 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIP: Feedback-Guided Prompt Retrieval for Large Multimodal Models
Jun 10, 2026In-Context Learning (ICL) has become a powerful mechanism for adapting Large Language Models (LLMs) to new tasks without fine-tuning. Extending this concept to Large Multimodal Models (LMMs), Multimodal In-Context Learning (M-ICL) relies on retrieving relevant examples, such as images, captions, or question-answer pairs, to guide predictions across tasks like classification, captioning, and visual question answering (VQA). Most existing approaches select in-context examples based on feature-space similarity, assuming that semantically similar samples provide the most useful context. However, our systematic analysis reveals that this assumption does not always hold: visually similar examples are not necessarily those that most effectively enhance in-context learning performance. To address this, we propose the Guided Retrieval of In-context Prompts (GRIP), a learnable vision-only retrieval framework that leverages feedback from LMMs to identify examples that truly improve model predictions. GRIP learns to distinguish beneficial from detrimental in-context examples through contrastive training, refining retrieval beyond pure similarity. Across three multimodal tasks, namely classification, captioning, and VQA, GRIP improves consistently over similarity-based retrieval on Qwen2.5-VL-7B, with its strongest gains in classification on Idefics2-8B. Moreover, we demonstrate that retrievers trained with feedback from one open LMM can be transferred to other models without retraining, including closed-source GPT-4o and Gemini, enabling scalable and cost-efficient deployment of M-ICL. Code will be published upon acceptance.
Semi-Supervised Object Detection in the Open World
Jul 28, 2023Existing approaches for semi-supervised object detection assume a fixed set of classes present in training and unlabeled datasets, i.e., in-distribution (ID) data. The performance of these techniques significantly degrades when these techniques are deployed in the open-world, due to the fact that the unlabeled and test data may contain objects that were not seen during training, i.e., out-of-distribution (OOD) data. The two key questions that we explore in this paper are: can we detect these OOD samples and if so, can we learn from them? With these considerations in mind, we propose the Open World Semi-supervised Detection framework (OWSSD) that effectively detects OOD data along with a semi-supervised learning pipeline that learns from both ID and OOD data. We introduce an ensemble based OOD detector consisting of lightweight auto-encoder networks trained only on ID data. Through extensive evalulation, we demonstrate that our method performs competitively against state-of-the-art OOD detection algorithms and also significantly boosts the semi-supervised learning performance in open-world scenarios.
smol: Sensing Soil Moisture using LoRa
Oct 04, 2021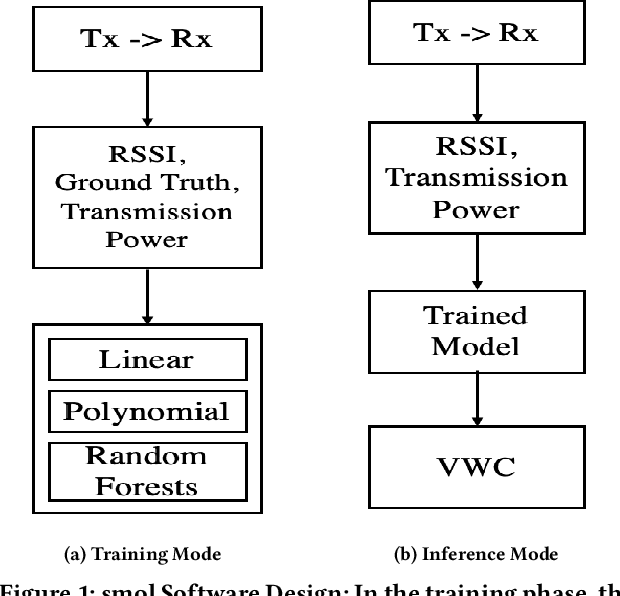
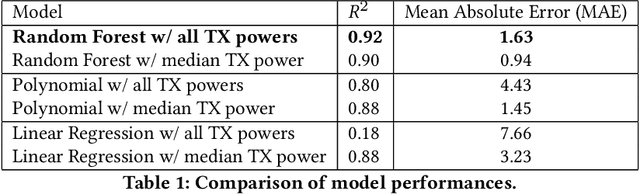


Technologies for environmental and agricultural monitoring are on the rise, however, there is a lack of small, low-power, and lowcost sensing devices in the industry. One of these monitoring tools is a soil moisture sensor. Soil moisture has significant effects on crop health and yield, but commercial monitors are very expensive, require manual use, or constant attention. This calls for a simple and low-cost solution based on novel technology. In this work, we introduce smol: Sensing Soil Moisture using LoRa, a low-cost system to measure soil moisture using received signal strength indicator (RSSI) and transmission power. It is compact and can be deployed in the field to collect data automatically with little manual intervention. Our design is enabled by the phenomenon that soil moisture attenuates wireless signals, so the signal strength between a transmitter-receiver pair decreases. We exploit this physical property to determine the variation in soil moisture. We designed and tested our measurement-based prototype in both indoor and outdoor environments. With proper regression calibration, we show soil moisture can be predicted using LoRa parameters.