 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Sustained Creativity and Diversity in Large Language Models
Mar 19, 2026We address a not-widely-recognized subset of exploratory search, where a user sets out on a typically long "search quest" for the perfect wedding dress, overlooked research topic, killer company idea, etc. The first few outputs of current large language models (LLMs) may be helpful but only as a start, since the quest requires learning the search space and evaluating many diverse and creative alternatives along the way. Although LLMs encode an impressive fraction of the world's knowledge, common decoding methods are narrowly optimized for prompts with correct answers and thus return mostly homogeneous and conventional results. Other approaches, including those designed to increase diversity across a small set of answers, start to repeat themselves long before search quest users learn enough to make final choices, or offer a uniform type of "creativity" to every user asking similar questions. We develop a novel, easy-to-implement decoding scheme that induces sustained creativity and diversity in LLMs, producing as many conceptually unique results as desired, even without access to the inner workings of an LLM's vector space. The algorithm unlocks an LLM's vast knowledge, both orthodox and heterodox, well beyond modal decoding paths. With this approach, search quest users can more quickly explore the search space and find satisfying answers.
A Theory of Statistical Inference for Ensuring the Robustness of Scientific Results
Apr 23, 2018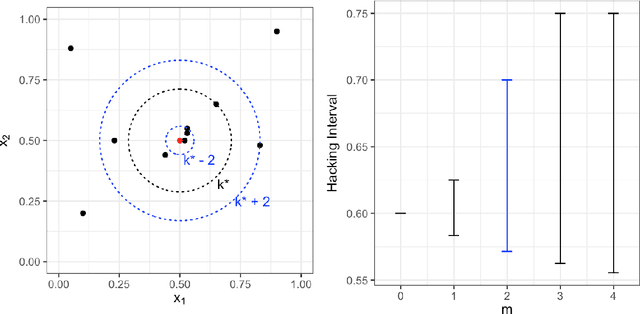
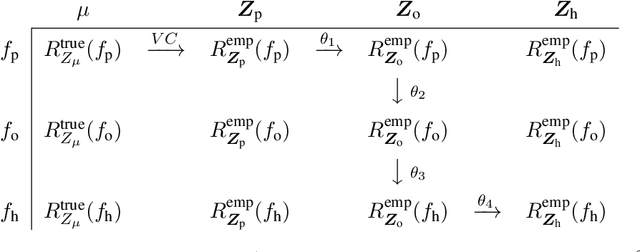
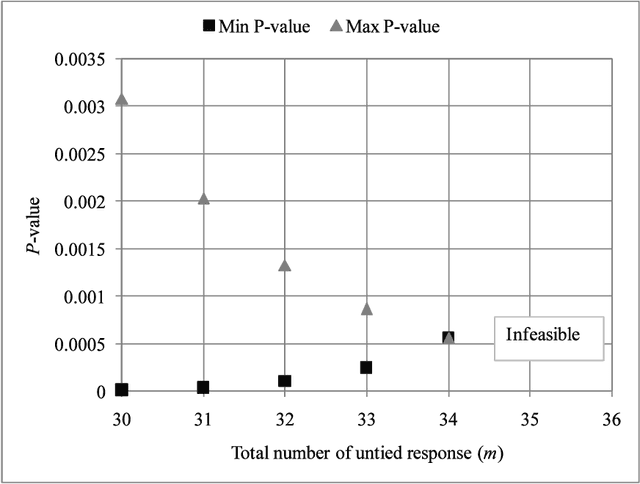
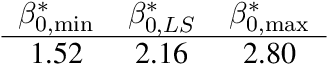
Inference is the process of using facts we know to learn about facts we do not know. A theory of inference gives assumptions necessary to get from the former to the latter, along with a definition for and summary of the resulting uncertainty. Any one theory of inference is neither right nor wrong, but merely an axiom that may or may not be useful. Each of the many diverse theories of inference can be valuable for certain applications. However, no existing theory of inference addresses the tendency to choose, from the range of plausible data analysis specifications consistent with prior evidence, those that inadvertently favor one's own hypotheses. Since the biases from these choices are a growing concern across scientific fields, and in a sense the reason the scientific community was invented in the first place, we introduce a new theory of inference designed to address this critical problem. We derive "hacking intervals," which are the range of a summary statistic one may obtain given a class of possible endogenous manipulations of the data. Hacking intervals require no appeal to hypothetical data sets drawn from imaginary superpopulations. A scientific result with a small hacking interval is more robust to researcher manipulation than one with a larger interval, and is often easier to interpret than a classical confidence interval. Some versions of hacking intervals turn out to be equivalent to classical confidence intervals, which means they may also provide a more intuitive and potentially more useful interpretation of classical confidence intervals