 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Word Often Wins: A Format Confound in Chain-of-Thought Corruption Studies
May 11, 2026Corruption studies, the primary tool for evaluating chain-of-thought (CoT) faithfulness, identify which chain positions are "computationally important" by measuring accuracy when steps are replaced with errors. We identify a systematic confound: for chains with explicit terminal answer statements, the dominant format in standard benchmarks, corruption studies detect where the answer text appears, not where computation occurs. A within-dataset format ablation provides the key evidence: on standard GSM8K chains ending with "the answer is X," removing only the answer statement, preserving all reasoning, collapses suffix sensitivity ~19x at 3B (N=300, p=0.022). Conflicting-answer experiments quantify the causal mechanism: at 7B, CC accuracy drops to near-zero (<=0.02) across five architecture families; the followed-wrong rate spans 0.63-1.00 at 3B-7B and attenuates at larger scales (0.300 at Phi-4-14B, ~0.01 at 32B). A within-stable 7B replication (9.3x attenuation, N=76, p=7.8e-3; Qwen3-8B N=299, p=0.004) provides converging evidence, and the pattern replicates on MATH (DeepSeek-R1-7B: 10.9x suffix-survival recovery). On chains without answer suffixes the same protocol identifies the prefix as load-bearing (Delta=-0.77, p<10^-12). Generation-time probes confirm a dissociation: the answer is not early-determined during generation (early commitment <5%), yet at consumption time model outputs systematically follow the explicit answer text. The format-determination effect persists through 14B (8.5x ratio, p=0.001) and converges toward zero at 32B. We propose a three-prerequisite protocol (question-only control, format characterization, all-position sweep) as a minimum standard for corruption-based faithfulness studies.
The Right Answer, the Wrong Direction: Why Transformers Fail at Counting and How to Fix It
May 05, 2026Large language models often fail at simple counting tasks, even when the items to count are explicitly present in the prompt. We investigate whether this failure occurs because transformers do not represent counts internally, or because they cannot convert those representations into the correct output tokens. Across three model families, Pythia, Qwen3, and Mistral, ranging from 0.4B to 14B parameters, we find strong evidence for the second explanation. Linear probes recover the correct count from intermediate layers with near-perfect accuracy ($R^2>0.99$), showing that the information is present. However, the internal directions that encode counts are nearly orthogonal to the output-head rows for digit tokens ($|\cos|\leq0.032$). In other words, the model stores the count in a form that the digit logits do not naturally read out. We localize this failure with two interventions. Updating only the digit rows of the output head (36,864 parameters) substantially improves constrained next-token digit prediction (60.7 to 100.0% across four tasks), but it does not fix autoregressive generation. By contrast, a small LoRA intervention on attention Q/V weights (7.67M parameters) improves upstream routing and achieves 83.1% +/- 7.2% in true greedy autoregressive generation. Logit-lens measurements confirm the mechanism: the correct digit's vocabulary rank drops from 55,980 to 1, a 50,000x improvement. Additional norm, logit-lens, and cross-task analyses show that the bottleneck generalizes across character counting, addition, and list length, while remaining absent from broader multi-step reasoning benchmarks, including MMLU, GSM8K, and DROP. These results identify counting failure as a geometric readout bottleneck rather than a failure of internal representation: the model knows the count but the output pathway is geometrically misaligned with the tokens needed to express it.
A Fly on the Wall -- Exploiting Acoustic Side-Channels in Differential Pressure Sensors
Sep 26, 2024Differential Pressure Sensors are widely deployed to monitor critical environments. However, our research unveils a previously overlooked vulnerability: their high sensitivity to pressure variations makes them susceptible to acoustic side-channel attacks. We demonstrate that the pressure-sensing diaphragms in DPS can inadvertently capture subtle air vibrations caused by speech, which propagate through the sensor's components and affect the pressure readings. Exploiting this discovery, we introduce \textbf{BaroVox}, a novel attack that reconstructs speech from DPS readings, effectively turning DPS into a "fly on the wall." We model the effect of sound on DPS, exploring the limits and challenges of acoustic leakage. To overcome these challenges, we propose two solutions: a signal-processing approach using a unique spectral subtraction method and a deep learning-based approach for keyword classification. Evaluations under various conditions demonstrate BaroVox's effectiveness, achieving a word error rate of 0.29 for manual recognition and 90.51\% accuracy for automatic recognition. Our findings highlight the significant privacy implications of this vulnerability. We also discuss potential defense strategies to mitigate the risks posed by BaroVox.
0-Step Capturability, Motion Decomposition and Global Feedback Control of the 3D Variable Height-Inverted Pendulum
Dec 12, 2019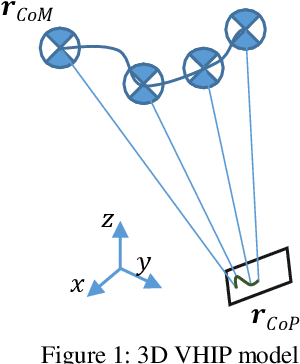
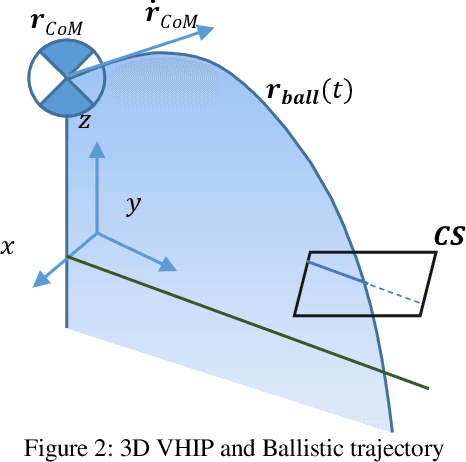
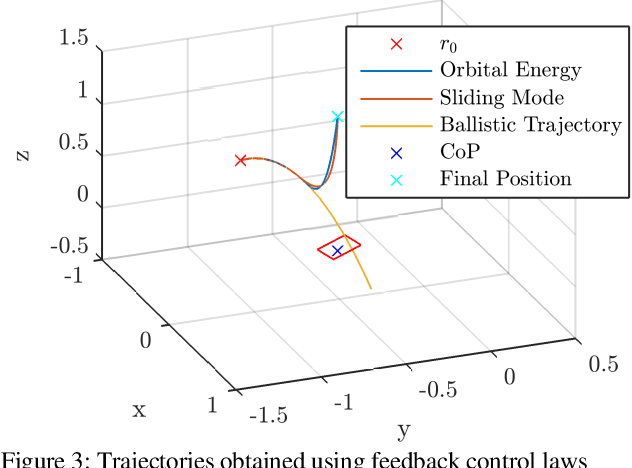
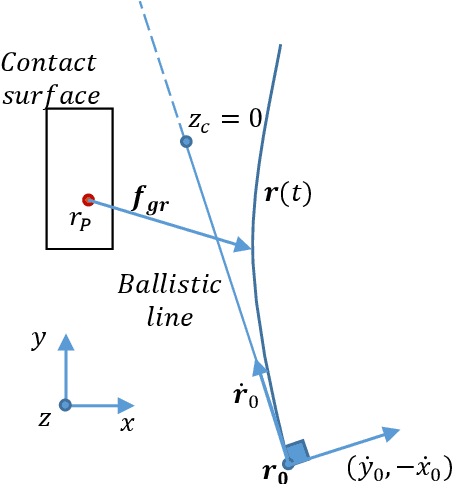
One common method for stabilizing robots after a push is the Instantaneous Capture Point, however, this has the fundamental limitation of assuming constant height. Although there are several works for balancing bipedal robots including height variations in 2D, the amount of literature on 3D models is limited. There are optimization methods using variable Center of Pressure (CoP) and reaction force to the ground, although they do not provide the physical region where a robot can step and require a precomputation for the analysis. This work provides the necessary and sufficient conditions to maintain balance of the 3D Variable Height Inverted Pendulum (VHIP) with both, fixed and variable CoP. We also prove that the 3D VHIP with Fixed CoP is the same as its 2D version, and we generalize controllers working on the 2D VHIP to the 3D VHIP. We also show the generalization of the Divergent Component of Motion to the 3D VHIP and we provide an alternative motion decomposition for the analysis of height and CoP strategies independently. This allow us to generalize previous global feedback controllers done in the 2D VHIP to the 3D VHIP with a Variable CoP.