 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembles of GANs for synthetic training data generation
Apr 23, 2021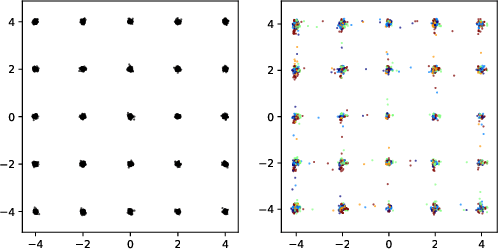
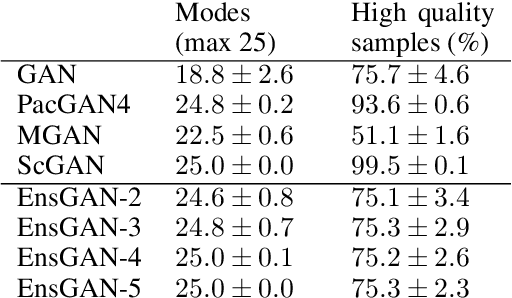
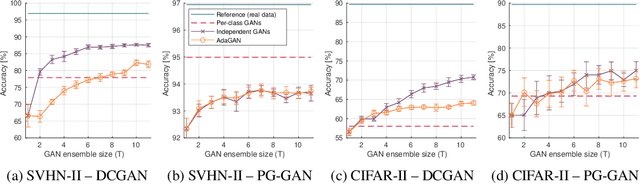
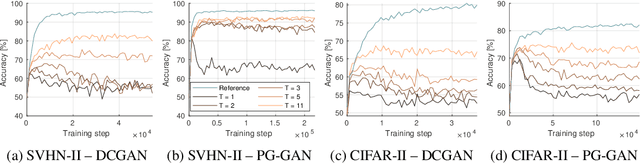
Insufficient training data is a major bottleneck for most deep learning practices, not least in medical imaging where data is difficult to collect and publicly available datasets are scarce due to ethics and privacy. This work investigates the use of synthetic images, created by generative adversarial networks (GANs), as the only source of training data. We demonstrate that for this application, it is of great importance to make use of multiple GANs to improve the diversity of the generated data, i.e. to sufficiently cover the data distribution. While a single GAN can generate seemingly diverse image content, training on this data in most cases lead to severe over-fitting. We test the impact of ensembled GANs on synthetic 2D data as well as common image datasets (SVHN and CIFAR-10), and using both DCGANs and progressively growing GANs. As a specific use case, we focus on synthesizing digital pathology patches to provide anonymized training data.
Unsupervised anomaly detection in digital pathology using GANs
Mar 16, 2021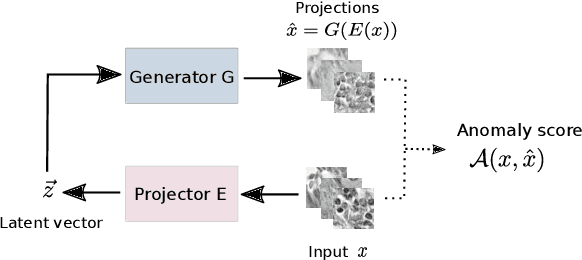

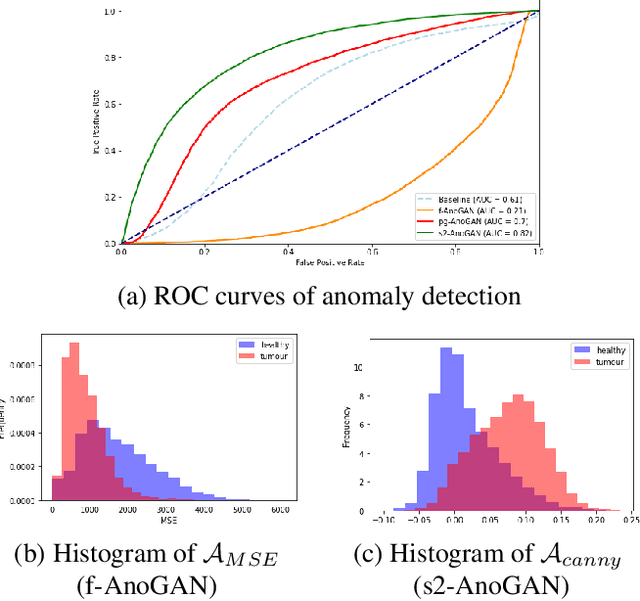

Machine learning (ML) algorithms are optimized for the distribution represented by the training data. For outlier data, they often deliver predictions with equal confidence, even though these should not be trusted. In order to deploy ML-based digital pathology solutions in clinical practice, effective methods for detecting anomalous data are crucial to avoid incorrect decisions in the outlier scenario. We propose a new unsupervised learning approach for anomaly detection in histopathology data based on generative adversarial networks (GANs). Compared to the existing GAN-based methods that have been used in medical imaging, the proposed approach improves significantly on performance for pathology data. Our results indicate that histopathology imagery is substantially more complex than the data targeted by the previous methods. This complexity requires not only a more advanced GAN architecture but also an appropriate anomaly metric to capture the quality of the reconstructed images.
Survey of XAI in digital pathology
Aug 14, 2020
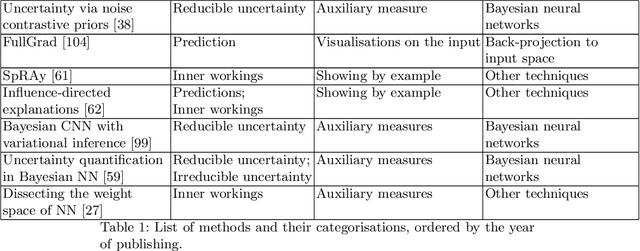
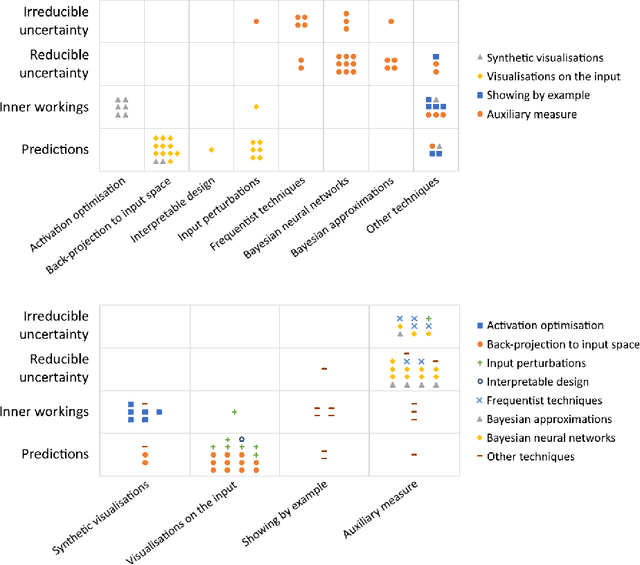
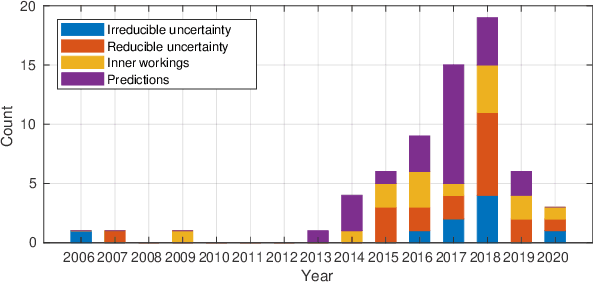
Artificial intelligence (AI) has shown great promise for diagnostic imaging assessments. However, the application of AI to support medical diagnostics in clinical routine comes with many challenges. The algorithms should have high prediction accuracy but also be transparent, understandable and reliable. Thus, explainable artificial intelligence (XAI) is highly relevant for this domain. We present a survey on XAI within digital pathology, a medical imaging sub-discipline with particular characteristics and needs. The review includes several contributions. Firstly, we give a thorough overview of current XAI techniques of potential relevance for deep learning methods in pathology imaging, and categorise them from three different aspects. In doing so, we incorporate uncertainty estimation methods as an integral part of the XAI landscape. We also connect the technical methods to the specific prerequisites in digital pathology and present findings to guide future research efforts. The survey is intended for both technical researchers and medical professionals, one of the objectives being to establish a common ground for cross-disciplinary discussions.
A Study of Deep Learning Colon Cancer Detection in Limited Data Access Scenarios
May 22, 2020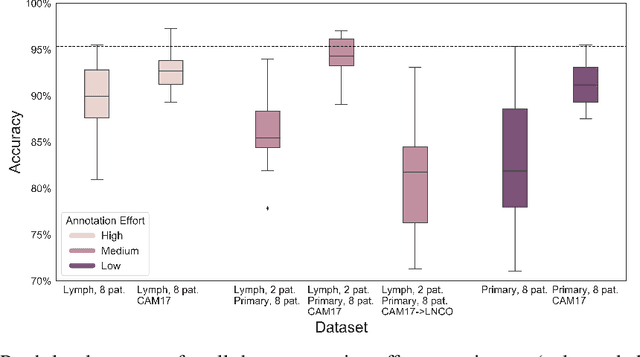
Digitization of histopathology slides has led to several advances, from easy data sharing and collaborations to the development of digital diagnostic tools. Deep learning (DL) methods for classification and detection have shown great potential, but often require large amounts of training data that are hard to collect, and annotate. For many cancer types, the scarceness of data creates barriers for training DL models. One such scenario relates to detecting tumor metastasis in lymph node tissue, where the low ratio of tumor to non-tumor cells makes the diagnostic task hard and time-consuming. DL-based tools can allow faster diagnosis, with potentially increased quality. Unfortunately, due to the sparsity of tumor cells, annotating this type of data demands a high level of effort from pathologists. Using weak annotations from slide-level images have shown great potential, but demand access to a substantial amount of data as well. In this study, we investigate mitigation strategies for limited data access scenarios. Particularly, we address whether it is possible to exploit mutual structure between tissues to develop general techniques, wherein data from one type of cancer in a particular tissue could have diagnostic value for other cancers in other tissues. Our case is exemplified by a DL model for metastatic colon cancer detection in lymph nodes. Could such a model be trained with little or even no lymph node data? As alternative data sources, we investigate 1) tumor cells taken from the primary colon tumor tissue, and 2) cancer data from a different organ (breast), either as is or transformed to the target domain (colon) using Cycle-GANs. We show that the suggested approaches make it possible to detect cancer metastasis with no or very little lymph node data, opening up for the possibility that existing, annotated histopathology data could generalize to other domains.
Classifying the classifier: dissecting the weight space of neural networks
Feb 13, 2020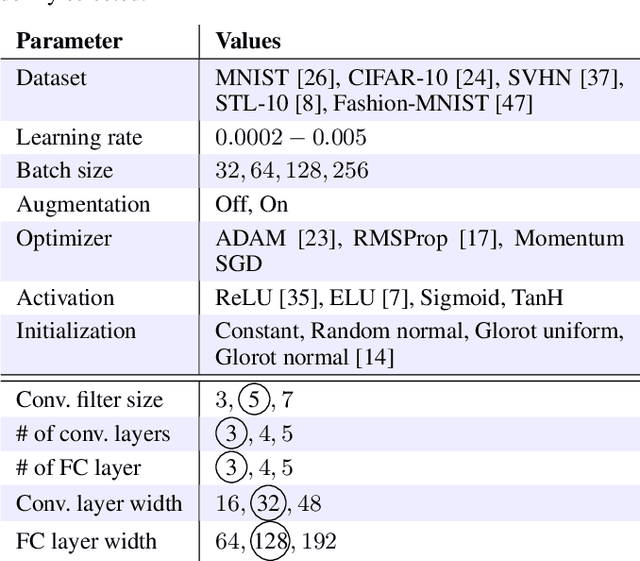
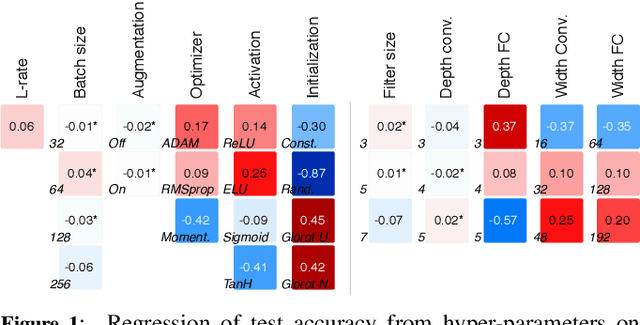
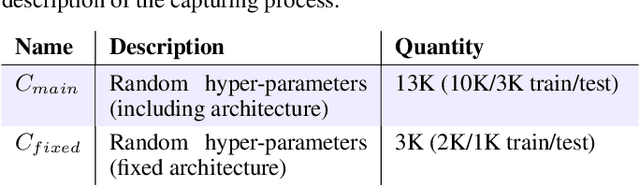
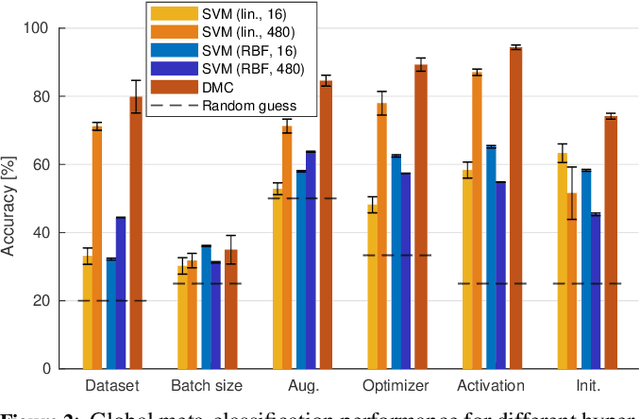
This paper presents an empirical study on the weights of neural networks, where we interpret each model as a point in a high-dimensional space -- the neural weight space. To explore the complex structure of this space, we sample from a diverse selection of training variations (dataset, optimization procedure, architecture, etc.) of neural network classifiers, and train a large number of models to represent the weight space. Then, we use a machine learning approach for analyzing and extracting information from this space. Most centrally, we train a number of novel deep meta-classifiers with the objective of classifying different properties of the training setup by identifying their footprints in the weight space. Thus, the meta-classifiers probe for patterns induced by hyper-parameters, so that we can quantify how much, where, and when these are encoded through the optimization process. This provides a novel and complementary view for explainable AI, and we show how meta-classifiers can reveal a great deal of information about the training setup and optimization, by only considering a small subset of randomly selected consecutive weights. To promote further research on the weight space, we release the neural weight space (NWS) dataset -- a collection of 320K weight snapshots from 16K individually trained deep neural networks.
A Closer Look at Domain Shift for Deep Learning in Histopathology
Sep 26, 2019

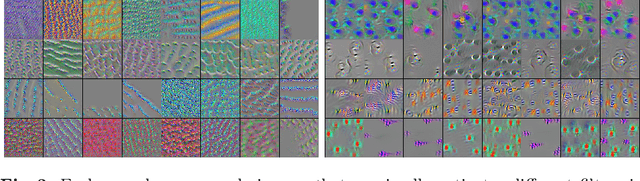
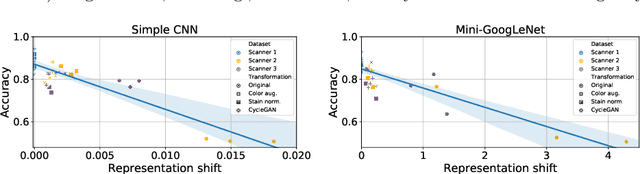
Domain shift is a significant problem in histopathology. There can be large differences in data characteristics of whole-slide images between medical centers and scanners, making generalization of deep learning to unseen data difficult. To gain a better understanding of the problem, we present a study on convolutional neural networks trained for tumor classification of H&E stained whole-slide images. We analyze how augmentation and normalization strategies affect performance and learned representations, and what features a trained model respond to. Most centrally, we present a novel measure for evaluating the distance between domains in the context of the learned representation of a particular model. This measure can reveal how sensitive a model is to domain variations, and can be used to detect new data that a model will have problems generalizing to. The results show how learning is heavily influenced by the preparation of training data, and that the latent representation used to do classification is sensitive to changes in data distribution, especially when training without augmentation or normalization.
Single-frame Regularization for Temporally Stable CNNs
Feb 27, 2019


Convolutional neural networks (CNNs) can model complicated non-linear relations between images. However, they are notoriously sensitive to small changes in the input. Most CNNs trained to describe image-to-image mappings generate temporally unstable results when applied to video sequences, leading to flickering artifacts and other inconsistencies over time. In order to use CNNs for video material, previous methods have relied on estimating dense frame-to-frame motion information (optical flow) in the training and/or the inference phase, or by exploring recurrent learning structures. We take a different approach to the problem, posing temporal stability as a regularization of the cost function. The regularization is formulated to account for different types of motion that can occur between frames, so that temporally stable CNNs can be trained without the need for video material or expensive motion estimation. The training can be performed as a fine-tuning operation, without architectural modifications of the CNN. Our evaluation shows that the training strategy leads to large improvements in temporal smoothness. Moreover, in situations where the quantity of training data is limited, the regularization can help in boosting the generalization performance to a much larger extent than what is possible with na\"ive augmentation strategies.
HDR image reconstruction from a single exposure using deep CNNs
Oct 20, 2017
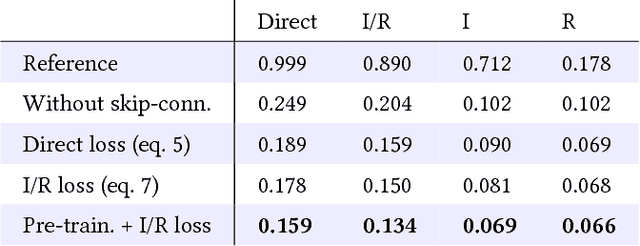
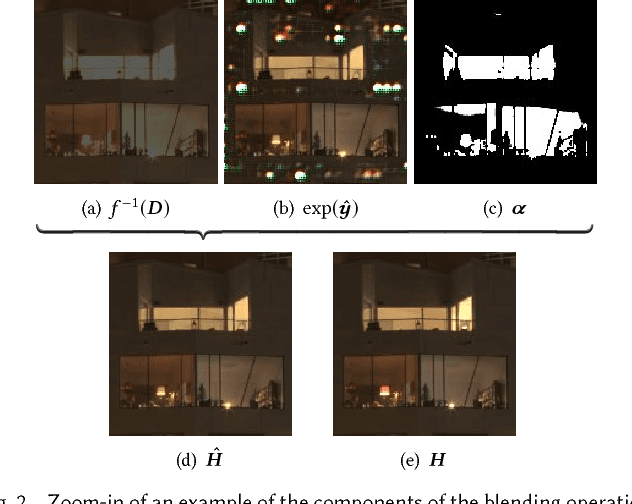
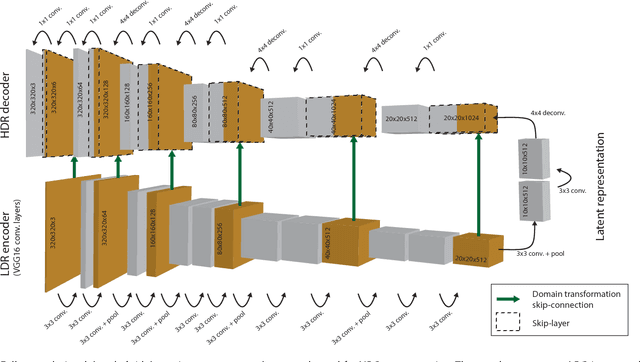
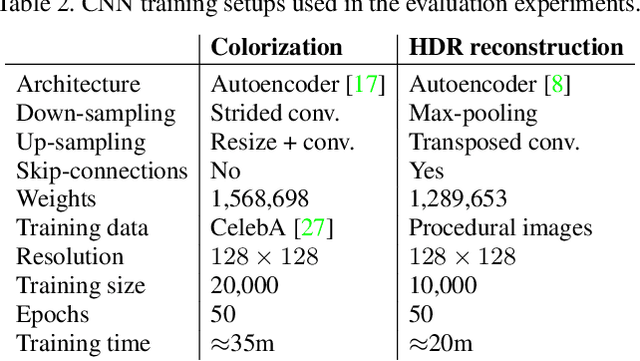
Camera sensors can only capture a limited range of luminance simultaneously, and in order to create high dynamic range (HDR) images a set of different exposures are typically combined. In this paper we address the problem of predicting information that have been lost in saturated image areas, in order to enable HDR reconstruction from a single exposure. We show that this problem is well-suited for deep learning algorithms, and propose a deep convolutional neural network (CNN) that is specifically designed taking into account the challenges in predicting HDR values. To train the CNN we gather a large dataset of HDR images, which we augment by simulating sensor saturation for a range of cameras. To further boost robustness, we pre-train the CNN on a simulated HDR dataset created from a subset of the MIT Places database. We demonstrate that our approach can reconstruct high-resolution visually convincing HDR results in a wide range of situations, and that it generalizes well to reconstruction of images captured with arbitrary and low-end cameras that use unknown camera response functions and post-processing. Furthermore, we compare to existing methods for HDR expansion, and show high quality results also for image based lighting. Finally, we evaluate the results in a subjective experiment performed on an HDR display. This shows that the reconstructed HDR images are visually convincing, with large improvements as compared to existing methods.
* 15 pages, 19 figures, Siggraph Asia 2017. Project webpage located at http://hdrv.org/hdrcnn/ where paper with high quality images is available, as well as supplementary material (document, images, video and source code)