 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving EHR Data Transformation via Geometric Operators: A Human-AI Co-Design Technical Report
Mar 24, 2026Electronic health records (EHRs) and other real-world clinical data are essential for clinical research, medical artificial intelligence, and life science, but their sharing is severely limited by privacy, governance, and interoperability constraints. These barriers create persistent data silos that hinder multi-center studies, large-scale model development, and broader biomedical discovery. Existing privacy-preserving approaches, including multi-party computation and related cryptographic techniques, provide strong protection but often introduce substantial computational overhead, reducing the efficiency of large-scale machine learning and foundation-model training. In addition, many such methods make data usable for restricted computation while leaving them effectively invisible to clinicians and researchers, limiting their value in workflows that still require direct inspection, exploratory analysis, and human interpretation. We propose a real-world-data transformation framework for privacy-preserving sharing of structured clinical records. Instead of converting data into opaque representations, our approach constructs transformed numeric views that preserve medical semantics and major statistical properties while, under a clearly specified threat model, provably breaking direct linkage between those views and protected patient-level attributes. Through collaboration between computer scientists and the AI agent \textbf{SciencePal}, acting as a constrained tool inventor under human guidance, we design three transformation operators that are non-reversible within this threat model, together with an additional mixing strategy for high-risk scenarios, supported by theoretical analysis and empirical evaluation under reconstruction, record linkage, membership inference, and attribute inference attacks.
Efficient Estimation of the Central Mean Subspace via Smoothed Gradient Outer Products
Dec 24, 2023


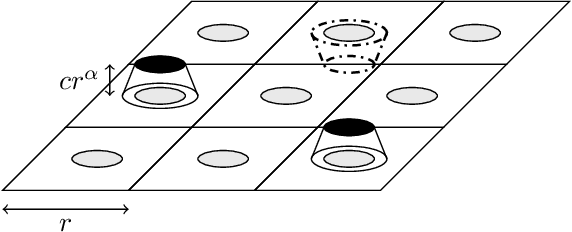
We consider the problem of sufficient dimension reduction (SDR) for multi-index models. The estimators of the central mean subspace in prior works either have slow (non-parametric) convergence rates, or rely on stringent distributional conditions (e.g., the covariate distribution $P_{\mathbf{X}}$ being elliptical symmetric). In this paper, we show that a fast parametric convergence rate of form $C_d \cdot n^{-1/2}$ is achievable via estimating the \emph{expected smoothed gradient outer product}, for a general class of distribution $P_{\mathbf{X}}$ admitting Gaussian or heavier distributions. When the link function is a polynomial with a degree of at most $r$ and $P_{\mathbf{X}}$ is the standard Gaussian, we show that the prefactor depends on the ambient dimension $d$ as $C_d \propto d^r$.
Nuances in Margin Conditions Determine Gains in Active Learning
Oct 16, 2021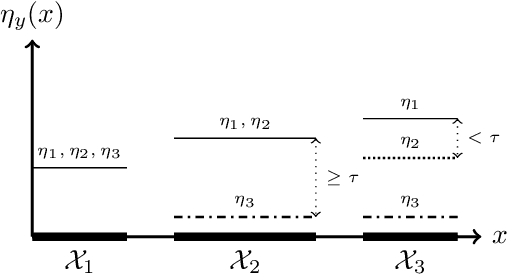
We consider nonparametric classification with smooth regression functions, where it is well known that notions of margin in $E[Y|X]$ determine fast or slow rates in both active and passive learning. Here we elucidate a striking distinction between the two settings. Namely, we show that some seemingly benign nuances in notions of margin -- involving the uniqueness of the Bayes classifier, and which have no apparent effect on rates in passive learning -- determine whether or not any active learner can outperform passive learning rates. In particular, for Audibert-Tsybakov's margin condition (allowing general situations with non-unique Bayes classifiers), no active learner can gain over passive learning in commonly studied settings where the marginal on $X$ is near uniform. Our results thus negate the usual intuition from past literature that active rates should improve over passive rates in nonparametric settings.
Weakly Supervised Learning Creates a Fusion of Modeling Cultures
Jun 02, 2021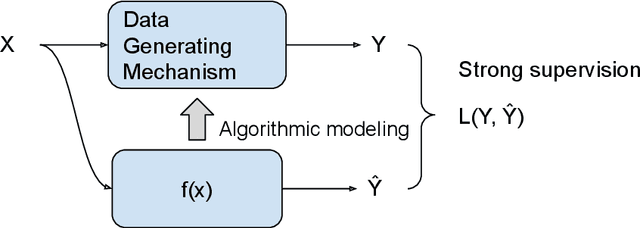
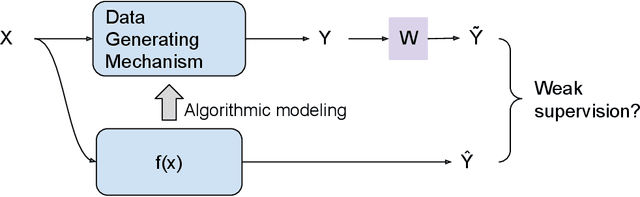
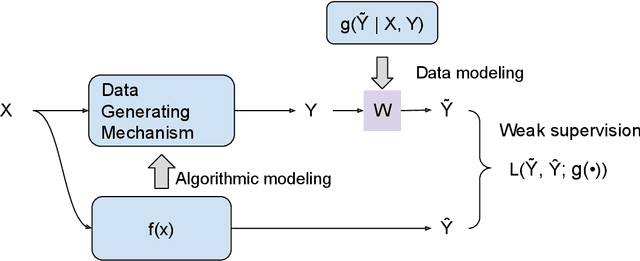
The past two decades have witnessed the great success of the algorithmic modeling framework advocated by Breiman et al. (2001). Nevertheless, the excellent prediction performance of these black-box models rely heavily on the availability of strong supervision, i.e. a large set of accurate and exact ground-truth labels. In practice, strong supervision can be unavailable or expensive, which calls for modeling techniques under weak supervision. In this comment, we summarize the key concepts in weakly supervised learning and discuss some recent developments in the field. Using algorithmic modeling alone under a weak supervision might lead to unstable and misleading results. A promising direction would be integrating the data modeling culture into such a framework.