 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for Multivariate Time Series Tasks with Variable Input Dimensions
Mar 14, 2022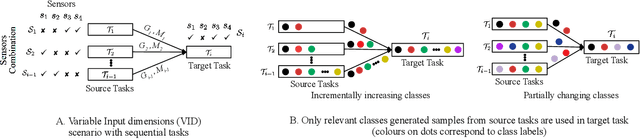
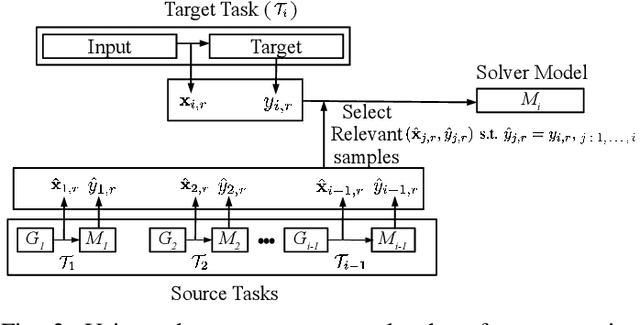
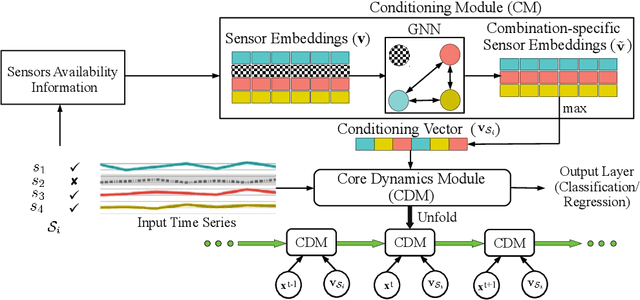
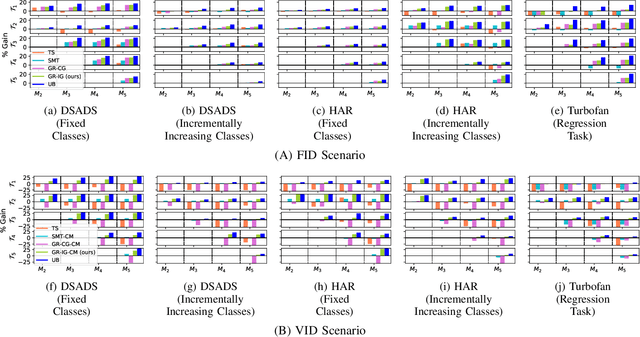
We consider a sequence of related multivariate time series learning tasks, such as predicting failures for different instances of a machine from time series of multi-sensor data, or activity recognition tasks over different individuals from multiple wearable sensors. We focus on two under-explored practical challenges arising in such settings: (i) Each task may have a different subset of sensors, i.e., providing different partial observations of the underlying 'system'. This restriction can be due to different manufacturers in the former case, and people wearing more or less measurement devices in the latter (ii) We are not allowed to store or re-access data from a task once it has been observed at the task level. This may be due to privacy considerations in the case of people, or legal restrictions placed by machine owners. Nevertheless, we would like to (a) improve performance on subsequent tasks using experience from completed tasks as well as (b) continue to perform better on past tasks, e.g., update the model and improve predictions on even the first machine after learning from subsequently observed ones. We note that existing continual learning methods do not take into account variability in input dimensions arising due to different subsets of sensors being available across tasks, and struggle to adapt to such variable input dimensions (VID) tasks. In this work, we address this shortcoming of existing methods. To this end, we learn task-specific generative models and classifiers, and use these to augment data for target tasks. Since the input dimensions across tasks vary, we propose a novel conditioning module based on graph neural networks to aid a standard recurrent neural network. We evaluate the efficacy of the proposed approach on three publicly available datasets corresponding to two activity recognition tasks (classification) and one prognostics task (regression).
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022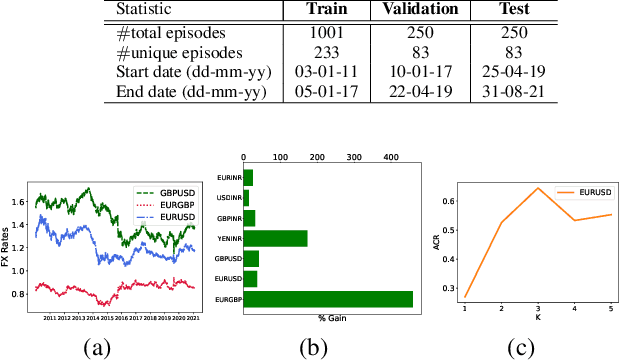
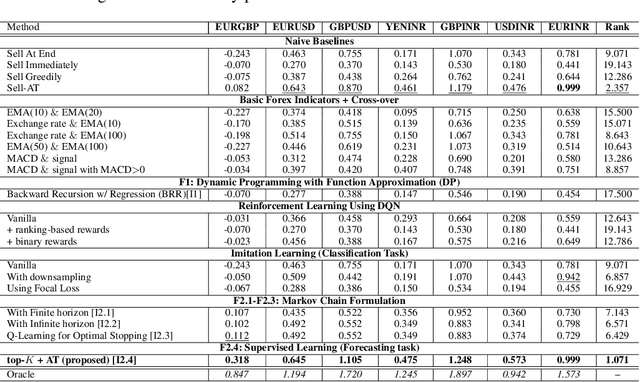
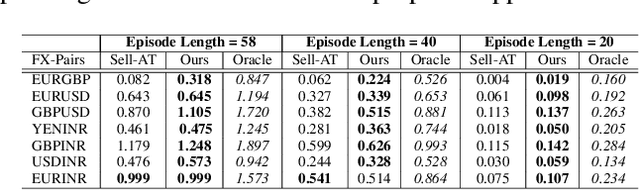
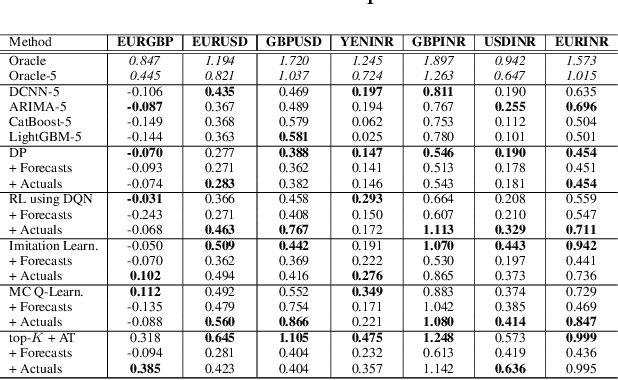
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
DRTCI: Learning Disentangled Representations for Temporal Causal Inference
Jan 20, 2022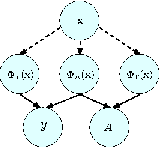
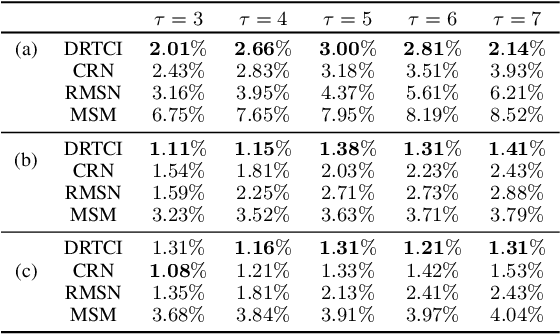
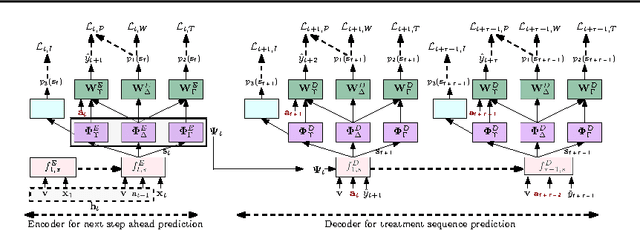
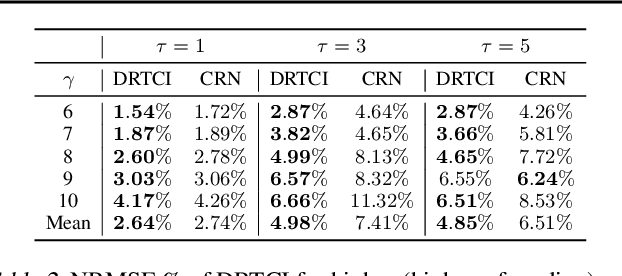
Medical professionals evaluating alternative treatment plans for a patient often encounter time varying confounders, or covariates that affect both the future treatment assignment and the patient outcome. The recently proposed Counterfactual Recurrent Network (CRN) accounts for time varying confounders by using adversarial training to balance recurrent historical representations of patient data. However, this work assumes that all time varying covariates are confounding and thus attempts to balance the full state representation. Given that the actual subset of covariates that may in fact be confounding is in general unknown, recent work on counterfactual evaluation in the static, non-temporal setting has suggested that disentangling the covariate representation into separate factors, where each either influence treatment selection, patient outcome or both can help isolate selection bias and restrict balancing efforts to factors that influence outcome, allowing the remaining factors which predict treatment without needlessly being balanced.
Solving Visual Analogies Using Neural Algorithmic Reasoning
Nov 19, 2021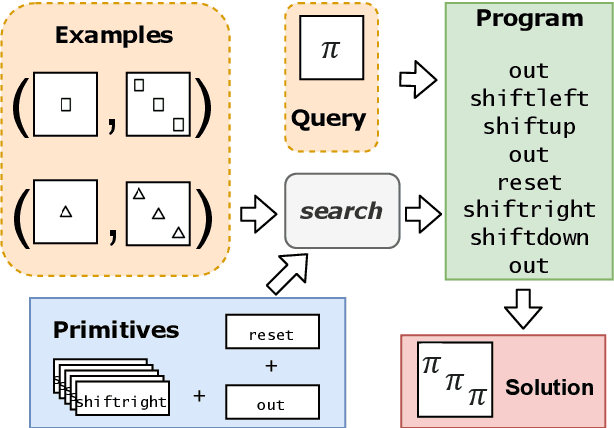

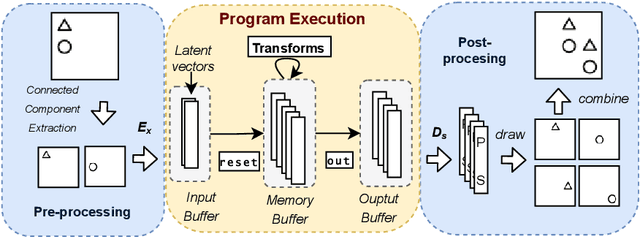
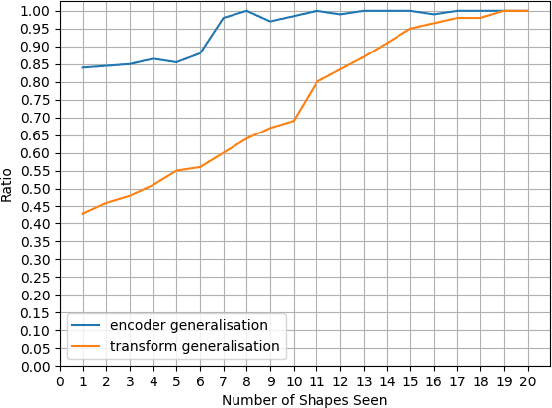
We consider a class of visual analogical reasoning problems that involve discovering the sequence of transformations by which pairs of input/output images are related, so as to analogously transform future inputs. This program synthesis task can be easily solved via symbolic search. Using a variation of the `neural analogical reasoning' approach of (Velickovic and Blundell 2021), we instead search for a sequence of elementary neural network transformations that manipulate distributed representations derived from a symbolic space, to which input images are directly encoded. We evaluate the extent to which our `neural reasoning' approach generalizes for images with unseen shapes and positions.
Forecasting Market Prices using DL with Data Augmentation and Meta-learning: ARIMA still wins!
Oct 19, 2021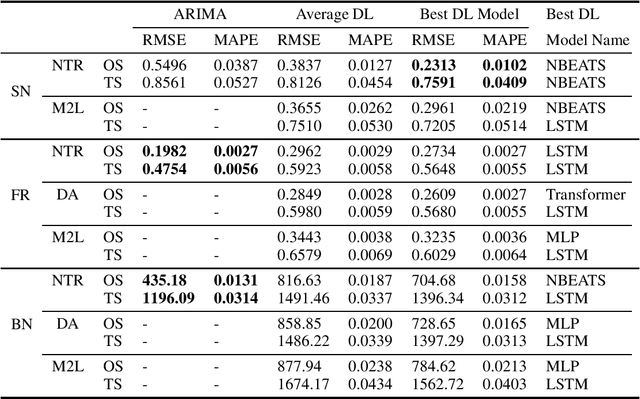
Deep-learning techniques have been successfully used for time-series forecasting and have often shown superior performance on many standard benchmark datasets as compared to traditional techniques. Here we present a comprehensive and comparative study of performance of deep-learning techniques for forecasting prices in financial markets. We benchmark state-of-the-art deep-learning baselines, such as NBeats, etc., on data from currency as well as stock markets. We also generate synthetic data using a fuzzy-logic based model of demand driven by technical rules such as moving averages, which are often used by traders. We benchmark the baseline techniques on this synthetic data as well as use it for data augmentation. We also apply gradient-based meta-learning to account for non-stationarity of financial time-series. Our extensive experiments notwithstanding, the surprising result is that the standard ARIMA models outperforms deep-learning even using data augmentation or meta-learning. We conclude by speculating as to why this might be the case.
Using Program Synthesis and Inductive Logic Programming to solve Bongard Problems
Oct 19, 2021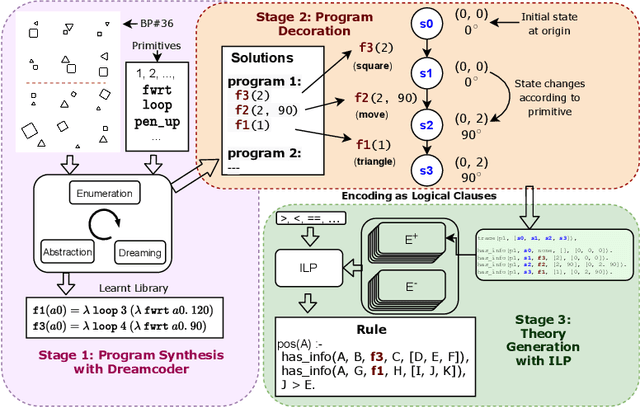

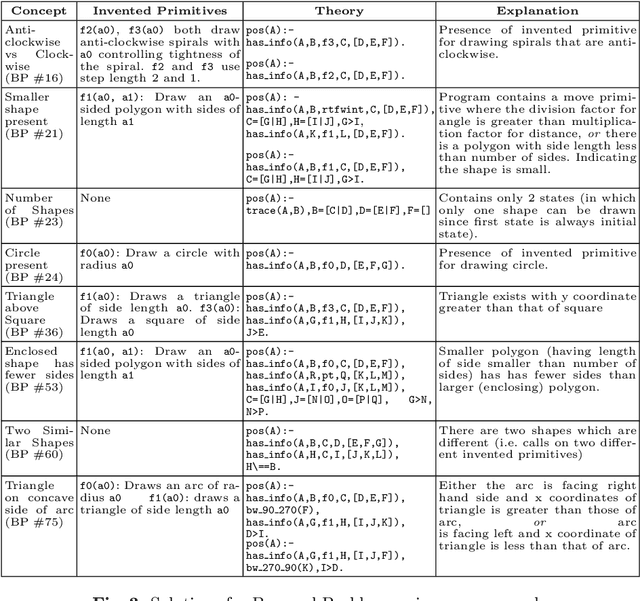
The ability to recognise and make analogies is often used as a measure or test of human intelligence. The ability to solve Bongard problems is an example of such a test. It has also been postulated that the ability to rapidly construct novel abstractions is critical to being able to solve analogical problems. Given an image, the ability to construct a program that would generate that image is one form of abstraction, as exemplified in the Dreamcoder project. In this paper, we present a preliminary examination of whether programs constructed by Dreamcoder can be used for analogical reasoning to solve certain Bongard problems. We use Dreamcoder to discover programs that generate the images in a Bongard problem and represent each of these as a sequence of state transitions. We decorate the states using positional information in an automated manner and then encode the resulting sequence into logical facts in Prolog. We use inductive logic programming (ILP), to learn an (interpretable) theory for the abstract concept involved in an instance of a Bongard problem. Experiments on synthetically created Bongard problems for concepts such as 'above/below' and 'clockwise/counterclockwise' demonstrate that our end-to-end system can solve such problems. We study the importance and completeness of each component of our approach, highlighting its current limitations and pointing to directions for improvement in our formulation as well as in elements of any Dreamcoder-like program synthesis system used for such an approach.
CAMTA: Casual Attention Model for Multi-touch Attribution
Dec 21, 2020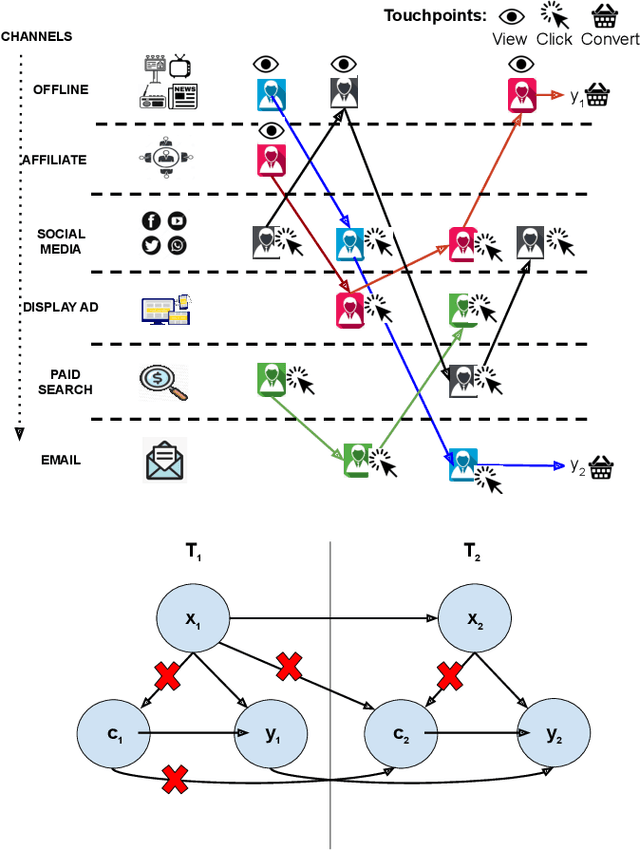
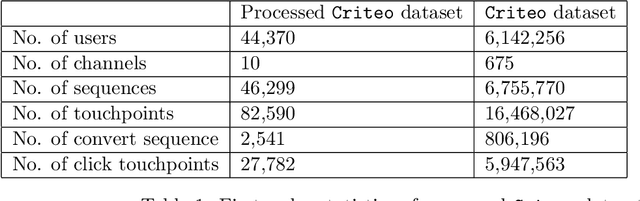
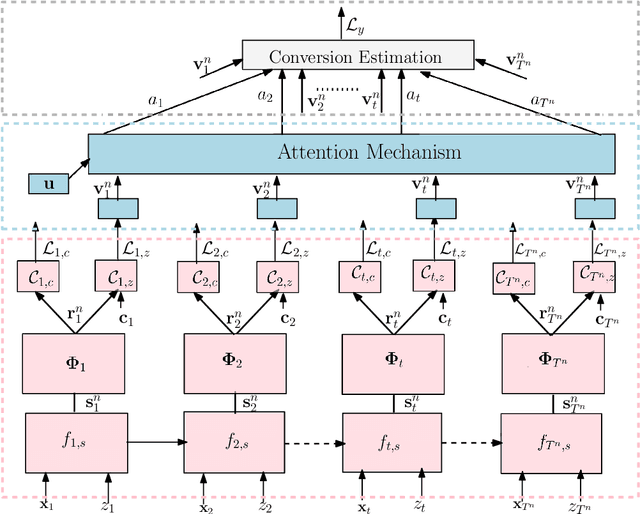
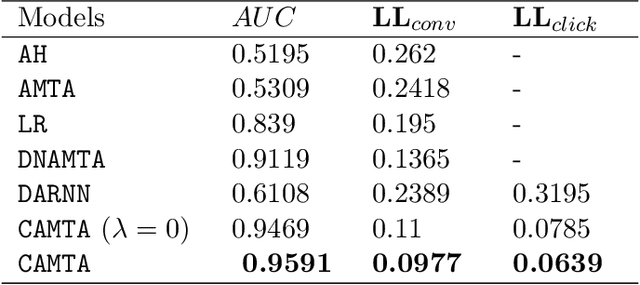
Advertising channels have evolved from conventional print media, billboards and radio advertising to online digital advertising (ad), where the users are exposed to a sequence of ad campaigns via social networks, display ads, search etc. While advertisers revisit the design of ad campaigns to concurrently serve the requirements emerging out of new ad channels, it is also critical for advertisers to estimate the contribution from touch-points (view, clicks, converts) on different channels, based on the sequence of customer actions. This process of contribution measurement is often referred to as multi-touch attribution (MTA). In this work, we propose CAMTA, a novel deep recurrent neural network architecture which is a casual attribution mechanism for user-personalised MTA in the context of observational data. CAMTA minimizes the selection bias in channel assignment across time-steps and touchpoints. Furthermore, it utilizes the users' pre-conversion actions in a principled way in order to predict pre-channel attribution. To quantitatively benchmark the proposed MTA model, we employ the real world Criteo dataset and demonstrate the superior performance of CAMTA with respect to prediction accuracy as compared to several baselines. In addition, we provide results for budget allocation and user-behaviour modelling on the predicted channel attribution.
Batch-Constrained Distributional Reinforcement Learning for Session-based Recommendation
Dec 16, 2020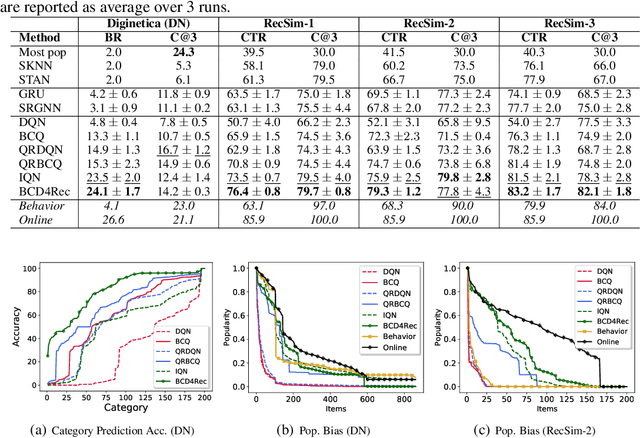
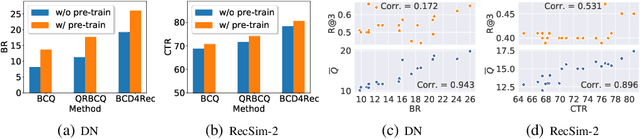

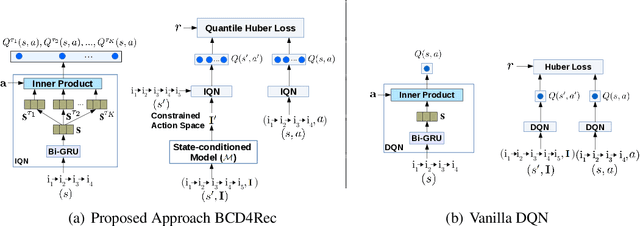
Most of the existing deep reinforcement learning (RL) approaches for session-based recommendations either rely on costly online interactions with real users, or rely on potentially biased rule-based or data-driven user-behavior models for learning. In this work, we instead focus on learning recommendation policies in the pure batch or offline setting, i.e. learning policies solely from offline historical interaction logs or batch data generated from an unknown and sub-optimal behavior policy, without further access to data from the real-world or user-behavior models. We propose BCD4Rec: Batch-Constrained Distributional RL for Session-based Recommendations. BCD4Rec builds upon the recent advances in batch (offline) RL and distributional RL to learn from offline logs while dealing with the intrinsically stochastic nature of rewards from the users due to varied latent interest preferences (environments). We demonstrate that BCD4Rec significantly improves upon the behavior policy as well as strong RL and non-RL baselines in the batch setting in terms of standard performance metrics like Click Through Rates or Buy Rates. Other useful properties of BCD4Rec include: i. recommending items from the correct latent categories indicating better value estimates despite large action space (of the order of number of items), and ii. overcoming popularity bias in clicked or bought items typically present in the offline logs.
Hi-CI: Deep Causal Inference in High Dimensions
Aug 22, 2020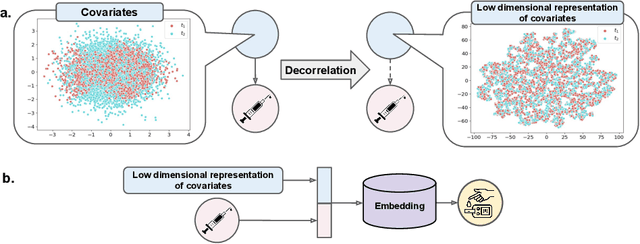
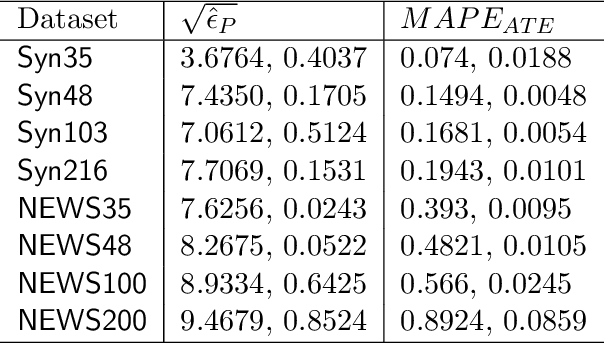
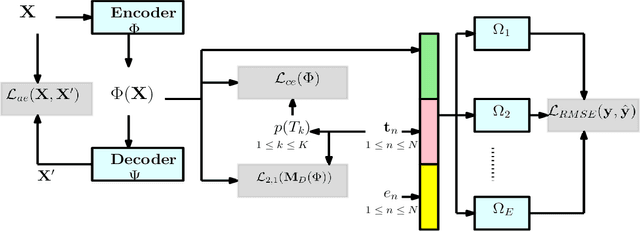
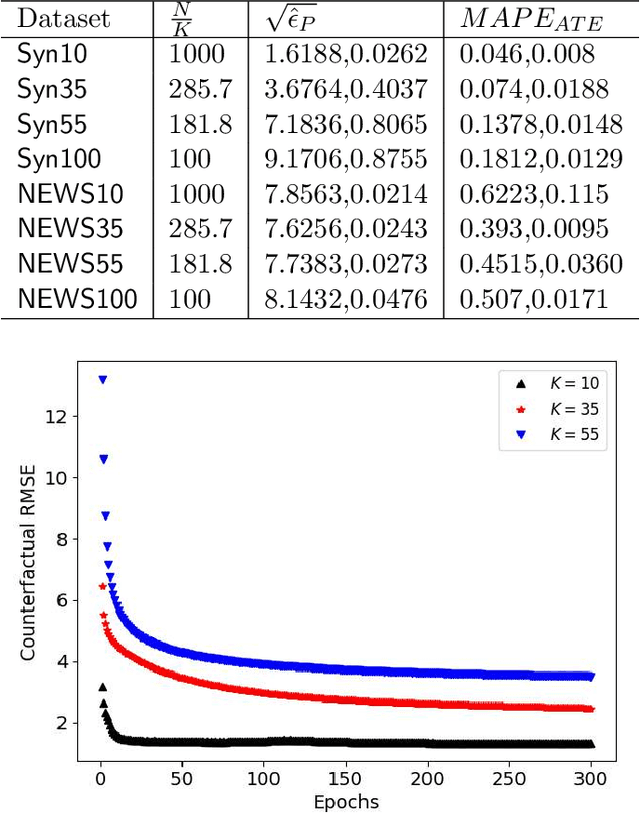
We address the problem of counterfactual regression using causal inference (CI) in observational studies consisting of high dimensional covariates and high cardinality treatments. Confounding bias, which leads to inaccurate treatment effect estimation, is attributed to covariates that affect both treatments and outcome. The presence of high-dimensional co-variates exacerbates the impact of bias as it is harder to isolate and measure the impact of these confounders. In the presence of high-cardinality treatment variables, CI is rendered ill-posed due to the increase in the number of counterfactual outcomes to be predicted. We propose Hi-CI, a deep neural network (DNN) based framework for estimating causal effects in the presence of large number of covariates, and high-cardinal and continuous treatment variables. The proposed architecture comprises of a decorrelation network and an outcome prediction network. In the decorrelation network, we learn a data representation in lower dimensions as compared to the original covariates and addresses confounding bias alongside. Subsequently, in the outcome prediction network, we learn an embedding of high-cardinality and continuous treatments, jointly with the data representation. We demonstrate the efficacy of causal effect prediction of the proposed Hi-CI network using synthetic and real-world NEWS datasets.
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020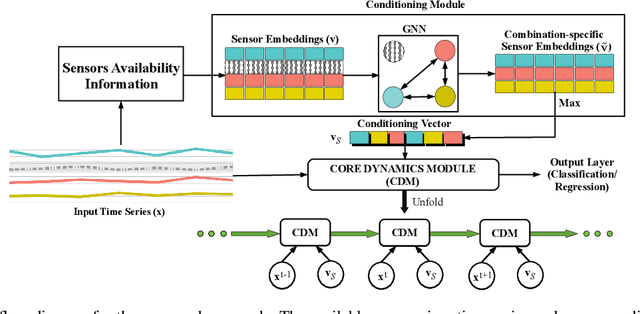
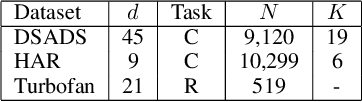
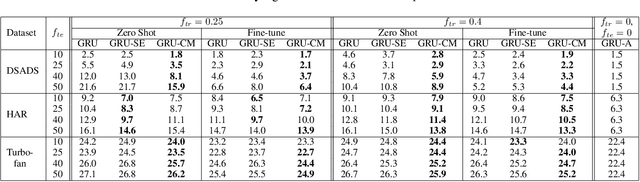
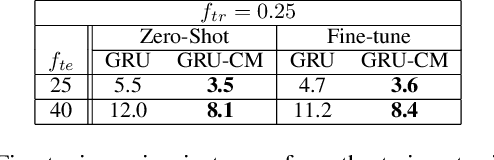
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.