 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign Overfitting in Linear Classifiers and Leaky ReLU Networks from KKT Conditions for Margin Maximization
Mar 02, 2023Linear classifiers and leaky ReLU networks trained by gradient flow on the logistic loss have an implicit bias towards solutions which satisfy the Karush--Kuhn--Tucker (KKT) conditions for margin maximization. In this work we establish a number of settings where the satisfaction of these KKT conditions implies benign overfitting in linear classifiers and in two-layer leaky ReLU networks: the estimators interpolate noisy training data and simultaneously generalize well to test data. The settings include variants of the noisy class-conditional Gaussians considered in previous work as well as new distributional settings where benign overfitting has not been previously observed. The key ingredient to our proof is the observation that when the training data is nearly-orthogonal, both linear classifiers and leaky ReLU networks satisfying the KKT conditions for their respective margin maximization problems behave like a nearly uniform average of the training examples.
The Double-Edged Sword of Implicit Bias: Generalization vs. Robustness in ReLU Networks
Mar 02, 2023In this work, we study the implications of the implicit bias of gradient flow on generalization and adversarial robustness in ReLU networks. We focus on a setting where the data consists of clusters and the correlations between cluster means are small, and show that in two-layer ReLU networks gradient flow is biased towards solutions that generalize well, but are highly vulnerable to adversarial examples. Our results hold even in cases where the network has many more parameters than training examples. Despite the potential for harmful overfitting in such overparameterized settings, we prove that the implicit bias of gradient flow prevents it. However, the implicit bias also leads to non-robust solutions (susceptible to small adversarial $\ell_2$-perturbations), even though robust networks that fit the data exist.
Adversarial Examples Exist in Two-Layer ReLU Networks for Low Dimensional Data Manifolds
Mar 01, 2023



Despite a great deal of research, it is still not well-understood why trained neural networks are highly vulnerable to adversarial examples. In this work we focus on two-layer neural networks trained using data which lie on a low dimensional linear subspace. We show that standard gradient methods lead to non-robust neural networks, namely, networks which have large gradients in directions orthogonal to the data subspace, and are susceptible to small adversarial $L_2$-perturbations in these directions. Moreover, we show that decreasing the initialization scale of the training algorithm, or adding $L_2$ regularization, can make the trained network more robust to adversarial perturbations orthogonal to the data.
Efficiently Learning Neural Networks: What Assumptions May Suffice?
Feb 15, 2023Understanding when neural networks can be learned efficiently is a fundamental question in learning theory. Existing hardness results suggest that assumptions on both the input distribution and the network's weights are necessary for obtaining efficient algorithms. Moreover, it was previously shown that depth-$2$ networks can be efficiently learned under the assumptions that the input distribution is Gaussian, and the weight matrix is non-degenerate. In this work, we study whether such assumptions may suffice for learning deeper networks and prove negative results. We show that learning depth-$3$ ReLU networks under the Gaussian input distribution is hard even in the smoothed-analysis framework, where a random noise is added to the network's parameters. It implies that learning depth-$3$ ReLU networks under the Gaussian distribution is hard even if the weight matrices are non-degenerate. Moreover, we consider depth-$2$ networks, and show hardness of learning in the smoothed-analysis framework, where both the network parameters and the input distribution are smoothed. Our hardness results are under a well-studied assumption on the existence of local pseudorandom generators.
Implicit Bias in Leaky ReLU Networks Trained on High-Dimensional Data
Oct 13, 2022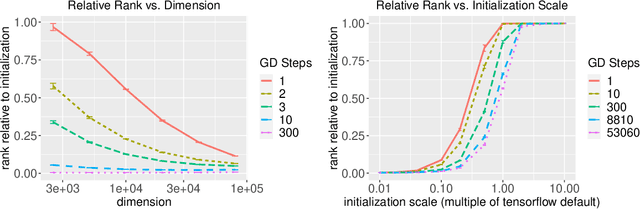
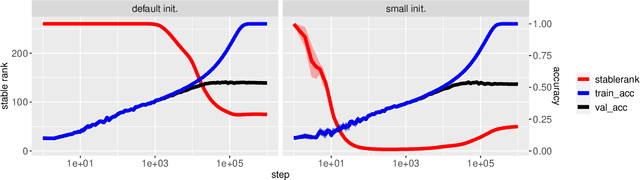
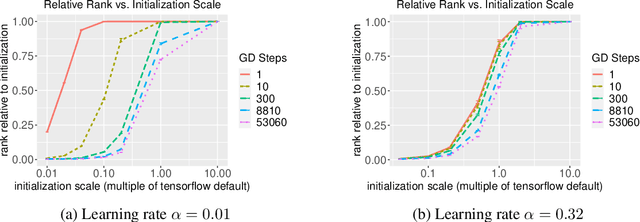
The implicit biases of gradient-based optimization algorithms are conjectured to be a major factor in the success of modern deep learning. In this work, we investigate the implicit bias of gradient flow and gradient descent in two-layer fully-connected neural networks with leaky ReLU activations when the training data are nearly-orthogonal, a common property of high-dimensional data. For gradient flow, we leverage recent work on the implicit bias for homogeneous neural networks to show that asymptotically, gradient flow produces a neural network with rank at most two. Moreover, this network is an $\ell_2$-max-margin solution (in parameter space), and has a linear decision boundary that corresponds to an approximate-max-margin linear predictor. For gradient descent, provided the random initialization variance is small enough, we show that a single step of gradient descent suffices to drastically reduce the rank of the network, and that the rank remains small throughout training. We provide experiments which suggest that a small initialization scale is important for finding low-rank neural networks with gradient descent.
On the Implicit Bias in Deep-Learning Algorithms
Aug 26, 2022

Gradient-based deep-learning algorithms exhibit remarkable performance in practice, but it is not well-understood why they are able to generalize despite having more parameters than training examples. It is believed that implicit bias is a key factor in their ability to generalize, and hence it has been widely studied in recent years. In this short survey, we explain the notion of implicit bias, review main results and discuss their implications.
Reconstructing Training Data from Trained Neural Networks
Jun 15, 2022
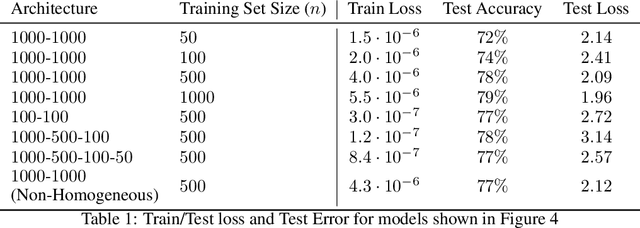
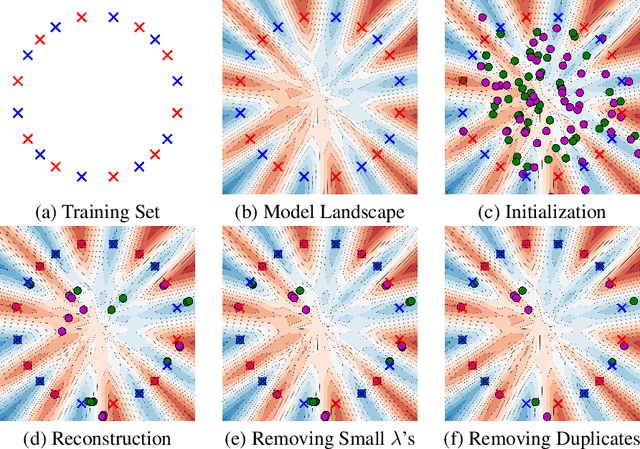
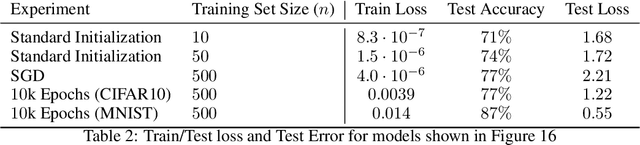
Understanding to what extent neural networks memorize training data is an intriguing question with practical and theoretical implications. In this paper we show that in some cases a significant fraction of the training data can in fact be reconstructed from the parameters of a trained neural network classifier. We propose a novel reconstruction scheme that stems from recent theoretical results about the implicit bias in training neural networks with gradient-based methods. To the best of our knowledge, our results are the first to show that reconstructing a large portion of the actual training samples from a trained neural network classifier is generally possible. This has negative implications on privacy, as it can be used as an attack for revealing sensitive training data. We demonstrate our method for binary MLP classifiers on a few standard computer vision datasets.
On the Effective Number of Linear Regions in Shallow Univariate ReLU Networks: Convergence Guarantees and Implicit Bias
May 18, 2022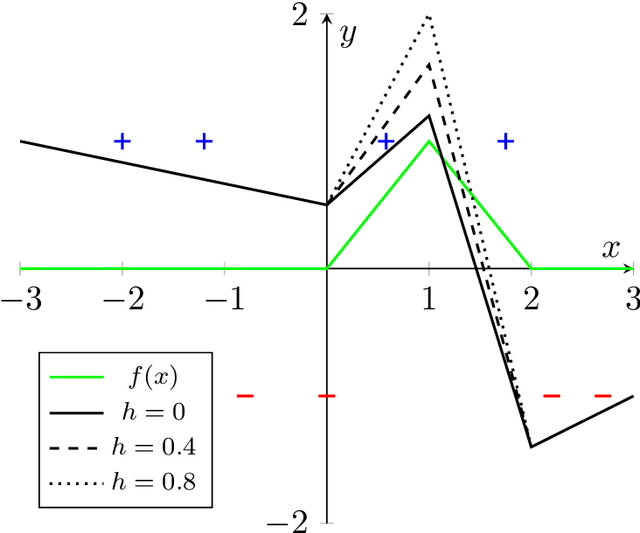
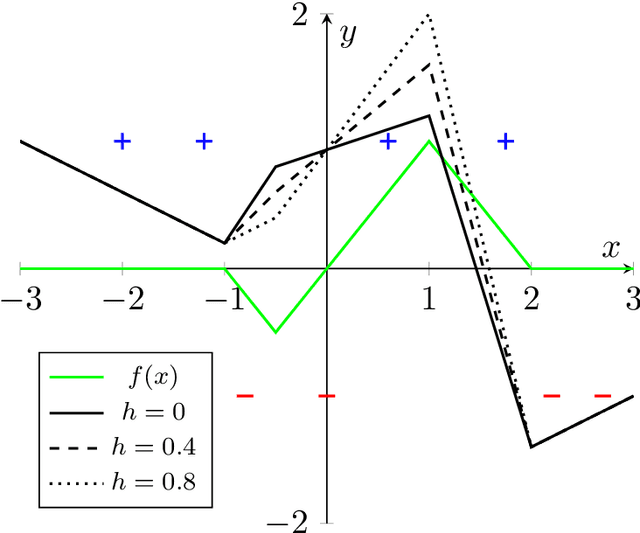
We study the dynamics and implicit bias of gradient flow (GF) on univariate ReLU neural networks with a single hidden layer in a binary classification setting. We show that when the labels are determined by the sign of a target network with $r$ neurons, with high probability over the initialization of the network and the sampling of the dataset, GF converges in direction (suitably defined) to a network achieving perfect training accuracy and having at most $\mathcal{O}(r)$ linear regions, implying a generalization bound. Our result may already hold for mild over-parameterization, where the width is $\tilde{\mathcal{O}}(r)$ and independent of the sample size.
The Sample Complexity of One-Hidden-Layer Neural Networks
Feb 13, 2022
We study norm-based uniform convergence bounds for neural networks, aiming at a tight understanding of how these are affected by the architecture and type of norm constraint, for the simple class of scalar-valued one-hidden-layer networks, and inputs bounded in Euclidean norm. We begin by proving that in general, controlling the spectral norm of the hidden layer weight matrix is insufficient to get uniform convergence guarantees (independent of the network width), while a stronger Frobenius norm control is sufficient, extending and improving on previous work. Motivated by the proof constructions, we identify and analyze two important settings where a mere spectral norm control turns out to be sufficient: First, when the network's activation functions are sufficiently smooth (with the result extending to deeper networks); and second, for certain types of convolutional networks. In the latter setting, we study how the sample complexity is additionally affected by parameters such as the amount of overlap between patches and the overall number of patches.
Gradient Methods Provably Converge to Non-Robust Networks
Feb 09, 2022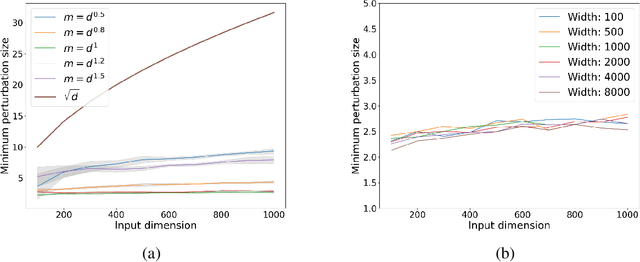
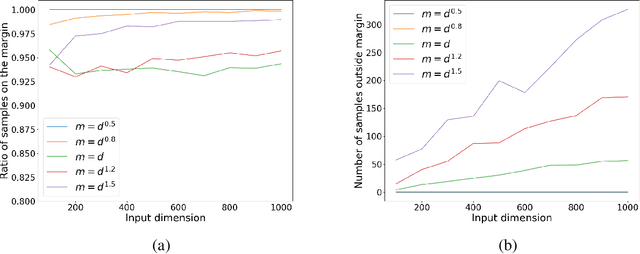
Despite a great deal of research, it is still unclear why neural networks are so susceptible to adversarial examples. In this work, we identify natural settings where depth-$2$ ReLU networks trained with gradient flow are provably non-robust (susceptible to small adversarial $\ell_2$-perturbations), even when robust networks that classify the training dataset correctly exist. Perhaps surprisingly, we show that the well-known implicit bias towards margin maximization induces bias towards non-robust networks, by proving that every network which satisfies the KKT conditions of the max-margin problem is non-robust.