 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Policy Iteration: Performance Robustness Across Architecture and Environment Perturbations
Dec 12, 2025In a recent work, we proposed Reliable Policy Iteration (RPI), that restores policy iteration's monotonicity-of-value-estimates property to the function approximation setting. Here, we assess the robustness of RPI's empirical performance on two classical control tasks -- CartPole and Inverted Pendulum -- under changes to neural network and environmental parameters. Relative to DQN, Double DQN, DDPG, TD3, and PPO, RPI reaches near-optimal performance early and sustains this policy as training proceeds. Because deep RL methods are often hampered by sample inefficiency, training instability, and hyperparameter sensitivity, our results highlight RPI's promise as a more reliable alternative.
Reliable Critics: Monotonic Improvement and Convergence Guarantees for Reinforcement Learning
Jun 08, 2025



Despite decades of research, it remains challenging to correctly use Reinforcement Learning (RL) algorithms with function approximation. A prime example is policy iteration, whose fundamental guarantee of monotonic improvement collapses even under linear function approximation. To address this issue, we introduce Reliable Policy Iteration (RPI). It replaces the common projection or Bellman-error minimization during policy evaluation with a Bellman-based constrained optimization. We prove that not only does RPI confer textbook monotonicity on its value estimates but these estimates also lower bound the true return. Also, their limit partially satisfies the unprojected Bellman equation, emphasizing RPI's natural fit within RL. RPI is the first algorithm with such monotonicity and convergence guarantees under function approximation. For practical use, we provide a model-free variant of RPI that amounts to a novel critic. It can be readily integrated into primary model-free PI implementations such as DQN and DDPG. In classical control tasks, such RPI-enhanced variants consistently maintain their lower-bound guarantee while matching or surpassing the performance of all baseline methods.
Reinforcement Learning with Segment Feedback
Feb 03, 2025



Standard reinforcement learning (RL) assumes that an agent can observe a reward for each state-action pair. However, in practical applications, it is often difficult and costly to collect a reward for each state-action pair. While there have been several works considering RL with trajectory feedback, it is unclear if trajectory feedback is inefficient for learning when trajectories are long. In this work, we consider a model named RL with segment feedback, which offers a general paradigm filling the gap between per-state-action feedback and trajectory feedback. In this model, we consider an episodic Markov decision process (MDP), where each episode is divided into $m$ segments, and the agent observes reward feedback only at the end of each segment. Under this model, we study two popular feedback settings: binary feedback and sum feedback, where the agent observes a binary outcome and a reward sum according to the underlying reward function, respectively. To investigate the impact of the number of segments $m$ on learning performance, we design efficient algorithms and establish regret upper and lower bounds for both feedback settings. Our theoretical and experimental results show that: under binary feedback, increasing the number of segments $m$ decreases the regret at an exponential rate; in contrast, surprisingly, under sum feedback, increasing $m$ does not reduce the regret significantly.
Gradient Boosting Reinforcement Learning
Jul 11, 2024



Neural networks (NN) achieve remarkable results in various tasks, but lack key characteristics: interpretability, support for categorical features, and lightweight implementations suitable for edge devices. While ongoing efforts aim to address these challenges, Gradient Boosting Trees (GBT) inherently meet these requirements. As a result, GBTs have become the go-to method for supervised learning tasks in many real-world applications and competitions. However, their application in online learning scenarios, notably in reinforcement learning (RL), has been limited. In this work, we bridge this gap by introducing Gradient-Boosting RL (GBRL), a framework that extends the advantages of GBT to the RL domain. Using the GBRL framework, we implement various actor-critic algorithms and compare their performance with their NN counterparts. Inspired by shared backbones in NN we introduce a tree-sharing approach for policy and value functions with distinct learning rates, enhancing learning efficiency over millions of interactions. GBRL achieves competitive performance across a diverse array of tasks, excelling in domains with structured or categorical features. Additionally, we present a high-performance, GPU-accelerated implementation that integrates seamlessly with widely-used RL libraries (available at https://github.com/NVlabs/gbrl). GBRL expands the toolkit for RL practitioners, demonstrating the viability and promise of GBT within the RL paradigm, particularly in domains characterized by structured or categorical features.
PlaMo: Plan and Move in Rich 3D Physical Environments
Jun 26, 2024Controlling humanoids in complex physically simulated worlds is a long-standing challenge with numerous applications in gaming, simulation, and visual content creation. In our setup, given a rich and complex 3D scene, the user provides a list of instructions composed of target locations and locomotion types. To solve this task we present PlaMo, a scene-aware path planner and a robust physics-based controller. The path planner produces a sequence of motion paths, considering the various limitations the scene imposes on the motion, such as location, height, and speed. Complementing the planner, our control policy generates rich and realistic physical motion adhering to the plan. We demonstrate how the combination of both modules enables traversing complex landscapes in diverse forms while responding to real-time changes in the environment. Video: https://youtu.be/wWlqSQlRZ9M .
Tree Search-Based Policy Optimization under Stochastic Execution Delay
Apr 08, 2024The standard formulation of Markov decision processes (MDPs) assumes that the agent's decisions are executed immediately. However, in numerous realistic applications such as robotics or healthcare, actions are performed with a delay whose value can even be stochastic. In this work, we introduce stochastic delayed execution MDPs, a new formalism addressing random delays without resorting to state augmentation. We show that given observed delay values, it is sufficient to perform a policy search in the class of Markov policies in order to reach optimal performance, thus extending the deterministic fixed delay case. Armed with this insight, we devise DEZ, a model-based algorithm that optimizes over the class of Markov policies. DEZ leverages Monte-Carlo tree search similar to its non-delayed variant EfficientZero to accurately infer future states from the action queue. Thus, it handles delayed execution while preserving the sample efficiency of EfficientZero. Through a series of experiments on the Atari suite, we demonstrate that although the previous baseline outperforms the naive method in scenarios with constant delay, it underperforms in the face of stochastic delays. In contrast, our approach significantly outperforms the baselines, for both constant and stochastic delays. The code is available at http://github.com/davidva1/Delayed-EZ .
Exploration-Driven Policy Optimization in RLHF: Theoretical Insights on Efficient Data Utilization
Feb 15, 2024


Reinforcement Learning from Human Feedback (RLHF) has achieved impressive empirical successes while relying on a small amount of human feedback. However, there is limited theoretical justification for this phenomenon. Additionally, most recent studies focus on value-based algorithms despite the recent empirical successes of policy-based algorithms. In this work, we consider an RLHF algorithm based on policy optimization (PO-RLHF). The algorithm is based on the popular Policy Cover-Policy Gradient (PC-PG) algorithm, which assumes knowledge of the reward function. In PO-RLHF, knowledge of the reward function is not assumed and the algorithm relies on trajectory-based comparison feedback to infer the reward function. We provide performance bounds for PO-RLHF with low query complexity, which provides insight into why a small amount of human feedback may be sufficient to get good performance with RLHF. A key novelty is our trajectory-level elliptical potential analysis technique used to infer reward function parameters when comparison queries rather than reward observations are used. We provide and analyze algorithms in two settings: linear and neural function approximation, PG-RLHF and NN-PG-RLHF, respectively.
SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Search
Jan 30, 2023



Despite the popularity of policy gradient methods, they are known to suffer from large variance and high sample complexity. To mitigate this, we introduce SoftTreeMax -- a generalization of softmax that takes planning into account. In SoftTreeMax, we extend the traditional logits with the multi-step discounted cumulative reward, topped with the logits of future states. We consider two variants of SoftTreeMax, one for cumulative reward and one for exponentiated reward. For both, we analyze the gradient variance and reveal for the first time the role of a tree expansion policy in mitigating this variance. We prove that the resulting variance decays exponentially with the planning horizon as a function of the expansion policy. Specifically, we show that the closer the resulting state transitions are to uniform, the faster the decay. In a practical implementation, we utilize a parallelized GPU-based simulator for fast and efficient tree search. Our differentiable tree-based policy leverages all gradients at the tree leaves in each environment step instead of the traditional single-sample-based gradient. We then show in simulation how the variance of the gradient is reduced by three orders of magnitude, leading to better sample complexity compared to the standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in a faster run time compared to distributed PPO. Lastly, we demonstrate that high reward correlates with lower variance.
SoftTreeMax: Policy Gradient with Tree Search
Sep 28, 2022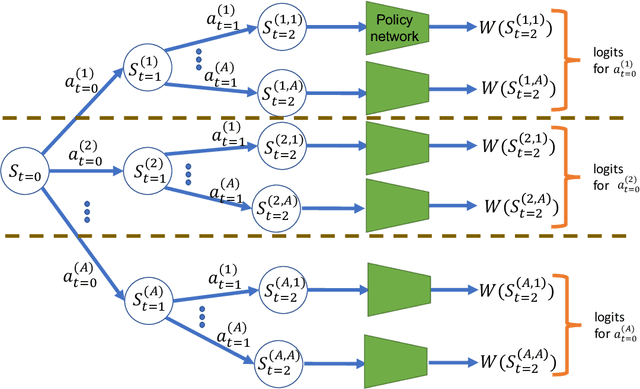
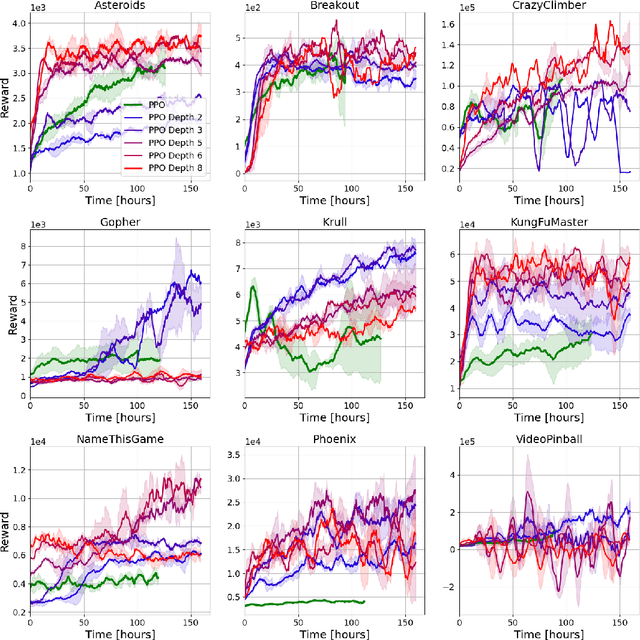
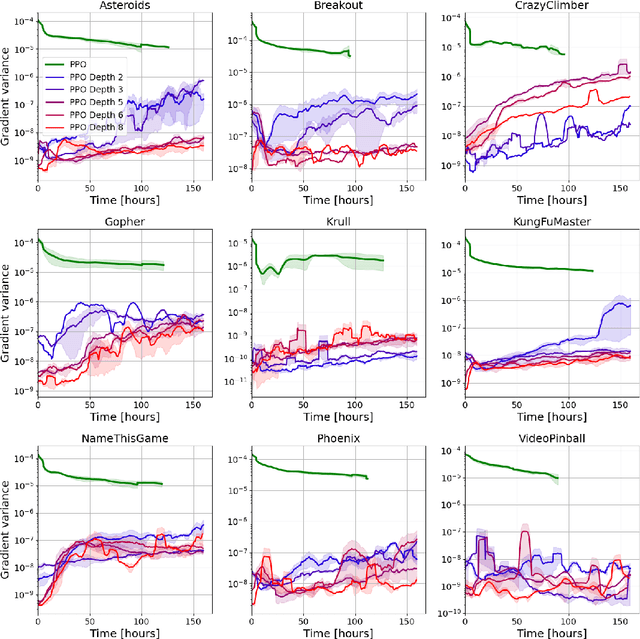
Policy-gradient methods are widely used for learning control policies. They can be easily distributed to multiple workers and reach state-of-the-art results in many domains. Unfortunately, they exhibit large variance and subsequently suffer from high-sample complexity since they aggregate gradients over entire trajectories. At the other extreme, planning methods, like tree search, optimize the policy using single-step transitions that consider future lookahead. These approaches have been mainly considered for value-based algorithms. Planning-based algorithms require a forward model and are computationally intensive at each step, but are more sample efficient. In this work, we introduce SoftTreeMax, the first approach that integrates tree-search into policy gradient. Traditionally, gradients are computed for single state-action pairs. Instead, our tree-based policy structure leverages all gradients at the tree leaves in each environment step. This allows us to reduce the variance of gradients by three orders of magnitude and to benefit from better sample complexity compared with standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in faster run-time compared with distributed PPO.
Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs
Jul 05, 2022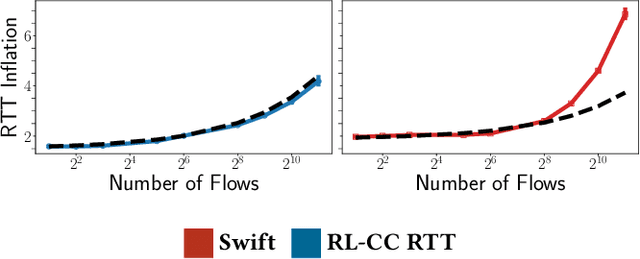

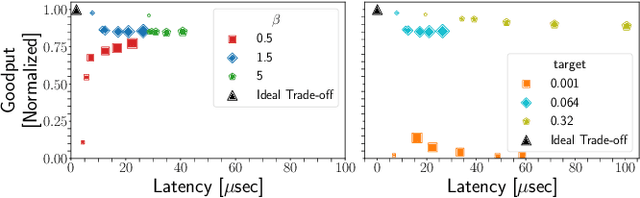
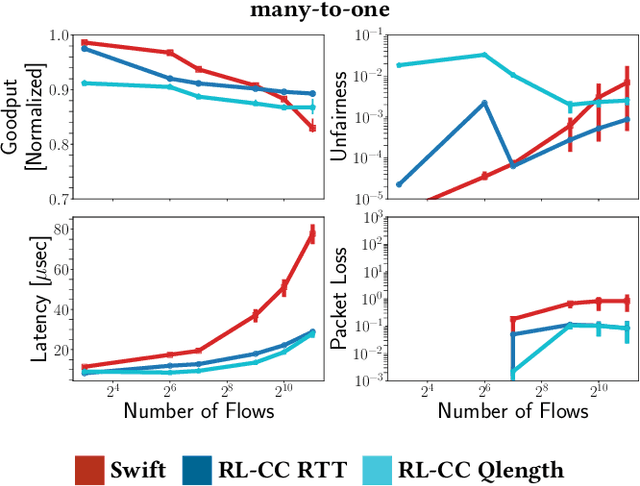
Cloud datacenters are exponentially growing both in numbers and size. This increase results in a network activity surge that warrants better congestion avoidance. The resulting challenge is two-fold: (i) designing algorithms that can be custom-tuned to the complex traffic patterns of a given datacenter; but, at the same time (ii) run on low-level hardware with the required low latency of effective Congestion Control (CC). In this work, we present a Reinforcement Learning (RL) based CC solution that learns from certain traffic scenarios and successfully generalizes to others. We then distill the RL neural network policy into binary decision trees to achieve the desired $\mu$sec decision latency required for real-time inference with RDMA. We deploy the distilled policy on NVIDIA NICs in a real network and demonstrate state-of-the-art performance, balancing all tested metrics simultaneously: bandwidth, latency, fairness, and packet drops.