 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese sensorimotor and embodiment norms for 3,000 lexicalized concepts
May 21, 2026Understanding how conceptual knowledge is grounded in bodily experience, and to what extent machine systems can acquire such knowledge without direct sensorimotor experience, are central questions in both cognitive science and embodied artificial intelligence research. Large-scale normative resources are essential for investigating these questions empirically, yet such resources remain sparse for non-Indo-European languages. We present a novel normative database for 3,000 lexicalized concepts in Mandarin Chinese, comprising 11-dimensional sensorimotor ratings and unidimensional embodiment ratings collected from 378 native Mandarin speakers. The ratings demonstrate high reliability and strong cross-norm validity with existing Chinese resources, each of which covers fewer words and a subset of the 11 sensorimotor dimensions. In a validation study, we tested new variables derived from a theoretically motivated metric, Perceptual Strength of Embodiment (PSE) (Huang et al., 2025), together with seven common composite variables, on lexical decision tasks. The results suggest that PSE-Sensorimotor and Minkowski-3 are the strongest composite predictors of lexical decision performance, capturing the facilitatory effects of sensorimotor information on lexical processing. A further exploratory study showed that sensorimotor ratings are substantially recoverable from purely linguistic representations using simple regression models (mean Spearman r = .62 across dimensions), though recovery varied markedly: visual and auditory dimensions yielded higher correspondence than chemosensory ones. Representational similarity analysis further showed that the relational geometry of the sensorimotor space is also partially recoverable (r = .540), consistent with the view that distributional language use encodes aspects of embodied conceptual structure.
Predicting gender and age categories in English conversations using lexical, non-lexical, and turn-taking features
Feb 26, 2021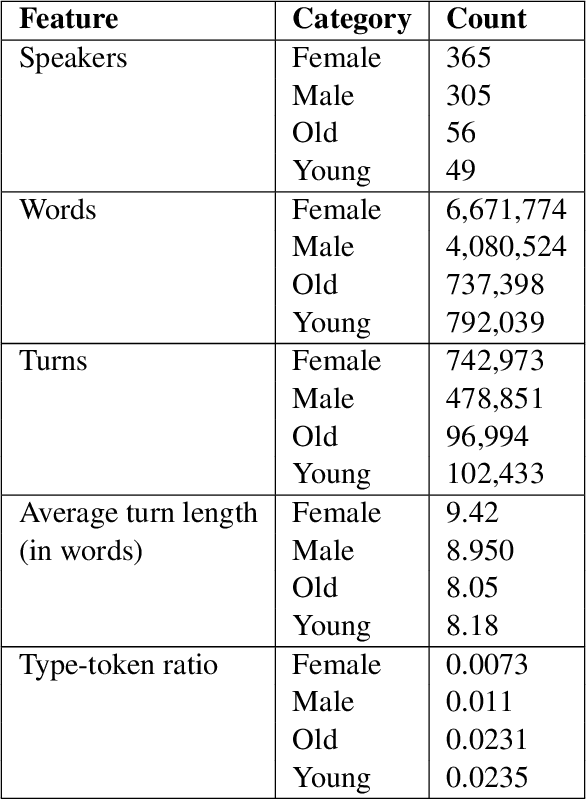
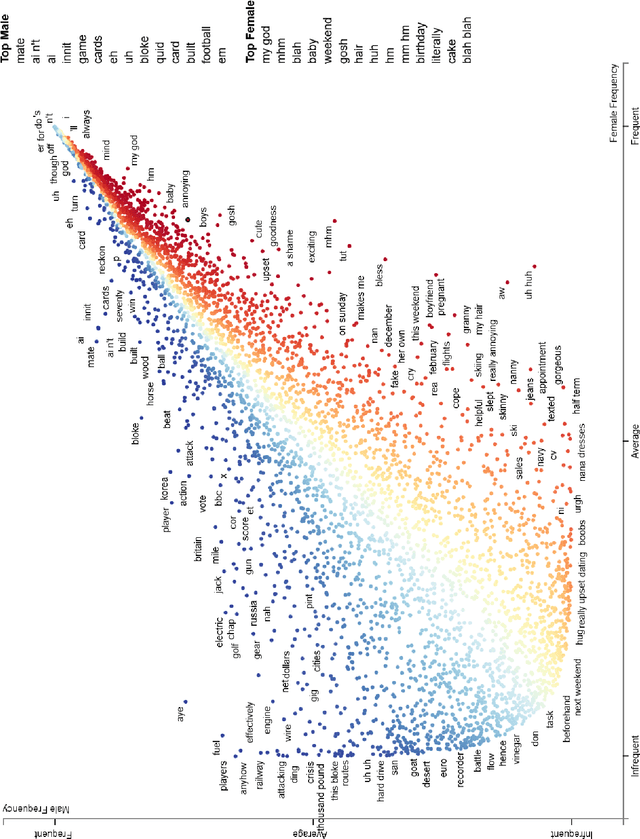
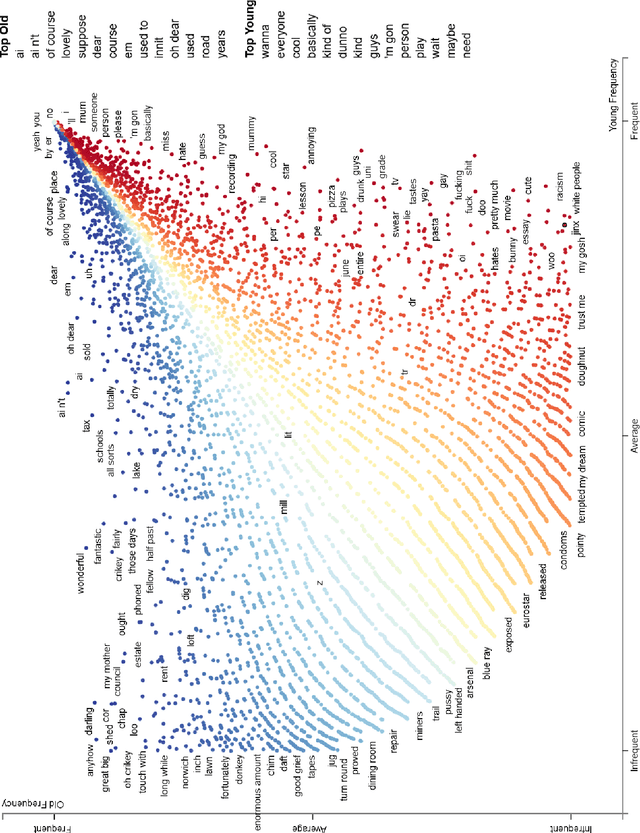
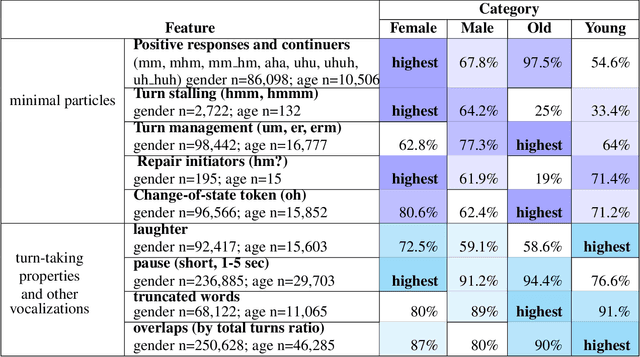
This paper examines gender and age salience and (stereo)typicality in British English talk with the aim to predict gender and age categories based on lexical, phrasal and turn-taking features. We examine the SpokenBNC, a corpus of around 11.4 million words of British English conversations and identify behavioural differences between speakers that are labelled for gender and age categories. We explore differences in language use and turn-taking dynamics and identify a range of characteristics that set the categories apart. We find that female speakers tend to produce more and slightly longer turns, while turns by male speakers feature a higher type-token ratio and a distinct range of minimal particles such as "eh", "uh" and "em". Across age groups, we observe, for instance, that swear words and laughter characterize young speakers' talk, while old speakers tend to produce more truncated words. We then use the observed characteristics to predict gender and age labels of speakers per conversation and per turn as a classification task, showing that non-lexical utterances such as minimal particles that are usually left out of dialog data can contribute to setting the categories apart.