 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
AtteSTNet -- An attention and subword tokenization based approach for code-switched Hindi-English hate speech detection
Dec 10, 2021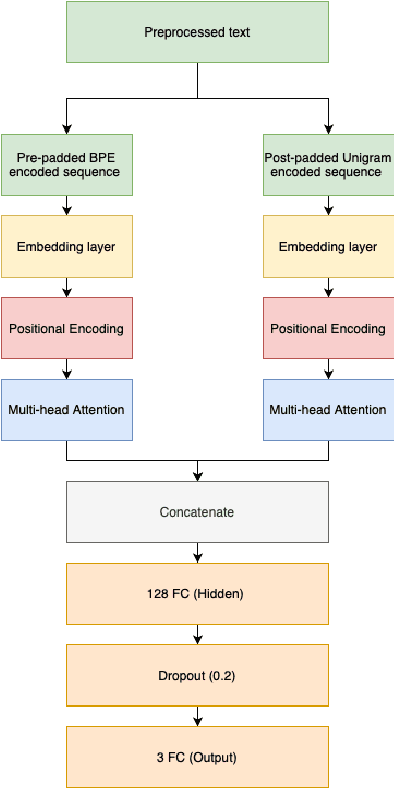
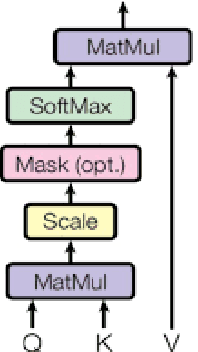
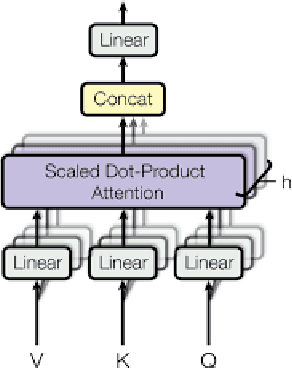
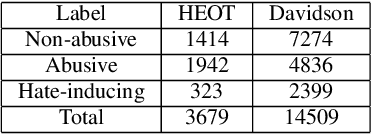
Recent advancements in technology have led to a boost in social media usage which has ultimately led to large amounts of user-generated data which also includes hateful and offensive speech. The language used in social media is often a combination of English and the native language in the region. In India, Hindi is used predominantly and is often code-switched with English, giving rise to the Hinglish (Hindi+English) language. Various approaches have been made in the past to classify the code-mixed Hinglish hate speech using different machine learning and deep learning-based techniques. However, these techniques make use of recurrence on convolution mechanisms which are computationally expensive and have high memory requirements. Past techniques also make use of complex data processing making the existing techniques very complex and non-sustainable to change in data. We propose a much simpler approach which is not only at par with these complex networks but also exceeds performance with the use of subword tokenization algorithms like BPE and Unigram along with multi-head attention-based technique giving an accuracy of 87.41% and F1 score of 0.851 on standard datasets. Efficient use of BPE and Unigram algorithms help handle the non-conventional Hinglish vocabulary making our technique simple, efficient and sustainable to use in the real world.
Segmented Federated Learning for Adaptive Intrusion Detection System
Jul 02, 2021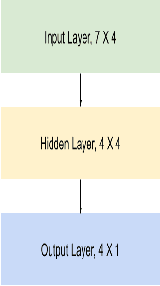

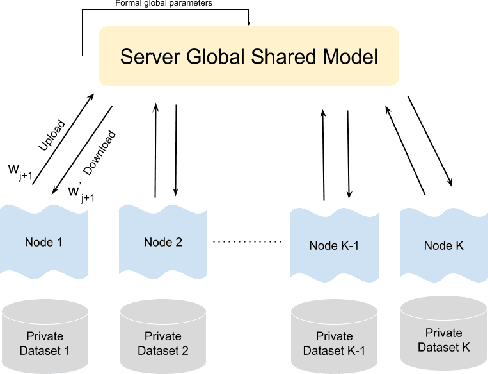
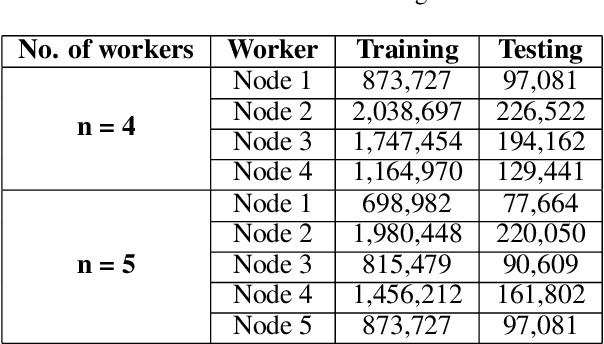
Cyberattacks are a major issues and it causes organizations great financial, and reputation harm. However, due to various factors, the current network intrusion detection systems (NIDS) seem to be insufficent. Predominant NIDS identifies Cyberattacks through a handcrafted dataset of rules. Although the recent applications of machine learning and deep learning have alleviated the enormous effort in NIDS, the security of network data has always been a prime concern. However, to encounter the security problem and enable sharing among organizations, Federated Learning (FL) scheme is employed. Although the current FL systems have been successful, a network's data distribution does not always fit into a single global model as in FL. Thus, in such cases, having a single global model in FL is no feasible. In this paper, we propose a Segmented-Federated Learning (Segmented-FL) learning scheme for a more efficient NIDS. The Segmented-FL approach employs periodic local model evaluation based on which the segmentation occurs. We aim to bring similar network environments to the same group. Further, the Segmented-FL system is coupled with a weighted aggregation of local model parameters based on the number of data samples a worker possesses to further augment the performance. The improved performance by our system as compared to the FL and centralized systems on standard dataset further validates our system and makes a strong case for extending our technique across various tasks. The solution finds its application in organizations that want to collaboratively learn on diverse network environments and protect the privacy of individual datasets.