 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Framework for Event Identification via Modal Analysis of PMU Data
Feb 14, 2022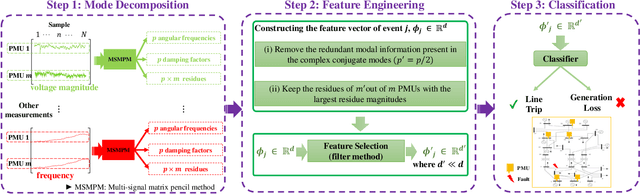
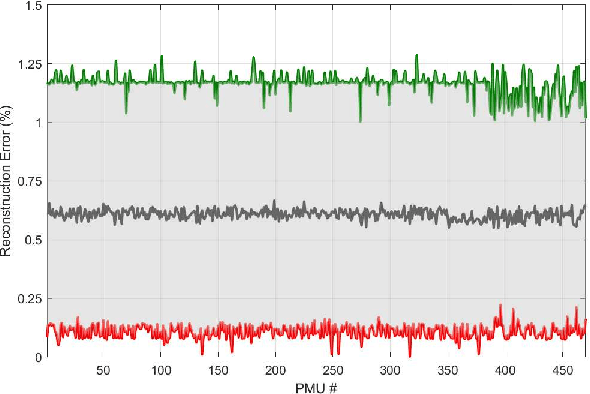
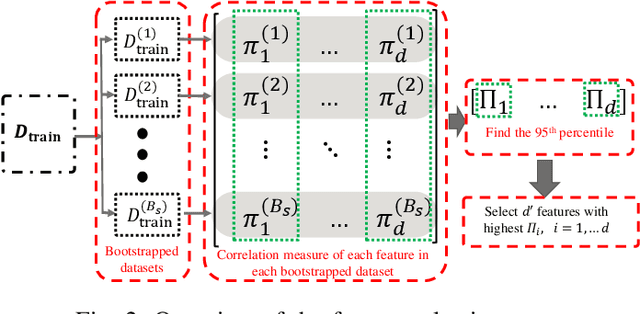
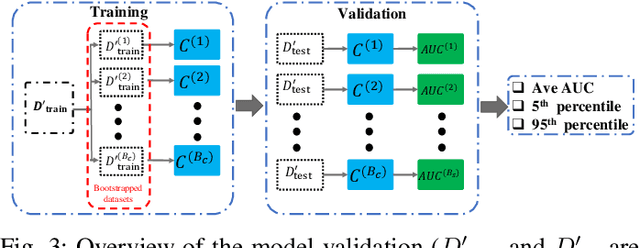
Power systems are prone to a variety of events (e.g. line trips and generation loss) and real-time identification of such events is crucial in terms of situational awareness, reliability, and security. Using measurements from multiple synchrophasors, i.e., phasor measurement units (PMUs), we propose to identify events by extracting features based on modal dynamics. We combine such traditional physics-based feature extraction methods with machine learning to distinguish different event types. Including all measurement channels at each PMU allows exploiting diverse features but also requires learning classification models over a high-dimensional space. To address this issue, various feature selection methods are implemented to choose the best subset of features. Using the obtained subset of features, we investigate the performance of two well-known classification models, namely, logistic regression (LR) and support vector machines (SVM) to identify generation loss and line trip events in two datasets. The first dataset is obtained from simulated generation loss and line trip events in the Texas 2000-bus synthetic grid. The second is a proprietary dataset with labeled events obtained from a large utility in the USA involving measurements from nearly 500 PMUs. Our results indicate that the proposed framework is promising for identifying the two types of events.
A label efficient two-sample test
Nov 29, 2021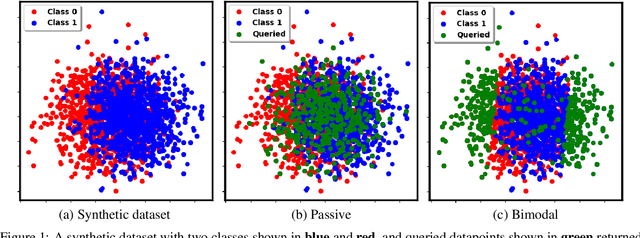
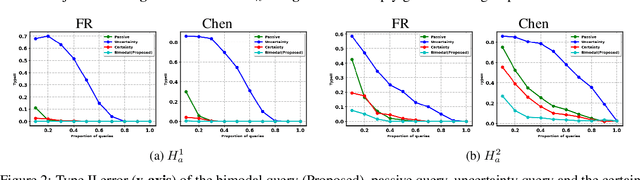
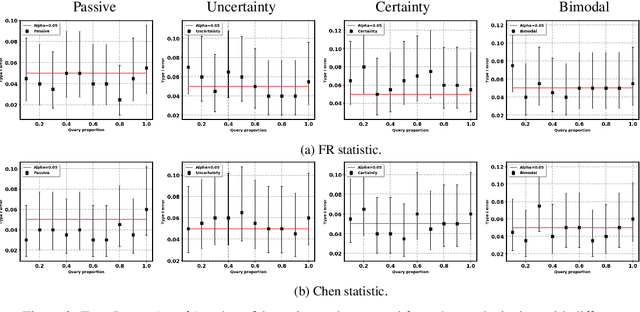
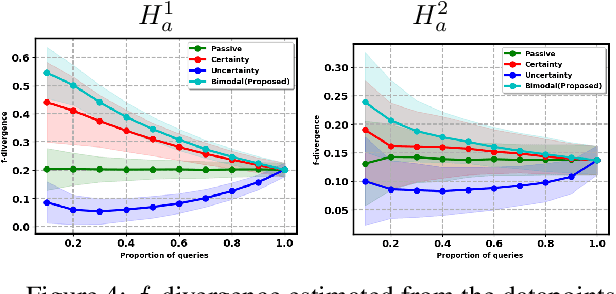
Two-sample tests evaluate whether two samples are realizations of the same distribution (the null hypothesis) or two different distributions (the alternative hypothesis). In the traditional formulation of this problem, the statistician has access to both the measurements (feature variables) and the group variable (label variable). However, in several important applications, feature variables can be easily measured but the binary label variable is unknown and costly to obtain. In this paper, we consider this important variation on the classical two-sample test problem and pose it as a problem of obtaining the labels of only a small number of samples in service of performing a two-sample test. We devise a label efficient three-stage framework: firstly, a classifier is trained with samples uniformly labeled to model the posterior probabilities of the labels; secondly, a novel query scheme dubbed \emph{bimodal query} is used to query labels of samples from both classes with maximum posterior probabilities, and lastly, the classical Friedman-Rafsky (FR) two-sample test is performed on the queried samples. Our theoretical analysis shows that bimodal query is optimal for two-sample testing using the FR statistic under reasonable conditions and that the three-stage framework controls the Type I error. Extensive experiments performed on synthetic, benchmark, and application-specific datasets demonstrate that the three-stage framework has decreased Type II error over uniform querying and certainty-based querying with same number of labels while controlling the Type I error. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Label-Efficient-Two-Sample.
Pure Exploration in Multi-armed Bandits with Graph Side Information
Aug 02, 2021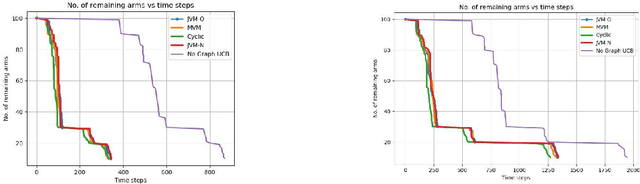
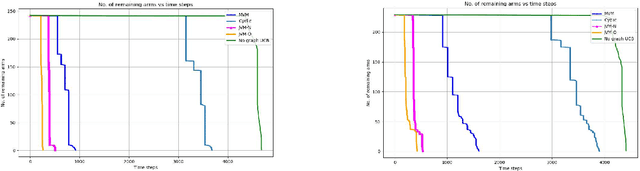
We study pure exploration in multi-armed bandits with graph side-information. In particular, we consider the best arm (and near-best arm) identification problem in the fixed confidence setting under the assumption that the arm rewards are smooth with respect to a given arbitrary graph. This captures a range of real world pure-exploration scenarios where one often has information about the similarity of the options or actions under consideration. We propose a novel algorithm GRUB (GRaph based UcB) for this problem and provide a theoretical characterization of its performance that elicits the benefit of the graph-side information. We complement our theory with experimental results that show that capitalizing on available graph side information yields significant improvements over pure exploration methods that are unable to use this information.
State and Topology Estimation for Unobservable Distribution Systems using Deep Neural Networks
Apr 15, 2021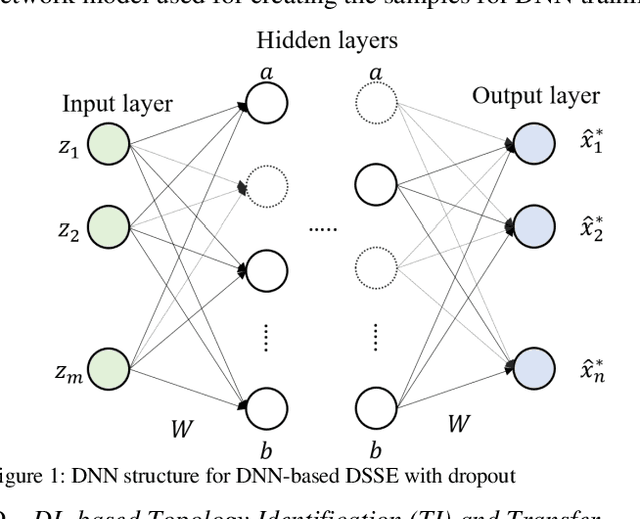
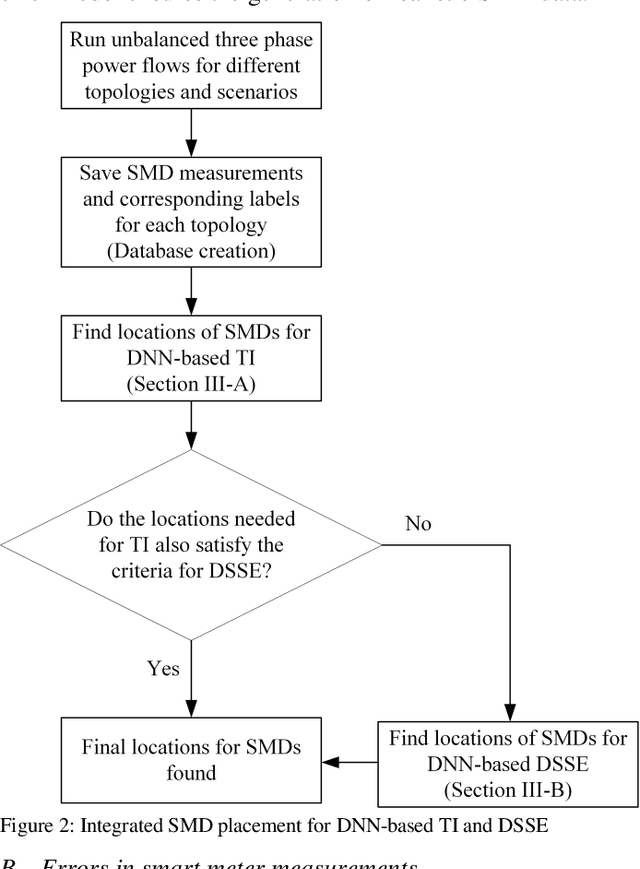
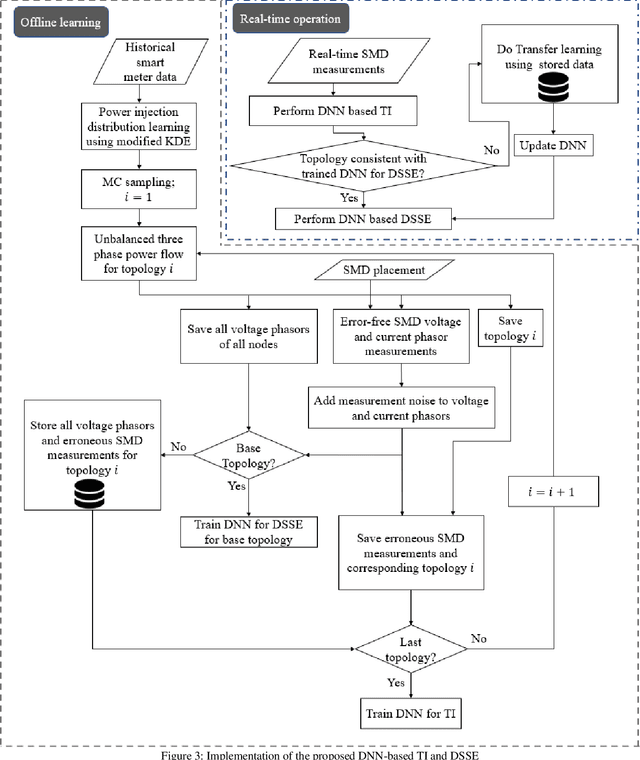
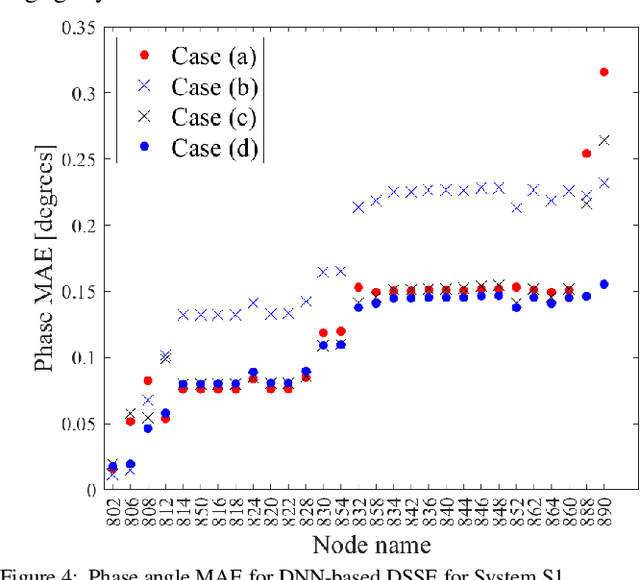
Time-synchronized state estimation for reconfigurable distribution networks is challenging because of limited real-time observability. This paper addresses this challenge by formulating a deep learning (DL)-based approach for topology identification (TI) and unbalanced three-phase distribution system state estimation (DSSE). Two deep neural networks (DNNs) are trained to operate in a sequential manner for implementing DNN-based TI and DSSE for systems that are incompletely observed by synchrophasor measurement devices (SMDs). A data-driven approach for judicious measurement selection to facilitate reliable TI and DSSE is also provided. Robustness of the proposed methodology is demonstrated by considering realistic measurement error models for SMDs as well as presence of renewable energy. A comparative study of the DNN-based DSSE with classical linear state estimation (LSE) indicates that the DL-based approach gives better accuracy with a significantly smaller number of SMDs
Graph Community Detection from Coarse Measurements: Recovery Conditions for the Coarsened Weighted Stochastic Block Model
Feb 25, 2021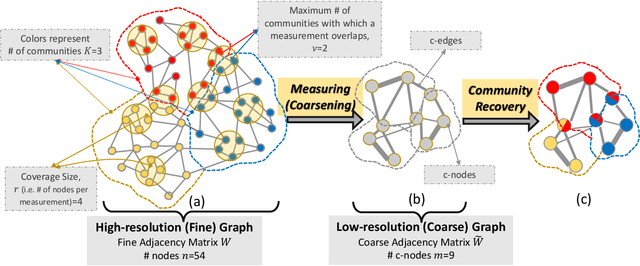
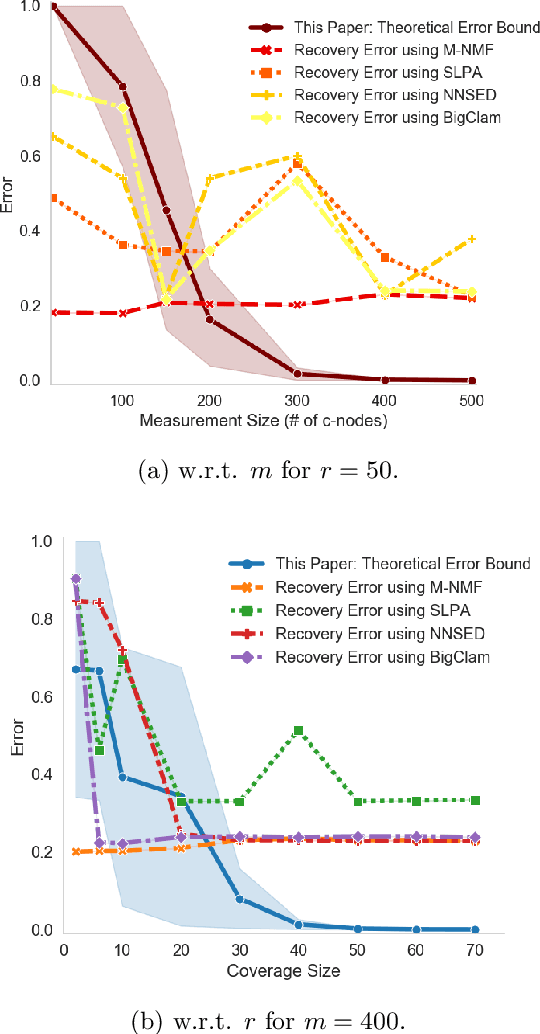
We study the problem of community recovery from coarse measurements of a graph. In contrast to the problem of community recovery of a fully observed graph, one often encounters situations when measurements of a graph are made at low-resolution, each measurement integrating across multiple graph nodes. Such low-resolution measurements effectively induce a coarse graph with its own communities. Our objective is to develop conditions on the graph structure, the quantity, and properties of measurements, under which we can recover the community organization in this coarse graph. In this paper, we build on the stochastic block model by mathematically formalizing the coarsening process, and characterizing its impact on the community members and connections. Through this novel setup and modeling, we characterize an error bound for community recovery. The error bound yields simple and closed-form asymptotic conditions to achieve the perfect recovery of the coarse graph communities.
Finding the Homology of Decision Boundaries with Active Learning
Nov 19, 2020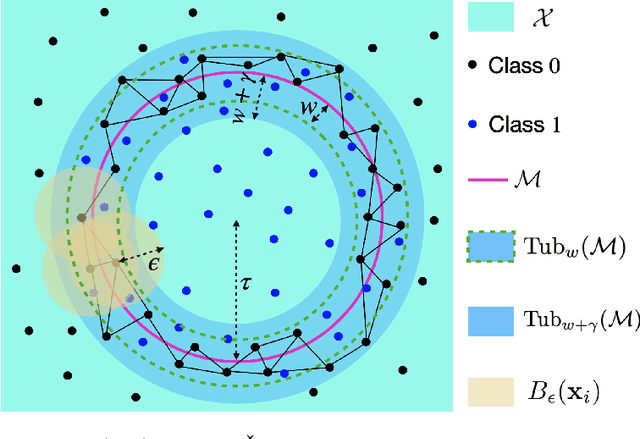
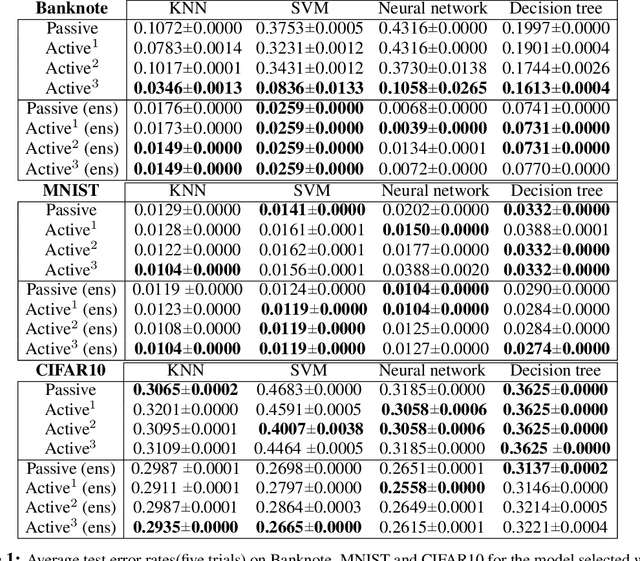

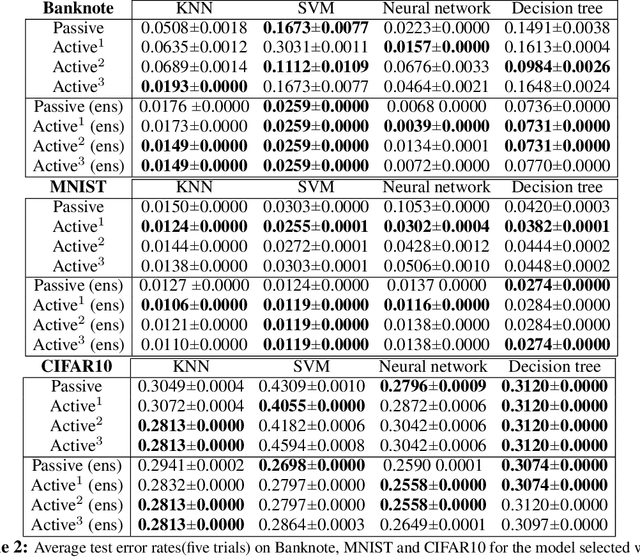
Accurately and efficiently characterizing the decision boundary of classifiers is important for problems related to model selection and meta-learning. Inspired by topological data analysis, the characterization of decision boundaries using their homology has recently emerged as a general and powerful tool. In this paper, we propose an active learning algorithm to recover the homology of decision boundaries. Our algorithm sequentially and adaptively selects which samples it requires the labels of. We theoretically analyze the proposed framework and show that the query complexity of our active learning algorithm depends naturally on the intrinsic complexity of the underlying manifold. We demonstrate the effectiveness of our framework in selecting best-performing machine learning models for datasets just using their respective homological summaries. Experiments on several standard datasets show the sample complexity improvement in recovering the homology and demonstrate the practical utility of the framework for model selection. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Active-Learning-Homology.
Differentiable Programming for Hyperspectral Unmixing using a Physics-based Dispersion Model
Jul 12, 2020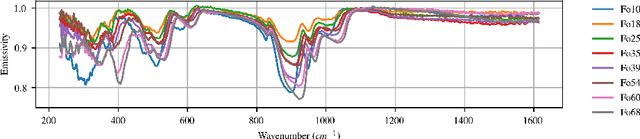
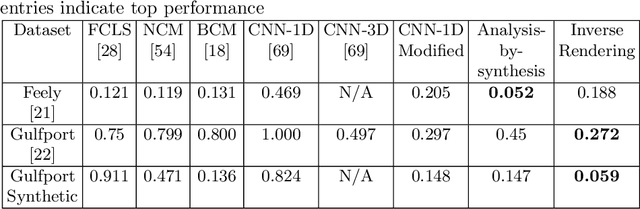
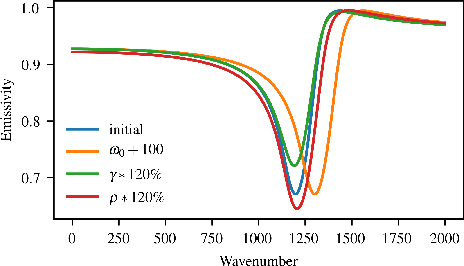
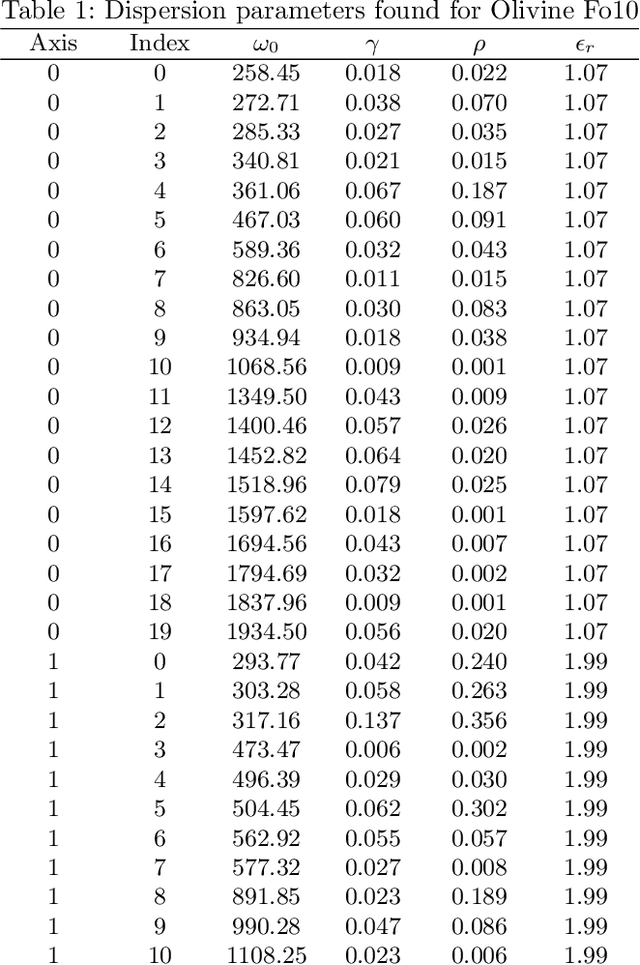
Hyperspectral unmixing is an important remote sensing task with applications including material identification and analysis. Characteristic spectral features make many pure materials identifiable from their visible-to-infrared spectra, but quantifying their presence within a mixture is a challenging task due to nonlinearities and factors of variation. In this paper, spectral variation is considered from a physics-based approach and incorporated into an end-to-end spectral unmixing algorithm via differentiable programming. The dispersion model is introduced to simulate realistic spectral variation, and an efficient method to fit the parameters is presented. Then, this dispersion model is utilized as a generative model within an analysis-by-synthesis spectral unmixing algorithm. Further, a technique for inverse rendering using a convolutional neural network to predict parameters of the generative model is introduced to enhance performance and speed when training data is available. Results achieve state-of-the-art on both infrared and visible-to-near-infrared (VNIR) datasets, and show promise for the synergy between physics-based models and deep learning in hyperspectral unmixing in the future.
On the alpha-loss Landscape in the Logistic Model
Jun 22, 2020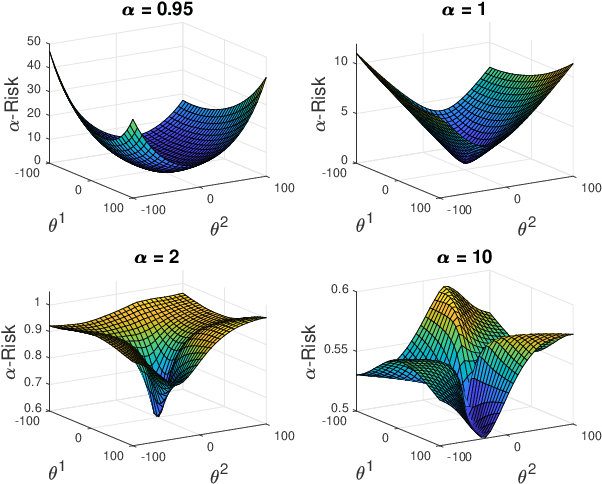
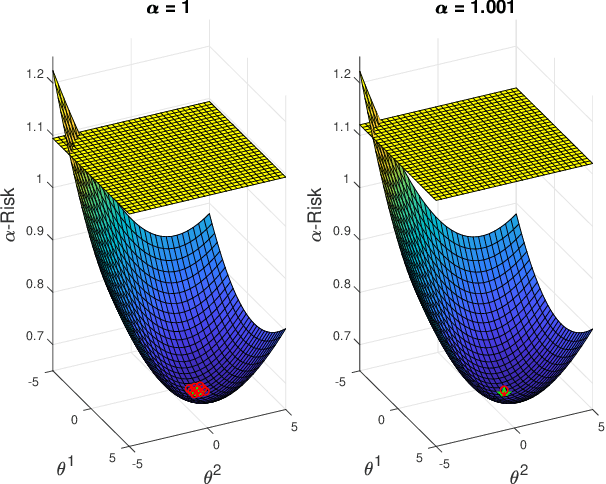
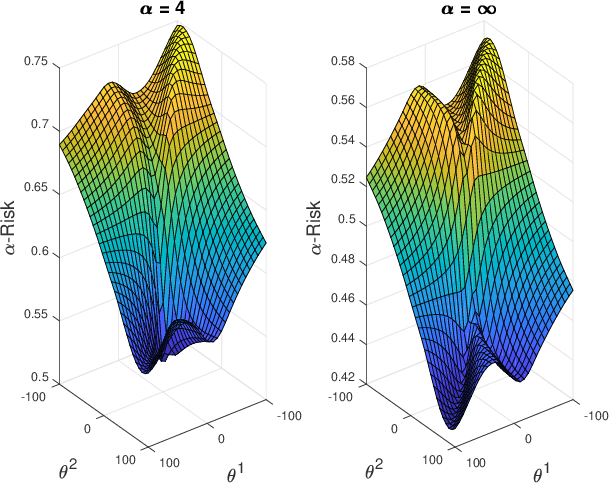
We analyze the optimization landscape of a recently introduced tunable class of loss functions called $\alpha$-loss, $\alpha \in (0,\infty]$, in the logistic model. This family encapsulates the exponential loss ($\alpha = 1/2$), the log-loss ($\alpha = 1$), and the 0-1 loss ($\alpha = \infty$) and contains compelling properties that enable the practitioner to discern among a host of operating conditions relevant to emerging learning methods. Specifically, we study the evolution of the optimization landscape of $\alpha$-loss with respect to $\alpha$ using tools drawn from the study of strictly-locally-quasi-convex functions in addition to geometric techniques. We interpret these results in terms of optimization complexity via normalized gradient descent.
On the Sample Complexity and Optimization Landscape for Quadratic Feasibility Problems
Feb 04, 2020We consider the problem of recovering a complex vector $\mathbf{x}\in \mathbb{C}^n$ from $m$ quadratic measurements $\{\langle A_i\mathbf{x}, \mathbf{x}\rangle\}_{i=1}^m$. This problem, known as quadratic feasibility, encompasses the well known phase retrieval problem and has applications in a wide range of important areas including power system state estimation and x-ray crystallography. In general, not only is the the quadratic feasibility problem NP-hard to solve, but it may in fact be unidentifiable. In this paper, we establish conditions under which this problem becomes {identifiable}, and further prove isometry properties in the case when the matrices $\{A_i\}_{i=1}^m$ are Hermitian matrices sampled from a complex Gaussian distribution. Moreover, we explore a nonconvex {optimization} formulation of this problem, and establish salient features of the associated optimization landscape that enables gradient algorithms with an arbitrary initialization to converge to a \emph{globally optimal} point with a high probability. Our results also reveal sample complexity requirements for successfully identifying a feasible solution in these contexts.
Regularization via Structural Label Smoothing
Jan 07, 2020
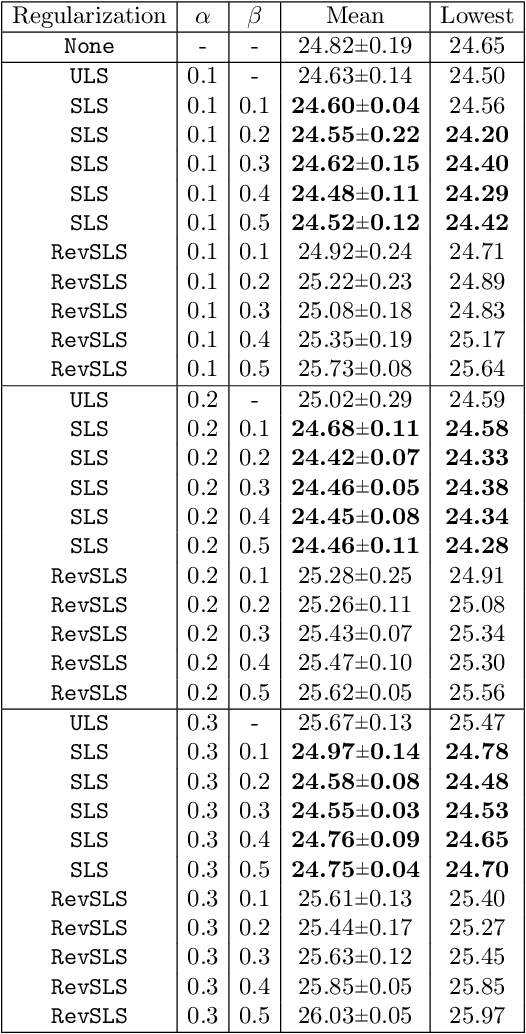
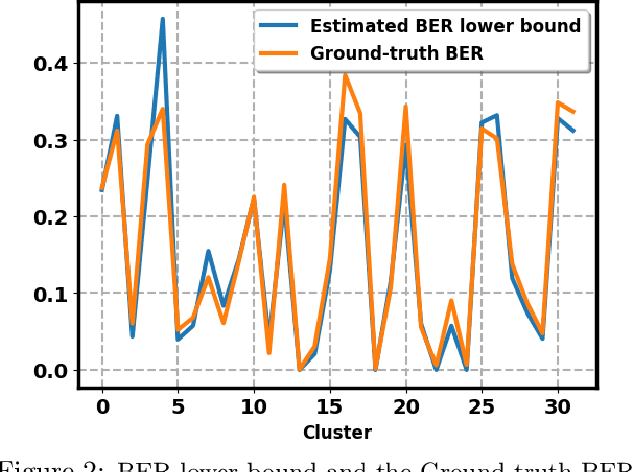
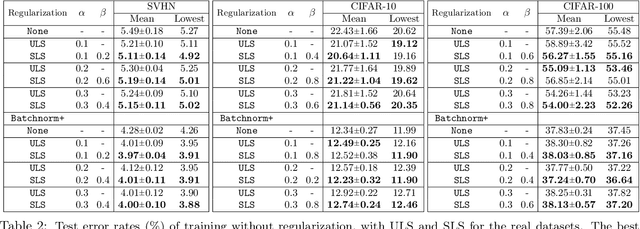
Regularization is an effective way to promote the generalization performance of machine learning models. In this paper, we focus on label smoothing, a form of output distribution regularization that prevents overfitting of a neural network by softening the ground-truth labels in the training data in an attempt to penalize overconfident outputs. Existing approaches typically use cross-validation to impose this smoothing, which is uniform across all training data. In this paper, we show that such label smoothing imposes a quantifiable bias in the Bayes error rate of the training data, with regions of the feature space with high overlap and low marginal likelihood having a lower bias and regions of low overlap and high marginal likelihood having a higher bias. These theoretical results motivate a simple objective function for data-dependent smoothing to mitigate the potential negative consequences of the operation while maintaining its desirable properties as a regularizer. We call this approach Structural Label Smoothing (SLS). We implement SLS and empirically validate on synthetic, Higgs, SVHN, CIFAR-10, and CIFAR-100 datasets. The results confirm our theoretical insights and demonstrate the effectiveness of the proposed method in comparison to traditional label smoothing.