 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs For Turkish Skill Extraction
Jan 30, 2026Skill extraction is a critical component of modern recruitment systems, enabling efficient job matching, personalized recommendations, and labor market analysis. Despite Türkiye's significant role in the global workforce, Turkish, a morphologically complex language, lacks both a skill taxonomy and a dedicated skill extraction dataset, resulting in underexplored research in skill extraction for Turkish. This article seeks the answers to three research questions: 1) How can skill extraction be effectively performed for this language, in light of its low resource nature? 2)~What is the most promising model? 3) What is the impact of different Large Language Models (LLMs) and prompting strategies on skill extraction (i.e., dynamic vs. static few-shot samples, varying context information, and encouraging causal reasoning)? The article introduces the first Turkish skill extraction dataset and performance evaluations of automated skill extraction using LLMs. The manually annotated dataset contains 4,819 labeled skill spans from 327 job postings across different occupation areas. The use of LLM outperforms supervised sequence labeling when used in an end-to-end pipeline, aligning extracted spans with standardized skills in the ESCO taxonomy more effectively. The best-performing configuration, utilizing Claude Sonnet 3.7 with dynamic few-shot prompting for skill identification, embedding-based retrieval, and LLM-based reranking for skill linking, achieves an end-to-end performance of 0.56, positioning Turkish alongside similar studies in other languages, which are few in the literature. Our findings suggest that LLMs can improve skill extraction performance in low-resource settings, and we hope that our work will accelerate similar research on skill extraction for underrepresented languages.
From Labels to Facets: Building a Taxonomically Enriched Turkish Learner Corpus
Jan 30, 2026In terms of annotation structure, most learner corpora rely on holistic flat label inventories which, even when extensive, do not explicitly separate multiple linguistic dimensions. This makes linguistically deep annotation difficult and complicates fine-grained analyses aimed at understanding why and how learners produce specific errors. To address these limitations, this paper presents a semi-automated annotation methodology for learner corpora, built upon a recently proposed faceted taxonomy, and implemented through a novel annotation extension framework. The taxonomy provides a theoretically grounded, multi-dimensional categorization that captures the linguistic properties underlying each error instance, thereby enabling standardized, fine-grained, and interpretable enrichment beyond flat annotations. The annotation extension tool, implemented based on the proposed extension framework for Turkish, automatically extends existing flat annotations by inferring additional linguistic and metadata information as facets within the taxonomy to provide richer learner-specific context. It was systematically evaluated and yielded promising performance results, achieving a facet-level accuracy of 95.86%. The resulting taxonomically enriched corpus offers enhanced querying capabilities and supports detailed exploratory analyses across learner corpora, enabling researchers to investigate error patterns through complex linguistic and pedagogical dimensions. This work introduces the first collaboratively annotated and taxonomically enriched Turkish Learner Corpus, a manual annotation guideline with a refined tagset, and an annotation extender. As the first corpus designed in accordance with the recently introduced taxonomy, we expect our study to pave the way for subsequent enrichment efforts of existing error-annotated learner corpora.
A Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
ITUNLP at SemEval-2025 Task 8: Question-Answering over Tabular Data: A Zero-Shot Approach using LLM-Driven Code Generation
Aug 01, 2025This paper presents our system for SemEval-2025 Task 8: DataBench, Question-Answering over Tabular Data. The primary objective of this task is to perform question answering on given tabular datasets from diverse domains under two subtasks: DataBench QA (Subtask I) and DataBench Lite QA (Subtask II). To tackle both subtasks, we developed a zero-shot solution with a particular emphasis on leveraging Large Language Model (LLM)-based code generation. Specifically, we propose a Python code generation framework utilizing state-of-the-art open-source LLMs to generate executable Pandas code via optimized prompting strategies. Our experiments reveal that different LLMs exhibit varying levels of effectiveness in Python code generation. Additionally, results show that Python code generation achieves superior performance in tabular question answering compared to alternative approaches. Although our ranking among zero-shot systems is unknown at the time of this paper's submission, our system achieved eighth place in Subtask I and sixth place in Subtask~II among the 30 systems that outperformed the baseline in the open-source models category.
Citation Recommendation on Scholarly Legal Articles
Nov 10, 2023Citation recommendation is the task of finding appropriate citations based on a given piece of text. The proposed datasets for this task consist mainly of several scientific fields, lacking some core ones, such as law. Furthermore, citation recommendation is used within the legal domain to identify supporting arguments, utilizing non-scholarly legal articles. In order to alleviate the limitations of existing studies, we gather the first scholarly legal dataset for the task of citation recommendation. Also, we conduct experiments with state-of-the-art models and compare their performance on this dataset. The study suggests that, while BM25 is a strong benchmark for the legal citation recommendation task, the most effective method involves implementing a two-step process that entails pre-fetching with BM25+, followed by re-ranking with SciNCL, which enhances the performance of the baseline from 0.26 to 0.30 MAP@10. Moreover, fine-tuning leads to considerable performance increases in pre-trained models, which shows the importance of including legal articles in the training data of these models.
Gamified Crowdsourcing for Idiom Corpora Construction
Feb 01, 2021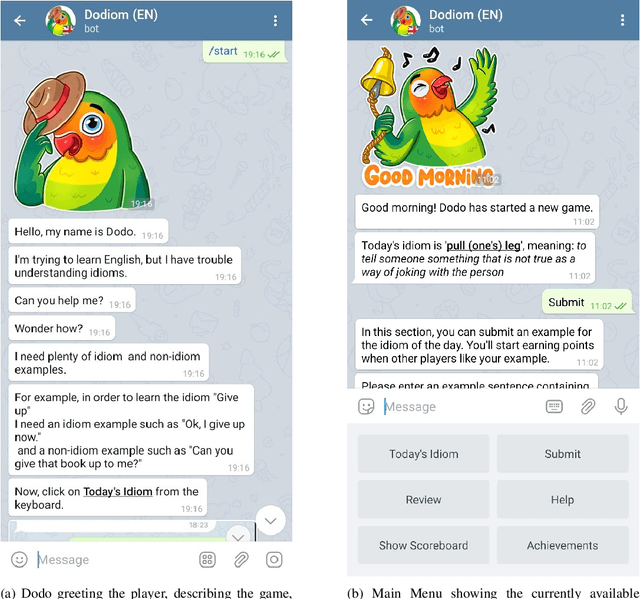
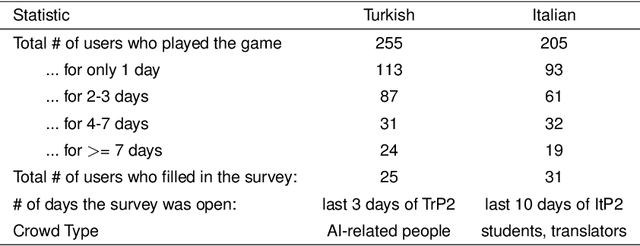
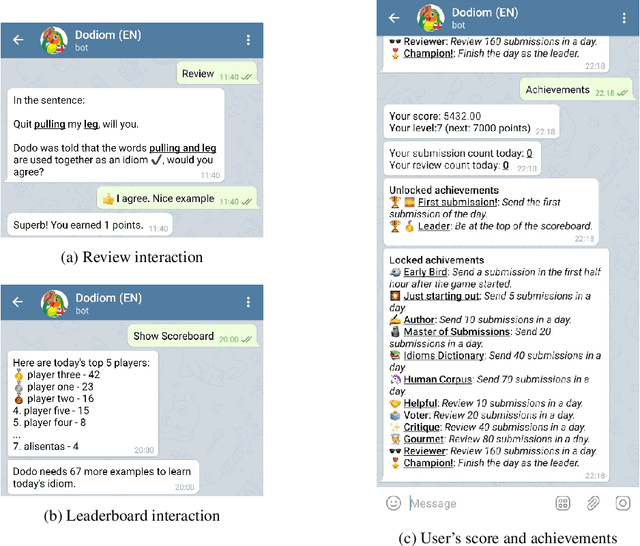
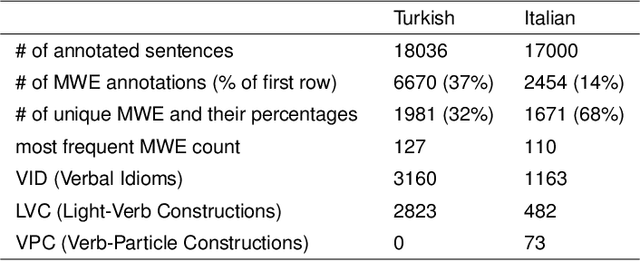
Learning idiomatic expressions is seen as one of the most challenging stages in second language learning because of their unpredictable meaning. A similar situation holds for their identification within natural language processing applications such as machine translation and parsing. The lack of high-quality usage samples exacerbates this challenge not only for humans but also for artificial intelligence systems. This article introduces a gamified crowdsourcing approach for collecting language learning materials for idiomatic expressions; a messaging bot is designed as an asynchronous multiplayer game for native speakers who compete with each other while providing idiomatic and nonidiomatic usage examples and rating other players' entries. As opposed to classical crowdprocessing annotation efforts in the field, for the first time in the literature, a crowdcreating & crowdrating approach is implemented and tested for idiom corpora construction. The approach is language independent and evaluated on two languages in comparison to traditional data preparation techniques in the field. The reaction of the crowd is monitored under different motivational means (namely, gamification affordances and monetary rewards). The results reveal that the proposed approach is powerful in collecting the targeted materials, and although being an explicit crowdsourcing approach, it is found entertaining and useful by the crowd. The approach has been shown to have the potential to speed up the construction of idiom corpora for different natural languages to be used as second language learning material, training data for supervised idiom identification systems, or samples for lexicographic studies.