 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Urban Sound Information for Residential Areas in Smart Cities Using an End-to-End IoT System
Aug 11, 2024



With rapid urbanization comes the increase of community, construction, and transportation noise in residential areas. The conventional approach of solely relying on sound pressure level (SPL) information to decide on the noise environment and to plan out noise control and mitigation strategies is inadequate. This paper presents an end-to-end IoT system that extracts real-time urban sound metadata using edge devices, providing information on the sound type, location and duration, rate of occurrence, loudness, and azimuth of a dominant noise in nine residential areas. The collected metadata on environmental sound is transmitted to and aggregated in a cloud-based platform to produce detailed descriptive analytics and visualization. Our approach to integrating different building blocks, namely, hardware, software, cloud technologies, and signal processing algorithms to form our real-time IoT system is outlined. We demonstrate how some of the sound metadata extracted by our system are used to provide insights into the noise in residential areas. A scalable workflow to collect and prepare audio recordings from nine residential areas to construct our urban sound dataset for training and evaluating a location-agnostic model is discussed. Some practical challenges of managing and maintaining a sensor network deployed at numerous locations are also addressed.
* 13 pages, 15 figures, journal
Deployment of an IoT System for Adaptive In-Situ Soundscape Augmentation
Apr 29, 2022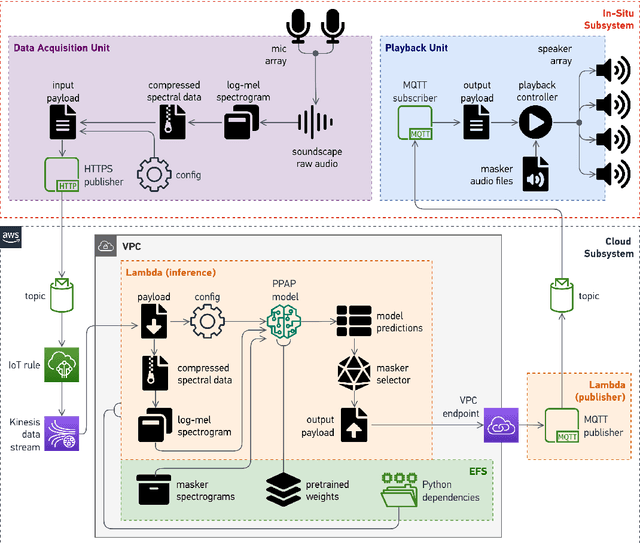
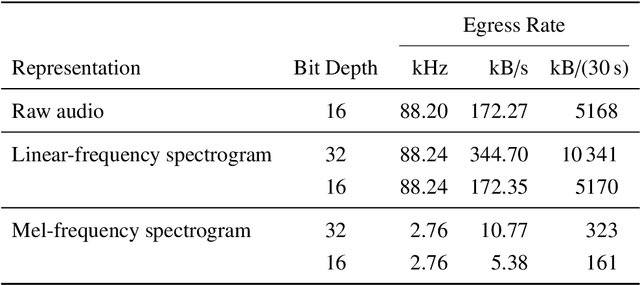
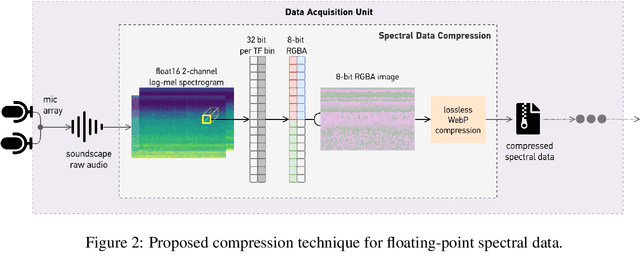
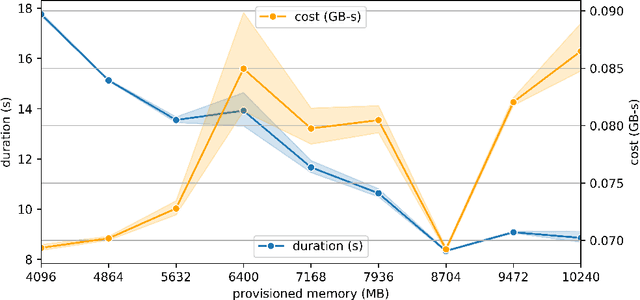
Soundscape augmentation is an emerging approach for noise mitigation by introducing additional sounds known as "maskers" to increase acoustic comfort. Traditionally, the choice of maskers is often predicated on expert guidance or post-hoc analysis which can be time-consuming and sometimes arbitrary. Moreover, this often results in a static set of maskers that are inflexible to the dynamic nature of real-world acoustic environments. Overcoming the inflexibility of traditional soundscape augmentation is twofold. First, given a snapshot of a soundscape, the system must be able to select an optimal masker without human supervision. Second, the system must also be able to react to changes in the acoustic environment with near real-time latency. In this work, we harness the combined prowess of cloud computing and the Internet of Things (IoT) to allow in-situ listening and playback using microcontrollers while delegating computationally expensive inference tasks to the cloud. In particular, a serverless cloud architecture was used for inference, ensuring near real-time latency and scalability without the need to provision computing resources. A working prototype of the system is currently being deployed in a public area experiencing high traffic noise, as well as undergoing public evaluation for future improvements.
A Strongly-Labelled Polyphonic Dataset of Urban Sounds with Spatiotemporal Context
Nov 11, 2021
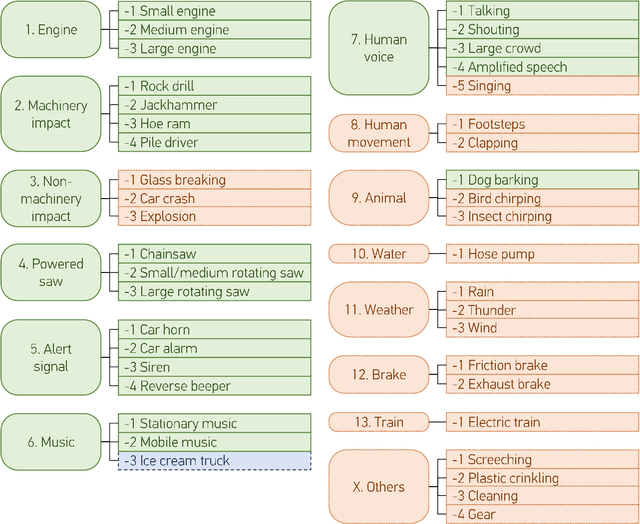
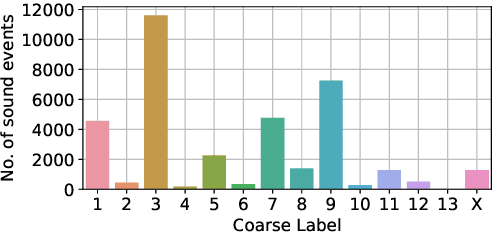
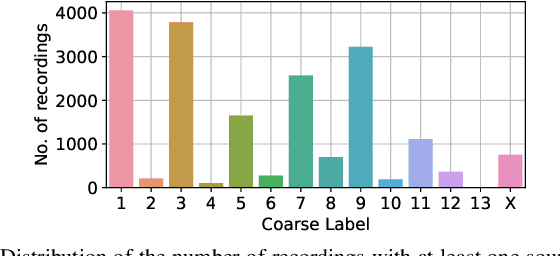
This paper introduces SINGA:PURA, a strongly labelled polyphonic urban sound dataset with spatiotemporal context. The data were collected via several recording units deployed across Singapore as a part of a wireless acoustic sensor network. These recordings were made as part of a project to identify and mitigate noise sources in Singapore, but also possess a wider applicability to sound event detection, classification, and localization. This paper introduces an accompanying hierarchical label taxonomy, which has been designed to be compatible with other existing datasets for urban sound tagging while also able to capture sound events unique to the Singaporean context. This paper details the data collection, annotation, and processing methodologies for the creation of the dataset. We further perform exploratory data analysis and include the performance of a baseline model on the dataset as a benchmark.