 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving video retrieval using multilingual knowledge transfer
Aug 28, 2022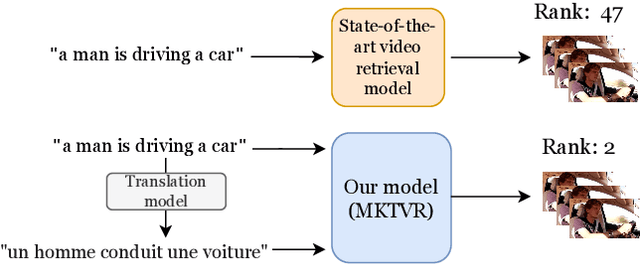
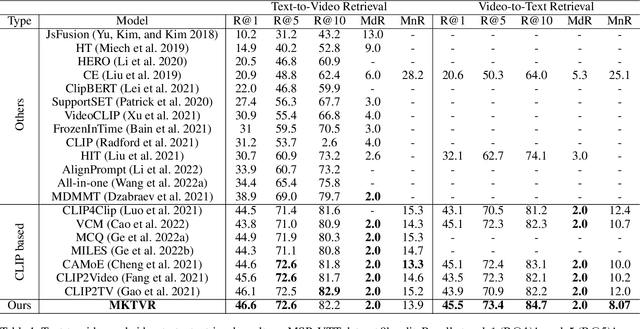
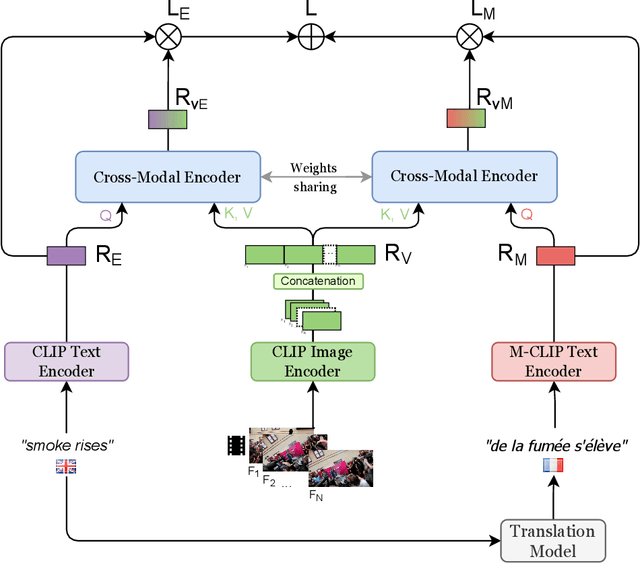
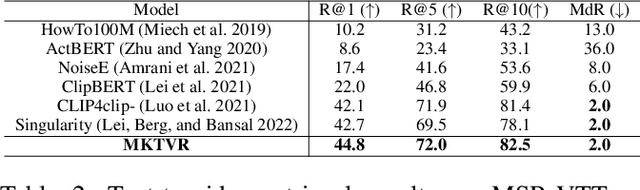
Video retrieval has seen tremendous progress with the development of vision-language models. However, further improving these models require additional labelled data which is a huge manual effort. In this paper, we propose a framework MKTVR, that utilizes knowledge transfer from a multilingual model to boost the performance of video retrieval. We first use state-of-the-art machine translation models to construct pseudo ground-truth multilingual video-text pairs. We then use this data to learn a video-text representation where English and non-English text queries are represented in a common embedding space based on pretrained multilingual models. We evaluate our proposed approach on four English video retrieval datasets such as MSRVTT, MSVD, DiDeMo and Charades. Experimental results demonstrate that our approach achieves state-of-the-art results on all datasets outperforming previous models. Finally, we also evaluate our model on a multilingual video-retrieval dataset encompassing six languages and show that our model outperforms previous multilingual video retrieval models in a zero-shot setting.
Object State Change Classification in Egocentric Videos using the Divided Space-Time Attention Mechanism
Jul 24, 2022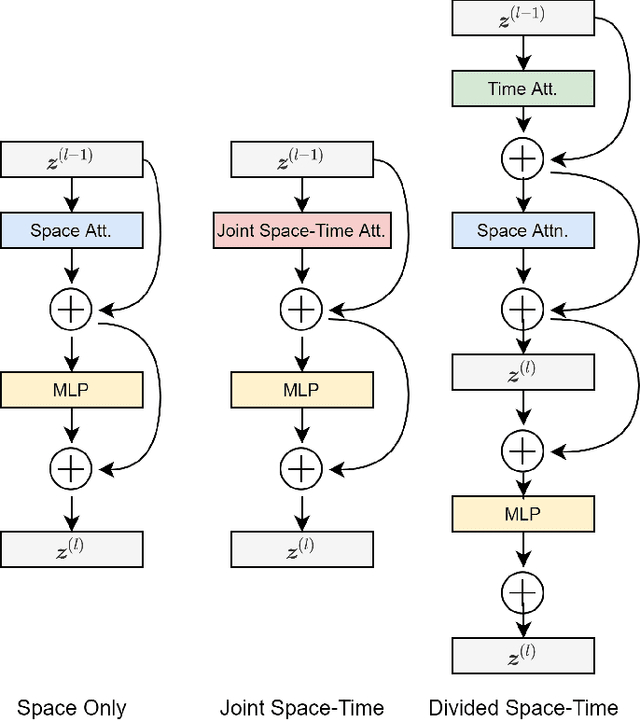
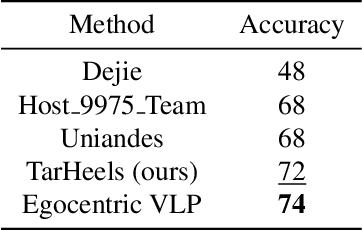
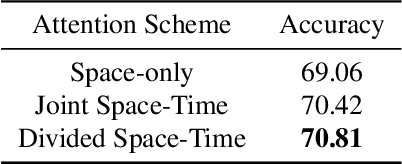

This report describes our submission called "TarHeels" for the Ego4D: Object State Change Classification Challenge. We use a transformer-based video recognition model and leverage the Divided Space-Time Attention mechanism for classifying object state change in egocentric videos. Our submission achieves the second-best performance in the challenge. Furthermore, we perform an ablation study to show that identifying object state change in egocentric videos requires temporal modeling ability. Lastly, we present several positive and negative examples to visualize our model's predictions. The code is publicly available at: https://github.com/md-mohaiminul/ObjectStateChange
Learning to Retrieve Videos by Asking Questions
May 13, 2022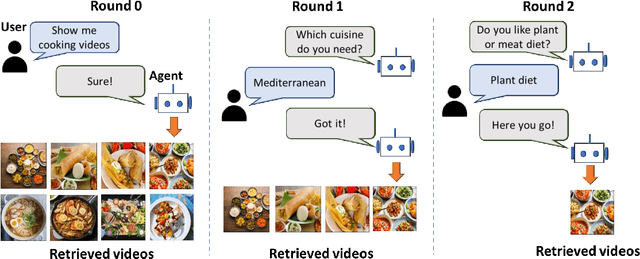

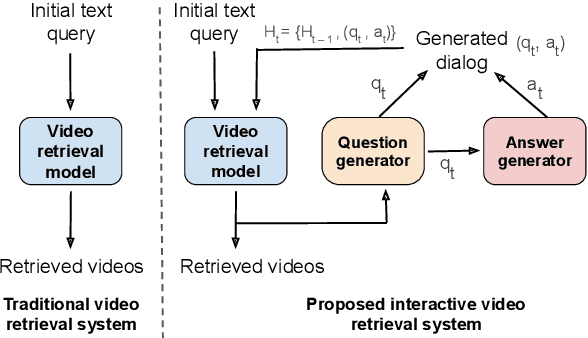
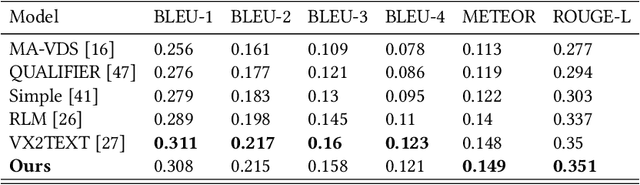
The majority of traditional text-to-video retrieval systems operate in static environments, i.e., there is no interaction between the user and the agent beyond the initial textual query provided by the user. This can be suboptimal if the initial query has ambiguities, which would lead to many falsely retrieved videos. To overcome this limitation, we propose a novel framework for Video Retrieval using Dialog (ViReD), which enables the user to interact with an AI agent via multiple rounds of dialog. The key contribution of our framework is a novel multimodal question generator that learns to ask questions that maximize the subsequent video retrieval performance. Our multimodal question generator uses (i) the video candidates retrieved during the last round of interaction with the user and (ii) the text-based dialog history documenting all previous interactions, to generate questions that incorporate both visual and linguistic cues relevant to video retrieval. Furthermore, to generate maximally informative questions, we propose an Information-Guided Supervision (IGS), which guides the question generator to ask questions that would boost subsequent video retrieval accuracy. We validate the effectiveness of our interactive ViReD framework on the AVSD dataset, showing that our interactive method performs significantly better than traditional non-interactive video retrieval systems. Furthermore, we also demonstrate that our proposed approach also generalizes to the real-world settings that involve interactions with real humans, thus, demonstrating the robustness and generality of our framework
ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound
Apr 06, 2022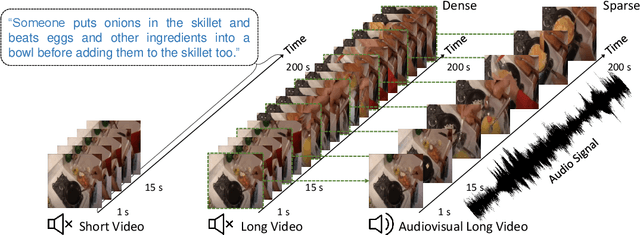
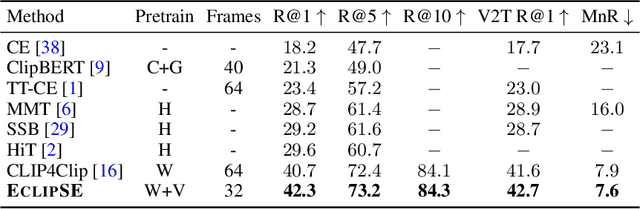
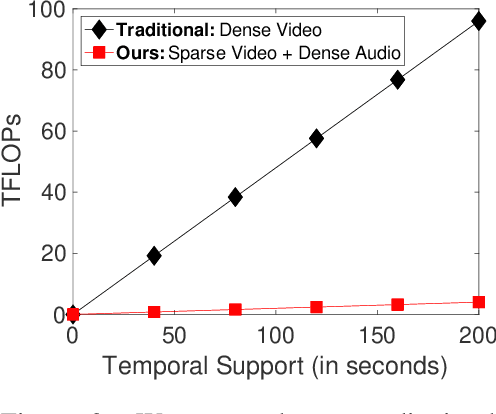
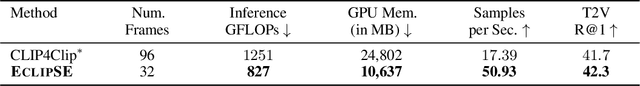
We introduce an audiovisual method for long-range text-to-video retrieval. Unlike previous approaches designed for short video retrieval (e.g., 5-15 seconds in duration), our approach aims to retrieve minute-long videos that capture complex human actions. One challenge of standard video-only approaches is the large computational cost associated with processing hundreds of densely extracted frames from such long videos. To address this issue, we propose to replace parts of the video with compact audio cues that succinctly summarize dynamic audio events and are cheap to process. Our method, named ECLIPSE (Efficient CLIP with Sound Encoding), adapts the popular CLIP model to an audiovisual video setting, by adding a unified audiovisual transformer block that captures complementary cues from the video and audio streams. In addition to being 2.92x faster and 2.34x memory-efficient than long-range video-only approaches, our method also achieves better text-to-video retrieval accuracy on several diverse long-range video datasets such as ActivityNet, QVHighlights, YouCook2, DiDeMo and Charades.
Long Movie Clip Classification with State-Space Video Models
Apr 04, 2022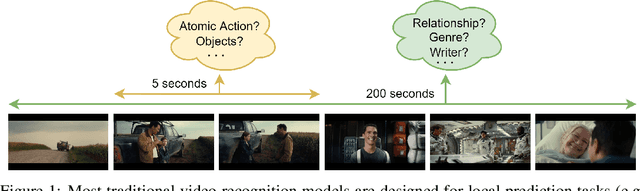
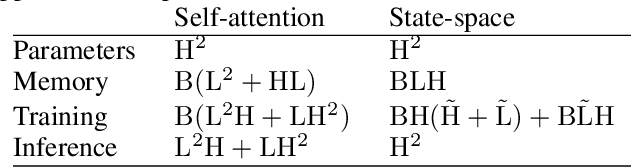
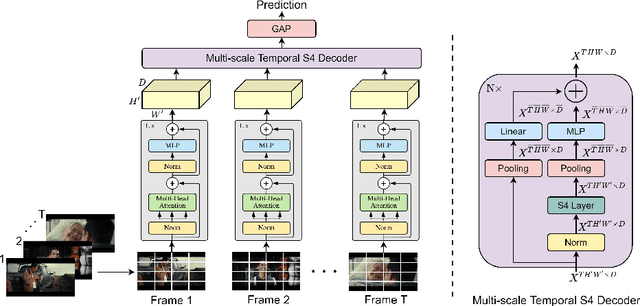

Most modern video recognition models are designed to operate on short video clips (e.g., 5-10s in length). Because of this, it is challenging to apply such models to long movie understanding tasks, which typically require sophisticated long-range temporal reasoning capabilities. The recently introduced video transformers partially address this issue by using long-range temporal self-attention. However, due to the quadratic cost of self-attention, such models are often costly and impractical to use. Instead, we propose ViS4mer, an efficient long-range video model that combines the strengths of self-attention and the recently introduced structured state-space sequence (S4) layer. Our model uses a standard Transformer encoder for short-range spatiotemporal feature extraction, and a multi-scale temporal S4 decoder for subsequent long-range temporal reasoning. By progressively reducing the spatiotemporal feature resolution and channel dimension at each decoder layer, ViS4mer learns complex long-range spatiotemporal dependencies in a video. Furthermore, ViS4mer is $2.63\times$ faster and requires $8\times$ less GPU memory than the corresponding pure self-attention-based model. Additionally, ViS4mer achieves state-of-the-art results in $7$ out of $9$ long-form movie video classification tasks on the LVU benchmark. Furthermore, we also show that our approach successfully generalizes to other domains, achieving competitive results on the Breakfast and the COIN procedural activity datasets. The code will be made publicly available.
TALLFormer: Temporal Action Localization with Long-memory Transformer
Apr 04, 2022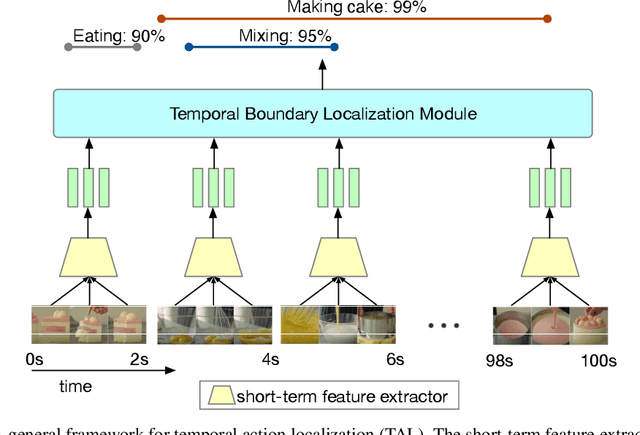
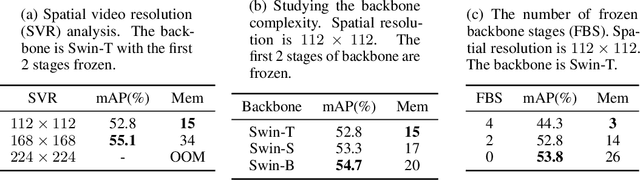
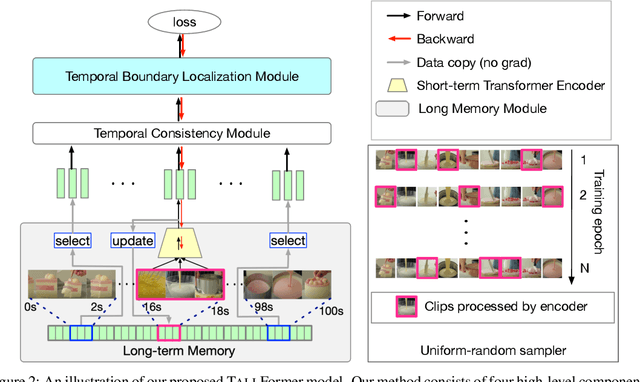
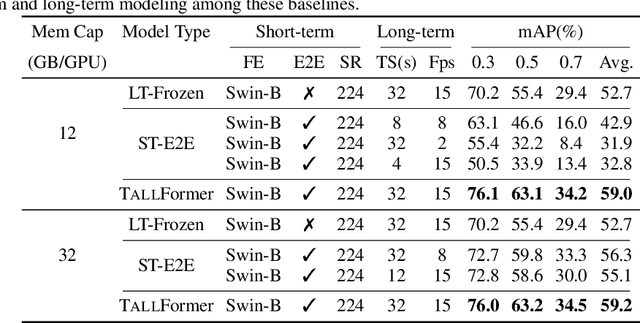
Most modern approaches in temporal action localization divide this problem into two parts: (i) short-term feature extraction and (ii) long-range temporal boundary localization. Due to the high GPU memory cost caused by processing long untrimmed videos, many methods sacrifice the representational power of the short-term feature extractor by either freezing the backbone or using a very small spatial video resolution. This issue becomes even worse with the recent video transformer models, many of which have quadratic memory complexity. To address these issues, we propose TALLFormer, a memory-efficient and end-to-end trainable Temporal Action Localization transformer with Long-term memory. Our long-term memory mechanism eliminates the need for processing hundreds of redundant video frames during each training iteration, thus, significantly reducing the GPU memory consumption and training time. These efficiency savings allow us (i) to use a powerful video transformer-based feature extractor without freezing the backbone or reducing the spatial video resolution, while (ii) also maintaining long-range temporal boundary localization capability. With only RGB frames as input and no external action recognition classifier, TALLFormer outperforms previous state-of-the-art methods by a large margin, achieving an average mAP of 59.1% on THUMOS14 and 35.6% on ActivityNet-1.3. The code will be available in https://github.com/klauscc/TALLFormer.
Learning To Recognize Procedural Activities with Distant Supervision
Jan 26, 2022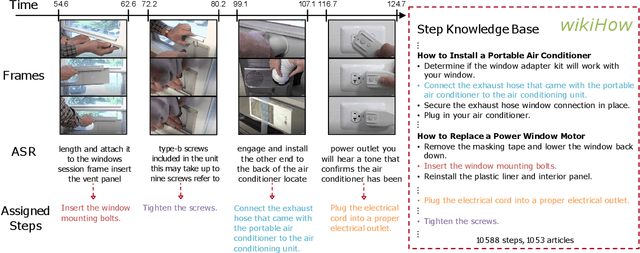

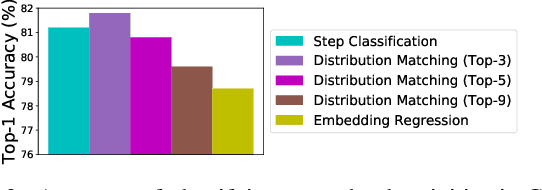

In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
Long-Short Temporal Contrastive Learning of Video Transformers
Jul 08, 2021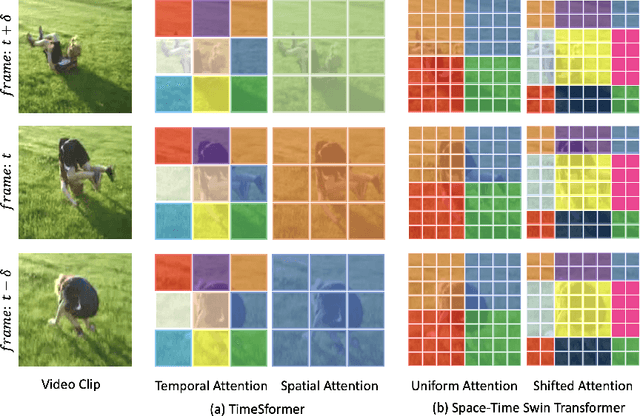

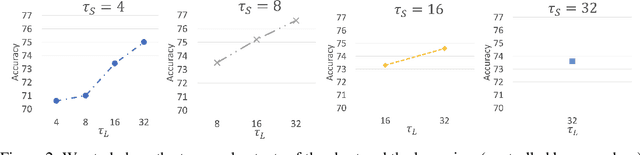
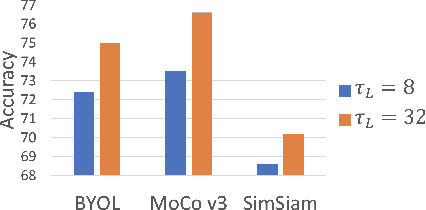
Video transformers have recently emerged as a competitive alternative to 3D CNNs for video understanding. However, due to their large number of parameters and reduced inductive biases, these models require supervised pretraining on large-scale image datasets to achieve top performance. In this paper, we empirically demonstrate that self-supervised pretraining of video transformers on video-only datasets can lead to action recognition results that are on par or better than those obtained with supervised pretraining on large-scale image datasets, even massive ones such as ImageNet-21K. Since transformer-based models are effective at capturing dependencies over extended temporal spans, we propose a simple learning procedure that forces the model to match a long-term view to a short-term view of the same video. Our approach, named Long-Short Temporal Contrastive Learning (LSTCL), enables video transformers to learn an effective clip-level representation by predicting temporal context captured from a longer temporal extent. To demonstrate the generality of our findings, we implement and validate our approach under three different self-supervised contrastive learning frameworks (MoCo v3, BYOL, SimSiam) using two distinct video-transformer architectures, including an improved variant of the Swin Transformer augmented with space-time attention. We conduct a thorough ablation study and show that LSTCL achieves competitive performance on multiple video benchmarks and represents a convincing alternative to supervised image-based pretraining.
Is Space-Time Attention All You Need for Video Understanding?
Feb 24, 2021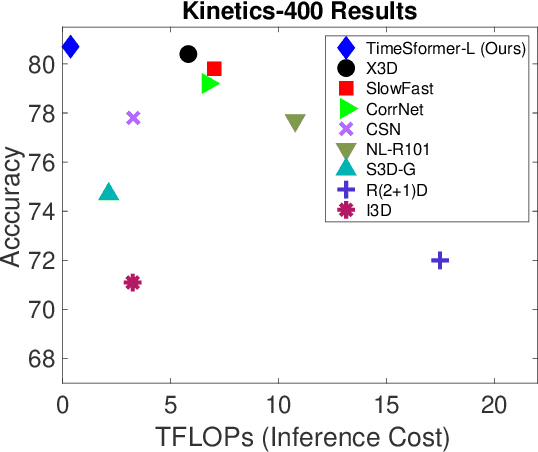
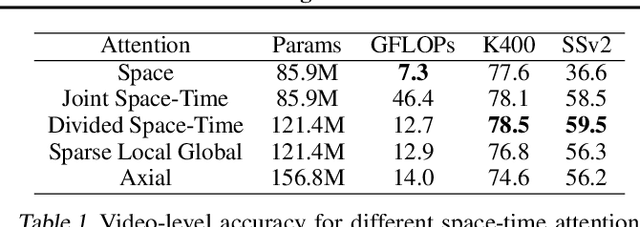
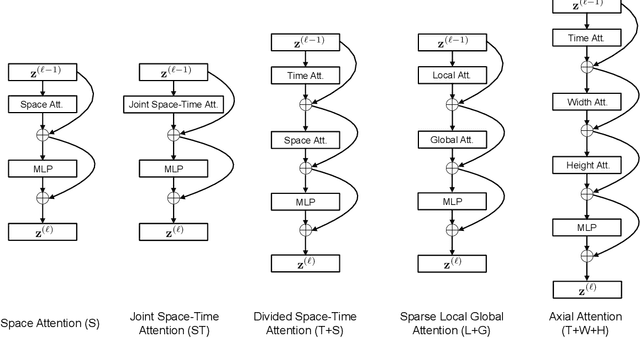
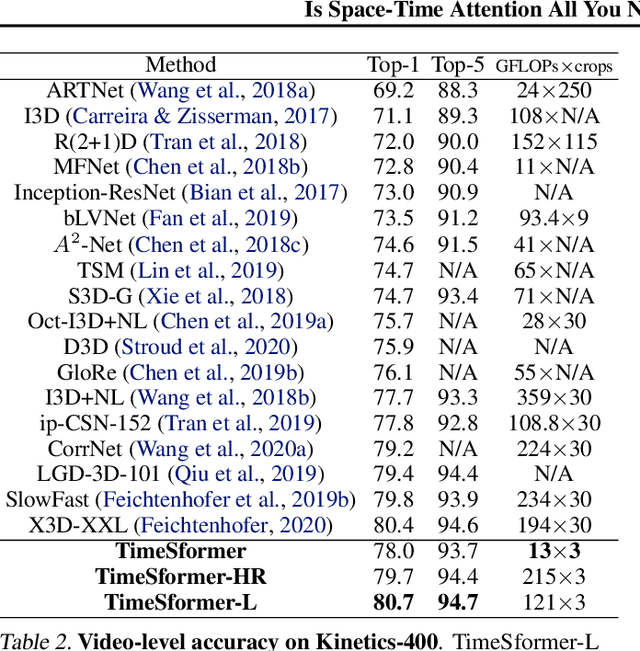
We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically different design compared to the prominent paradigm of 3D convolutional architectures for video, TimeSformer achieves state-of-the-art results on several major action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Furthermore, our model is faster to train and has higher test-time efficiency compared to competing architectures. Code and pretrained models will be made publicly available.
VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
Jan 29, 2021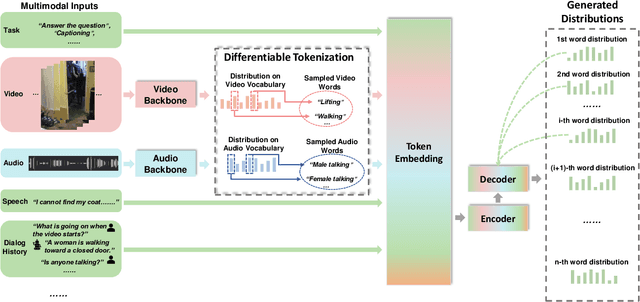



We present \textsc{Vx2Text}, a framework for text generation from multimodal inputs consisting of video plus text, speech, or audio. In order to leverage transformer networks, which have been shown to be effective at modeling language, each modality is first converted into a set of language embeddings by a learnable tokenizer. This allows our approach to perform multimodal fusion in the language space, thus eliminating the need for ad-hoc cross-modal fusion modules. To address the non-differentiability of tokenization on continuous inputs (e.g., video or audio), we utilize a relaxation scheme that enables end-to-end training. Furthermore, unlike prior encoder-only models, our network includes an autoregressive decoder to generate open-ended text from the multimodal embeddings fused by the language encoder. This renders our approach fully generative and makes it directly applicable to different "video+$x$ to text" problems without the need to design specialized network heads for each task. The proposed framework is not only conceptually simple but also remarkably effective: experiments demonstrate that our approach based on a single architecture outperforms the state-of-the-art on three video-based text-generation tasks -- captioning, question answering and audio-visual scene-aware dialog.