 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight lower bounds for Dynamic Time Warping
Mar 02, 2021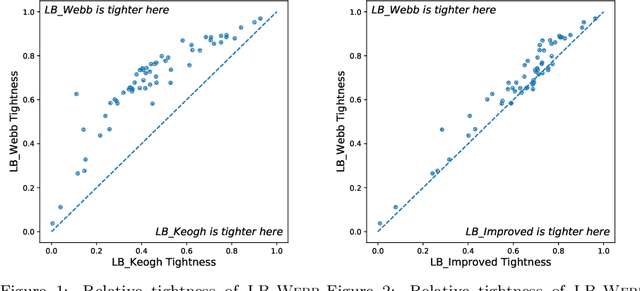
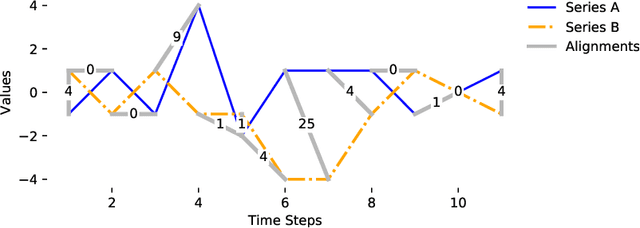
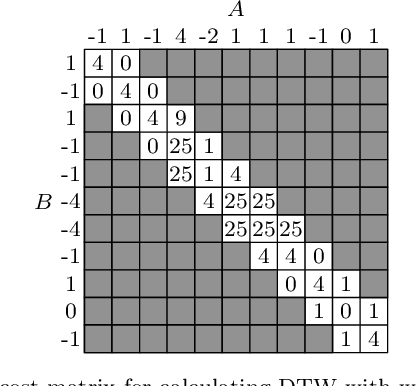
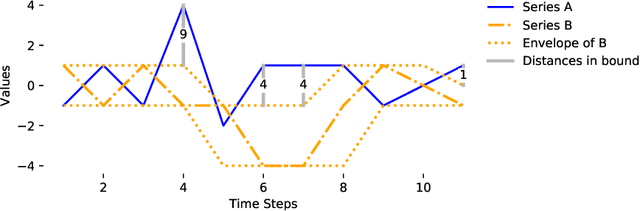
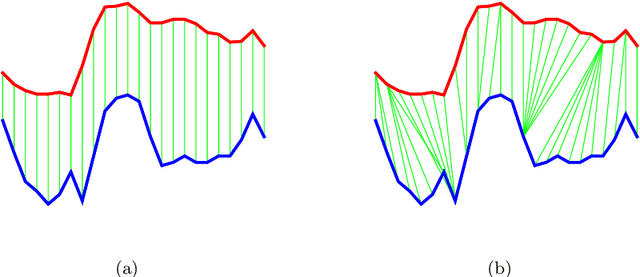
Dynamic Time Warping (DTW) is a popular similarity measure for aligning and comparing time series. Due to DTW's high computation time, lower bounds are often employed to screen poor matches. Many alternative lower bounds have been proposed, providing a range of different trade-offs between tightness and computational efficiency. LB Keogh provides a useful trade-off in many applications. Two recent lower bounds, LB Improved and LB Enhanced, are substantially tighter than LB Keogh. All three have the same worst case computational complexity - linear with respect to series length and constant with respect to window size. We present four new DTW lower bounds in the same complexity class. LB Petitjean is substantially tighter than LB Improved, with only modest additional computational overhead. LB Webb is more efficient than LB Improved, while often providing a tighter bound. LB Webb is always tighter than LB Keogh. The parameter free LB Webb is usually tighter than LB Enhanced. A parameterized variant, LB Webb Enhanced, is always tighter than LB Enhanced. A further variant, LB Webb*, is useful for some constrained distance functions. In extensive experiments, LB Webb proves to be very effective for nearest neighbor search.
* 26 pages, 23 figures, expanded version of a paper accepted for publication in Pattern Recognition. This revision fixed minor typos in the two algorithms
Elastic Similarity Measures for Multivariate Time Series Classification
Feb 20, 2021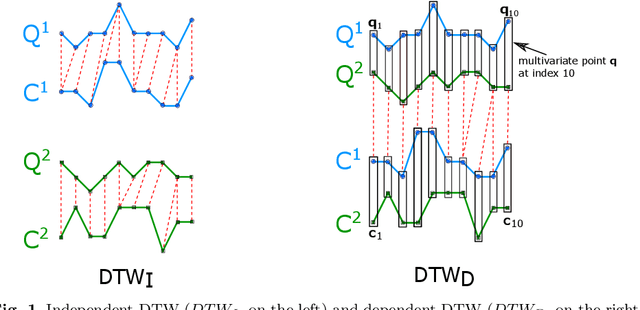
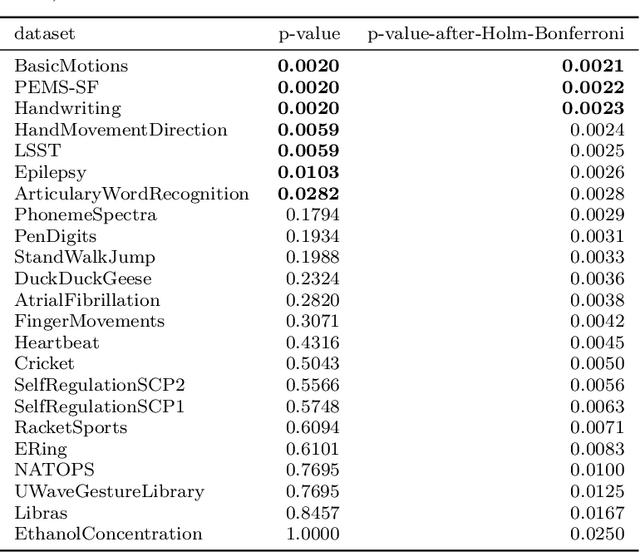

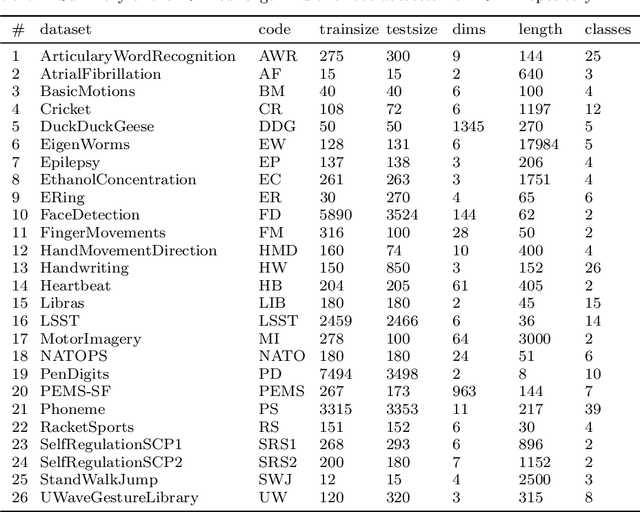
Elastic similarity measures are a class of similarity measures specifically designed to work with time series data. When scoring the similarity between two time series, they allow points that do not correspond in timestamps to be aligned. This can compensate for misalignments in the time axis of time series data, and for similar processes that proceed at variable and differing paces. Elastic similarity measures are widely used in machine learning tasks such as classification, clustering and outlier detection when using time series data. There is a multitude of research on various univariate elastic similarity measures. However, except for multivariate versions of the well known Dynamic Time Warping (DTW) there is a lack of work to generalise other similarity measures for multivariate cases. This paper adapts two existing strategies used in multivariate DTW, namely, Independent and Dependent DTW, to several commonly used elastic similarity measures. Using 23 datasets from the University of East Anglia (UEA) multivariate archive, for nearest neighbour classification, we demonstrate that each measure outperforms all others on at least one dataset and that there are datasets for which either the dependent versions of all measures are more accurate than their independent counterparts or vice versa. This latter finding suggests that these differences arise from a fundamental property of the data. We also show that an ensemble of such nearest neighbour classifiers is highly competitive with other state-of-the-art multivariate time series classifiers.
Early Abandoning and Pruning for Elastic Distances
Feb 10, 2021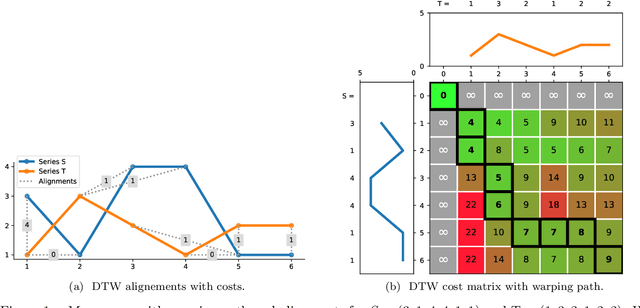
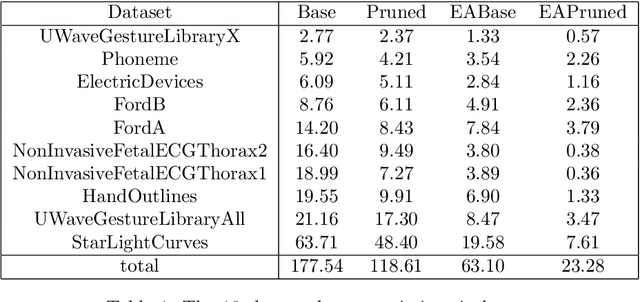
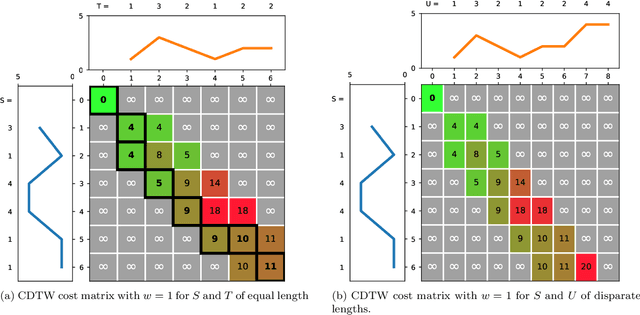
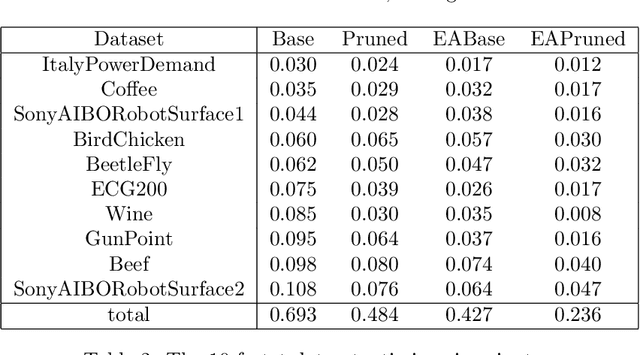
Elastic distances are key tools for time series analysis. Straightforward implementations require O(n2)space and time complexities, preventing many applications from scaling to long series. Much work hasbeen devoted in speeding up these applications, mostly with the development of lower bounds, allowing to avoid costly distance computations when a given threshold is exceeded. This threshold also allows to early abandon the computation of the distance itself. Another approach, developed for DTW, is to prune parts of the computation. All these techniques are orthogonal to each other. In this work, we develop a new generic strategy, "EAPruned", that tightly integrates pruning with early abandoning. We apply it to DTW, CDTW, WDTW, ERP, MSM and TWE, showing substantial speedup in NN1-like scenarios. Pruning also shows substantial speedup for some distances, benefiting applications such as clustering where all pairwise distances are required and hence early abandoning is not applicable. We release our implementation as part of a new C++ library for time series classification, along with easy to usePython/Numpy bindings.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
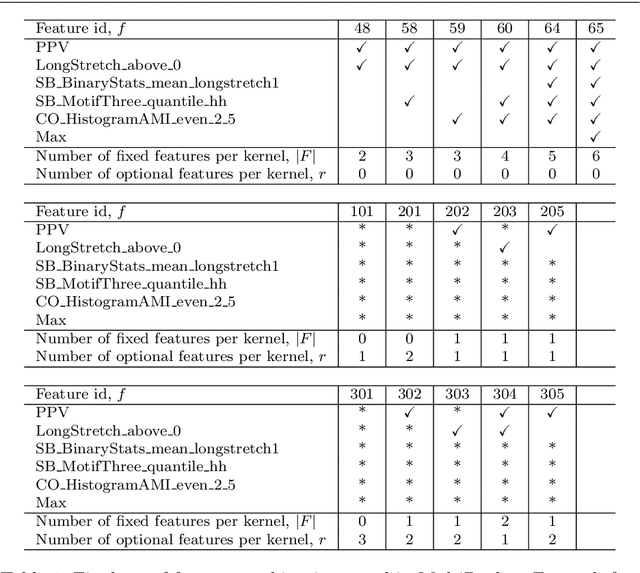
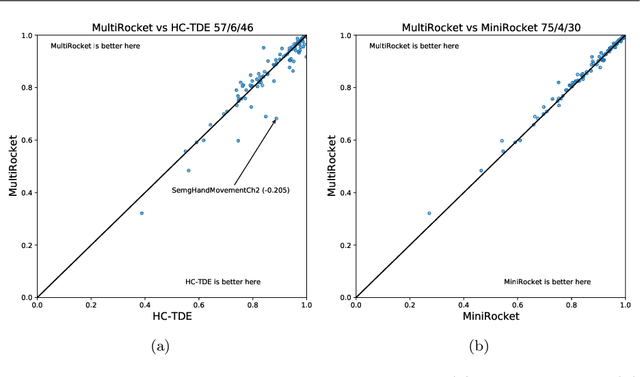

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020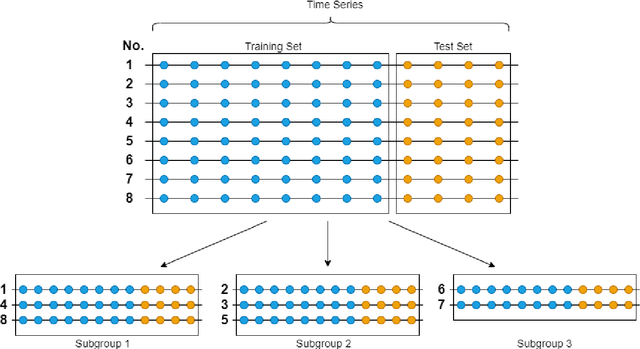

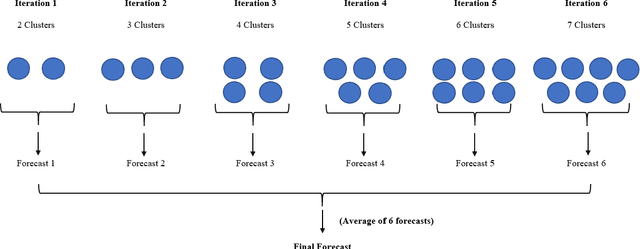
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
MINIROCKET: A Very Fast (Almost) Deterministic Transform for Time Series Classification
Dec 16, 2020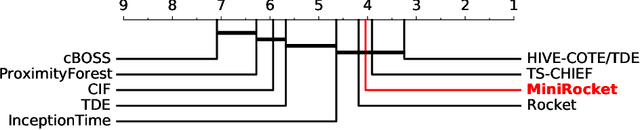

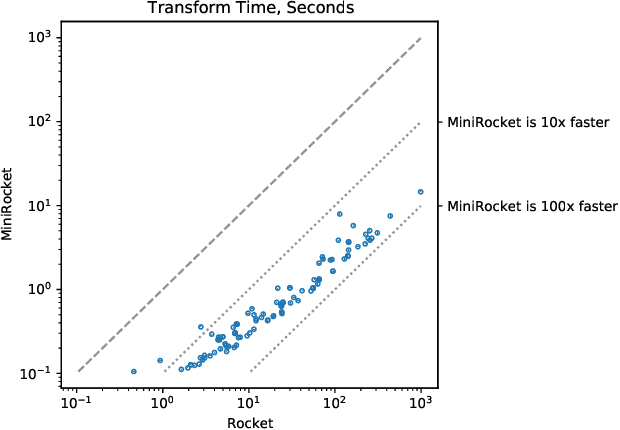
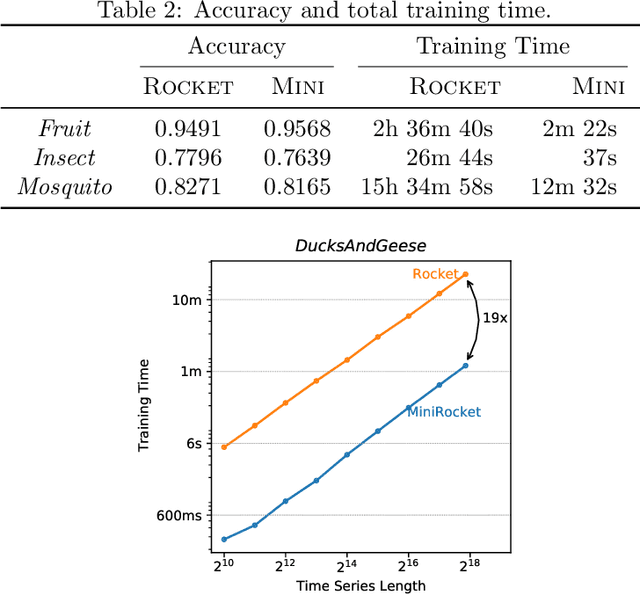
Until recently, the most accurate methods for time series classification were limited by high computational complexity. ROCKET achieves state-of-the-art accuracy with a fraction of the computational expense of most existing methods by transforming input time series using random convolutional kernels, and using the transformed features to train a linear classifier. We reformulate ROCKET into a new method, MINIROCKET, making it up to 75 times faster on larger datasets, and making it almost deterministic (and optionally, with additional computational expense, fully deterministic), while maintaining essentially the same accuracy. Using this method, it is possible to train and test a classifier on all of 109 datasets from the UCR archive to state-of-the-art accuracy in less than 10 minutes. MINIROCKET is significantly faster than any other method of comparable accuracy (including ROCKET), and significantly more accurate than any other method of even roughly-similar computational expense. As such, we suggest that MINIROCKET should now be considered and used as the default variant of ROCKET.
Discriminative, Generative and Self-Supervised Approaches for Target-Agnostic Learning
Nov 12, 2020
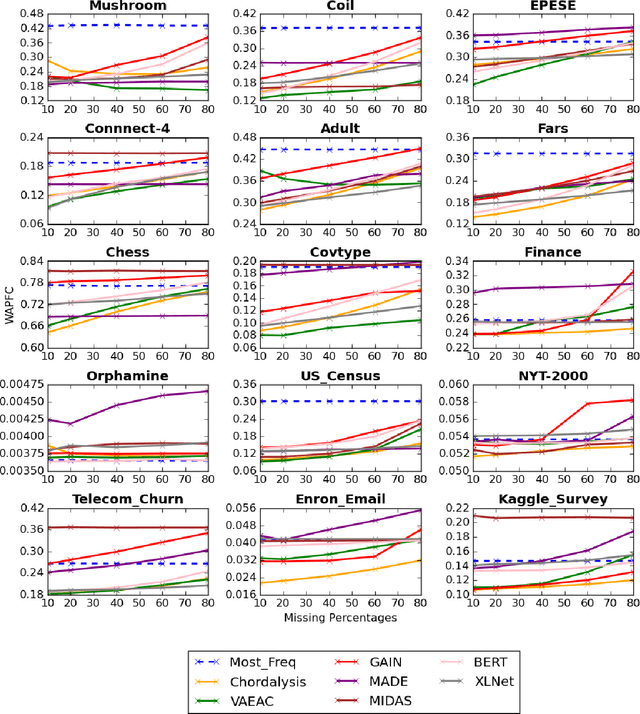
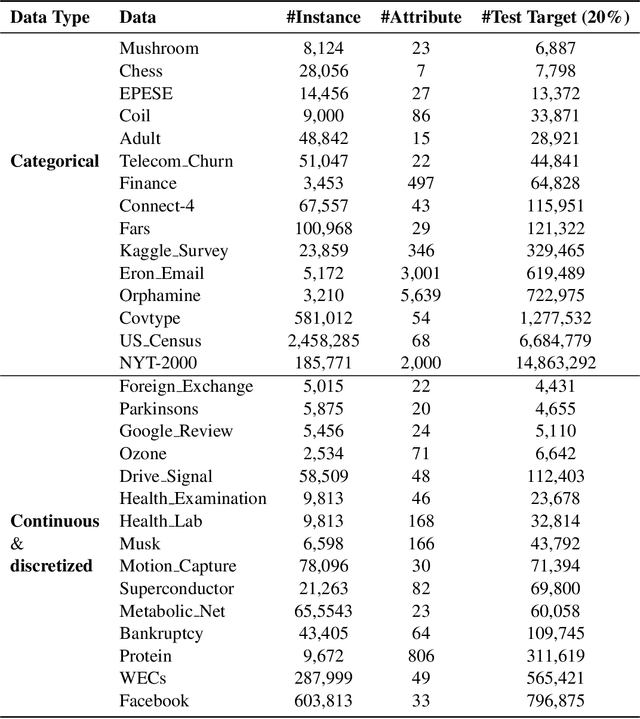
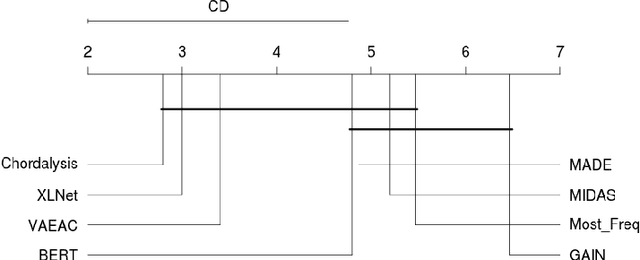
Supervised learning, characterized by both discriminative and generative learning, seeks to predict the values of single (or sometimes multiple) predefined target attributes based on a predefined set of predictor attributes. For applications where the information available and predictions to be made may vary from instance to instance, we propose the task of target-agnostic learning where arbitrary disjoint sets of attributes can be used for each of predictors and targets for each to-be-predicted instance. For this task, we survey a wide range of techniques available for handling missing values, self-supervised training and pseudo-likelihood training, and adapt them to a suite of algorithms that are suitable for the task. We conduct extensive experiments on this suite of algorithms on a large collection of categorical, continuous and discretized datasets, and report their performance in terms of both classification and regression errors. We also report the training and prediction time of these algorithms when handling large-scale datasets. Both generative and self-supervised learning models are shown to perform well at the task, although their characteristics towards the different types of data are quite different. Nevertheless, our derived theorem for the pseudo-likelihood theory also shows that they are related for inferring a joint distribution model based on the pseudo-likelihood training.
A Strong Baseline for Weekly Time Series Forecasting
Oct 16, 2020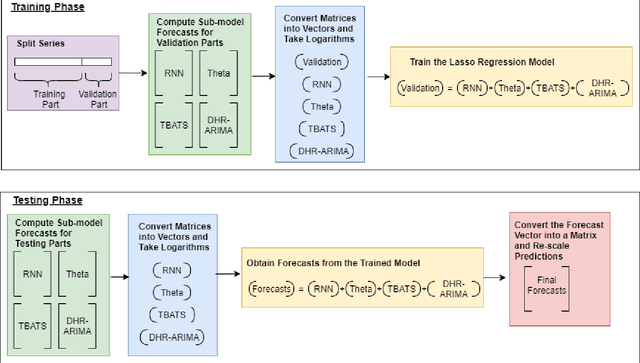

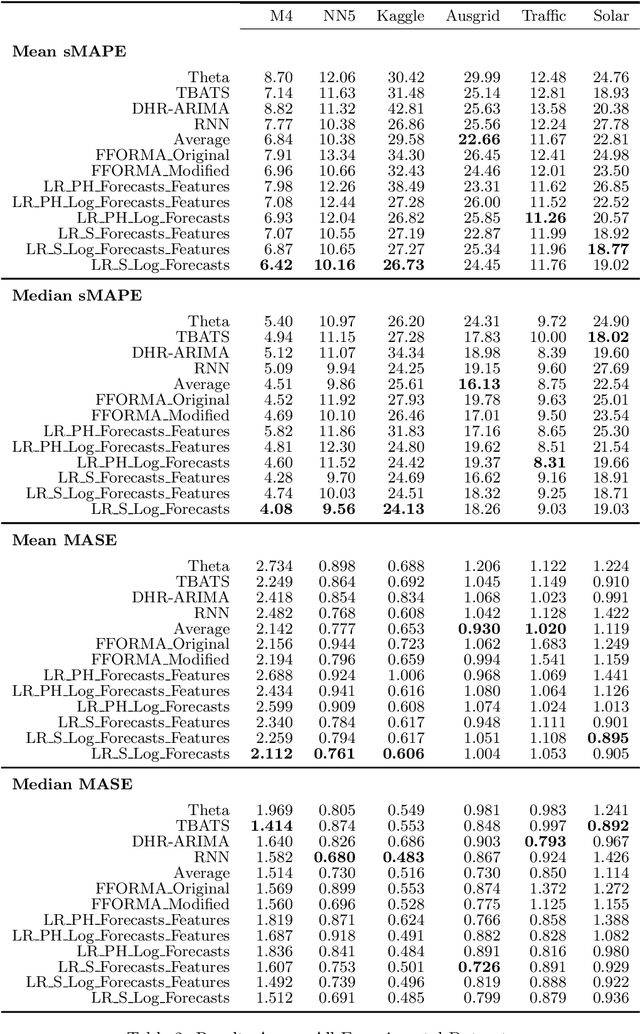
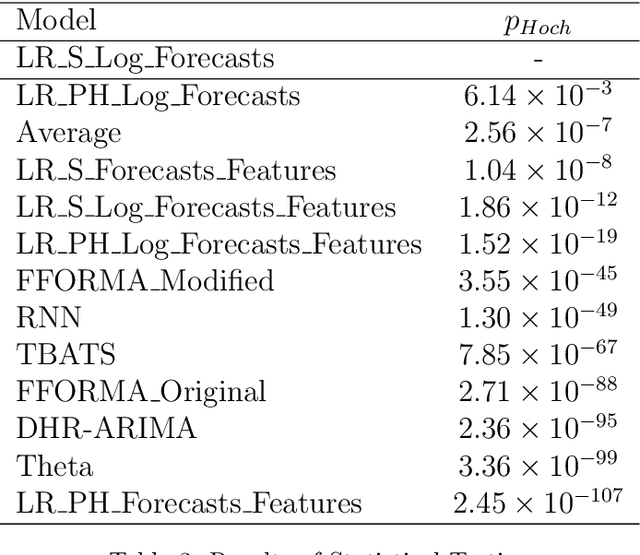
Many businesses and industries require accurate forecasts for weekly time series nowadays. The forecasting literature however does not currently provide easy-to-use, automatic, reproducible and accurate approaches dedicated to this task. We propose a forecasting method that can be used as a strong baseline in this domain, leveraging state-of-the-art forecasting techniques, forecast combination, and global modelling. Our approach uses four base forecasting models specifically suitable for forecasting weekly data: a global Recurrent Neural Network model, Theta, Trigonometric Box-Cox ARMA Trend Seasonal (TBATS), and Dynamic Harmonic Regression ARIMA (DHR-ARIMA). Those are then optimally combined using a lasso regression stacking approach. We evaluate the performance of our method against a set of state-of-the-art weekly forecasting models on six datasets. Across four evaluation metrics, we show that our method consistently outperforms the benchmark methods by a considerable margin with statistical significance. In particular, our model can produce the most accurate forecasts, in terms of mean sMAPE, for the M4 weekly dataset.
Early Abandoning PrunedDTW and its application to similarity search
Oct 11, 2020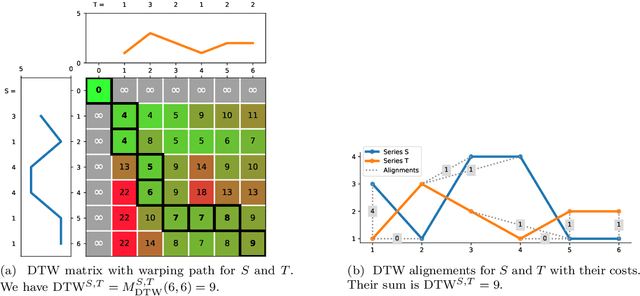

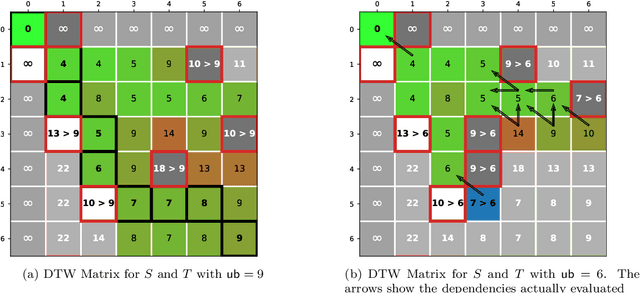
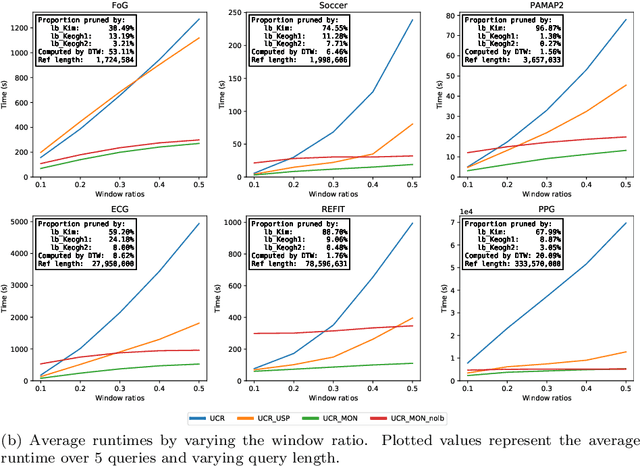
The Dynamic Time Warping ("DTW") distance is widely used in time series analysis, be it for classification, clustering or similarity search. However, its quadratic time complexity prevents it from scaling. Strategies, based on early abandoning DTW or skipping its computation altogether thanks to lower bounds, have been developed for certain use cases such as nearest neighbour search. But vectorization and approximation aside, no advance was made on DTW itself until recently with the introduction of PrunedDTW. This algorithm, able to prune unpromising alignments, was later fitted with early abandoning. We present a new version of PrunedDTW, "EAPrunedDTW", designed with early abandon in mind from the start, and able to early abandon faster than before. We show that EAPrunedDTW significantly improves the computation time of similarity search in the UCR Suite, and renders lower bounds dispensable.
Time Series Regression
Jun 23, 2020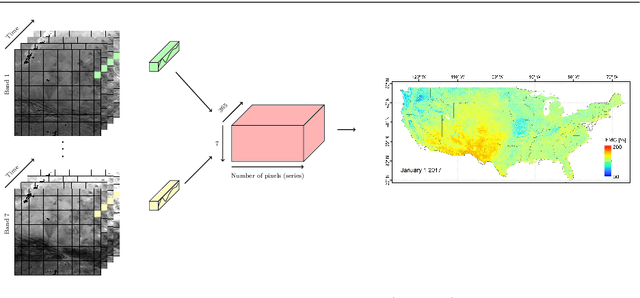
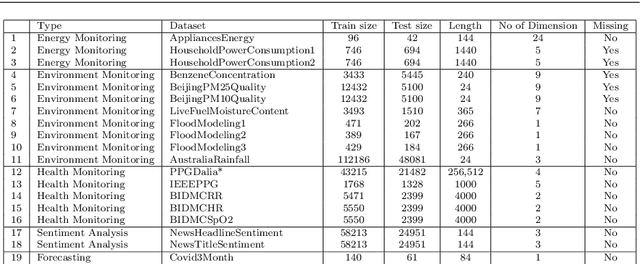
This paper introduces Time Series Regression (TSR): a little-studied task of which the aim is to learn the relationship between a time series and a continuous target variable. In contrast to time series classification (TSC), which predicts a categorical class label, TSR predicts a numerical value. This task generalizes forecasting, relaxing the requirement that the value predicted be a future value of the input series or primarily depend on more recent values. In this paper, we motivate and introduce this task, and benchmark possible solutions to tackling it on a novel archive of 19 TSR datasets which we have assembled. Our results show that the state-of-the-art TSC model Rocket, when adapted for regression, performs the best overall compared to other TSC models and state-of-the-art machine learning (ML) models such as XGBoost, Random Forest and Support Vector Regression.More importantly, we show that much research is needed in this field to improve the accuracy of ML models.