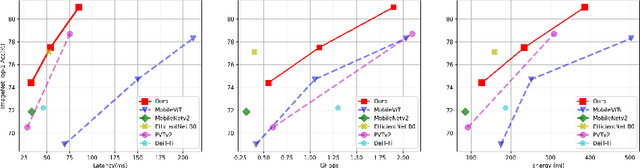
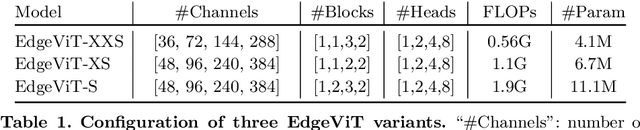
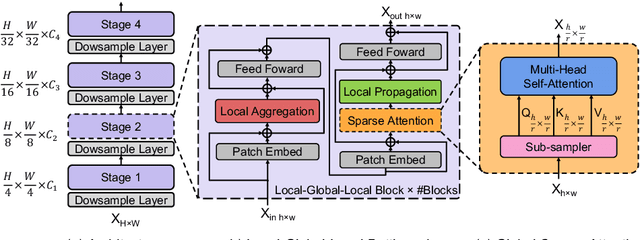
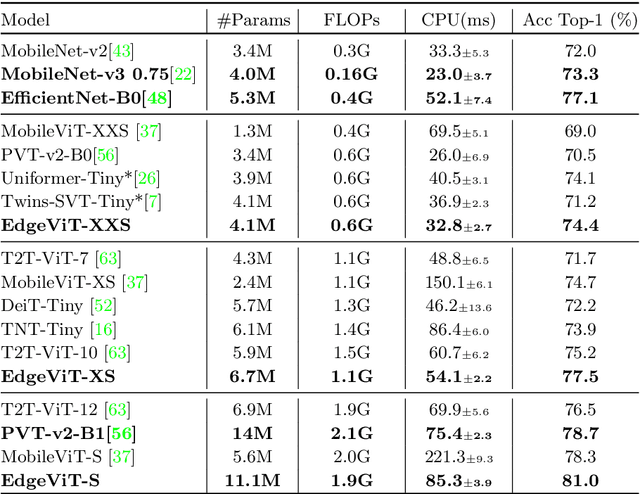
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.
Finding Directions in GAN's Latent Space for Neural Face Reenactment
Jan 31, 2022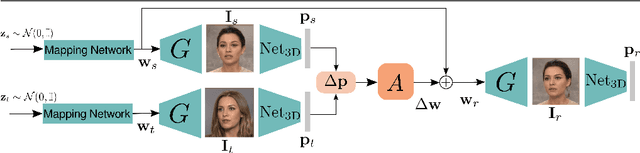
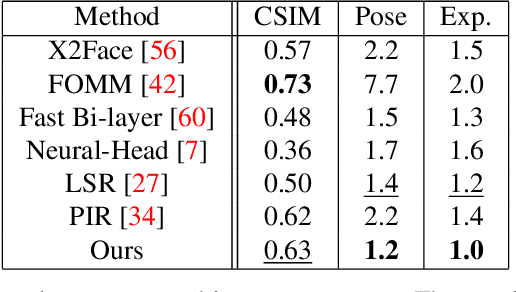

This paper is on face/head reenactment where the goal is to transfer the facial pose (3D head orientation and expression) of a target face to a source face. Previous methods focus on learning embedding networks for identity and pose disentanglement which proves to be a rather hard task, degrading the quality of the generated images. We take a different approach, bypassing the training of such networks, by using (fine-tuned) pre-trained GANs which have been shown capable of producing high-quality facial images. Because GANs are characterized by weak controllability, the core of our approach is a method to discover which directions in latent GAN space are responsible for controlling facial pose and expression variations. We present a simple pipeline to learn such directions with the aid of a 3D shape model which, by construction, already captures disentangled directions for facial pose, identity and expression. Moreover, we show that by embedding real images in the GAN latent space, our method can be successfully used for the reenactment of real-world faces. Our method features several favorable properties including using a single source image (one-shot) and enabling cross-person reenactment. Our qualitative and quantitative results show that our approach often produces reenacted faces of significantly higher quality than those produced by state-of-the-art methods for the standard benchmarks of VoxCeleb1 & 2.
S3: Supervised Self-supervised Learning under Label Noise
Nov 22, 2021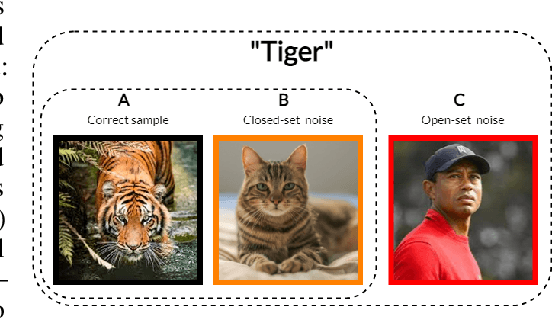
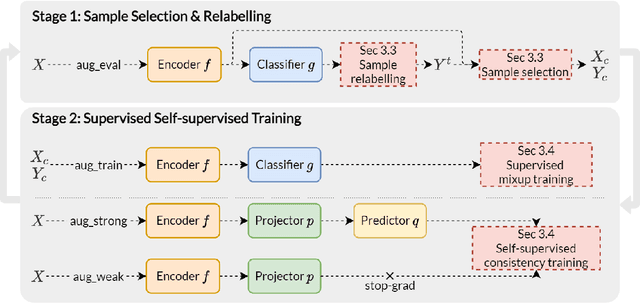

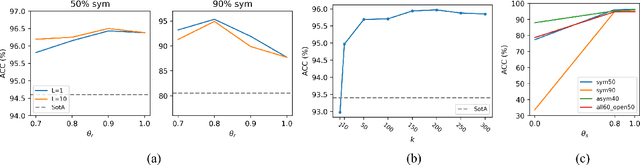
Despite the large progress in supervised learning with Neural Networks, there are significant challenges in obtaining high-quality, large-scale and accurately labeled datasets. In this context, in this paper we address the problem of classification in the presence of label noise and more specifically, both close-set and open-set label noise, that is when the true label of a sample may, or may not belong to the set of the given labels. In the heart of our method is a sample selection mechanism that relies on the consistency between the annotated label of a sample and the distribution of the labels in its neighborhood in the feature space; a relabeling mechanism that relies on the confidence of the classifier across subsequent iterations; and a training strategy that trains the encoder both with a self-consistency loss and the classifier-encoder with the cross-entropy loss on the selected samples alone. Without bells and whistles, such as co-training so as to reduce the self-confirmation bias, and with robustness with respect to settings of its few hyper-parameters, our method significantly surpasses previous methods on both CIFAR10/CIFAR100 with artificial noise and real-world noisy datasets such as WebVision and ANIMAL-10N.